








・
GPT-4oとGPT5.1を比較!どちらを使うべきかポイントをご紹介

生成AIのビジネス活用が急速に進む中、多くの企業で導入検討が進んでいるのがOpenAI社の「ChatGPT」です。特に昨今では、「GPT-4o」や「GPT-5.1」など、用途に特化したモデルが次々と登場しています。しかし、選択肢が増えたことで「自社の業務にはどのモデルが最適なのか」「コストと精度のバランスはどう判断すべきか」と頭を悩ませるDX担当者も少なくありません。
本記事では複数モデルの特徴を整理し、実際の業務フローを想定した比較検証を行います。
【ChatGPTについて活用事例を紹介した記事はこちら!】
【現場で使えるChatGPT活用事例8選!】検証して分かった業務効率化のコツとは?
ChatGPTでのレポート作成を完全攻略!プロンプト例とDeep Research活用術
✍️ChatGPTのモデルについて
本記事の想定読者
本記事は、以下のような悩みや目的をお持ちの方に役立つ内容となっています。
- 業務効率化のために、自社に最適な生成AIモデルの選定・比較検証を任されている企業のDX推進担当者の方
- GPT-5.1と、従来のGPT-4o等の性能差や使い分けの基準を具体的に知りたい方
- 複数のAIモデルを比較検証する際の手間や環境構築の工数を削減し、効率的にテストを行いたい方
GPT-5.1の特徴
現在のChatGPTは、マルチモーダル対応テキストだけでなく、画像、音声、動画、プログラムコードなど多様なデータの解析や生成に対応しています。ただし、動画や音声の解析に関しては、現時点では一部機能に制限がある場合があります。
- 高度な推論とルーター機能
ユーザーの質問内容に応じて、瞬時の回答が得意なモデル(Instant)や、論理的思考に強いモデル(Thinking/o3)を自動または手動で切り替えることが可能です。
- 信頼性の向上
課題であったハルシネーション(もっともらしい誤情報)の発生が低減され、特にGPT-5系やo3系では、事実確認が求められる業務において信頼性が向上しています。ただし、完全に誤情報が排除されたわけではなく、最終的な判断はユーザーによる確認が推奨されます。
- 大規模コンテキスト
大規模な社内ドキュメントやマニュアルの読み込みと、それに基づく回答生成が可能です。しかしながら、システムのパフォーマンスにはタスクごとに違いが生じる場合があります。
⭐生成AI×Yoomで、AIをもっと「実務」へ生かしてみませんか
AIはチャットでプロンプトを投げるだけでも有力なツールとなるものの「出力結果をチャットツールやデータベースに入力する」といったような手作業が発生し、業務全体の効率化には限界があるもの。そこで便利なのが、自動化ツール「Yoom」です!AIと700以上のアプリを連携し、あなたの業務を自動化します。
[Yoomとは]
👉利用社数4万社以上!YoomのAIエージェント機能についてまとめたサービス紹介資料はこちら
🤔GPT5.1を実際に使ってみた
ここでは、ビジネス現場で実際に発生する業務シーンを想定し、ChatGPTの各モデルをどのように活用・検証できるかのシナリオを提示します。
検証条件
検証に使用したモデルは以下のとおりです。
- 使用モデル:GPT-5.1 Thinking、GPT-5.1 Instant、GPT-4o
検証内容とポイント
検証1:業務委託契約書(甲=委託者側)を読み込ませ、不利な条項やリスクを洗い出す

※マーカー部分が委託者(甲)に不利な条項と修正すべき点です
実務で頻繁に発生する「契約書のリーガルチェックとリスク抽出」をテーマに、2つのモデルの実力を比較検証しました。
【検証条件】
- リスク検知の網羅性
- 修正案の具体性
- 論理的正確性
- 出力のスタイル
【検証で使うプロンプト】
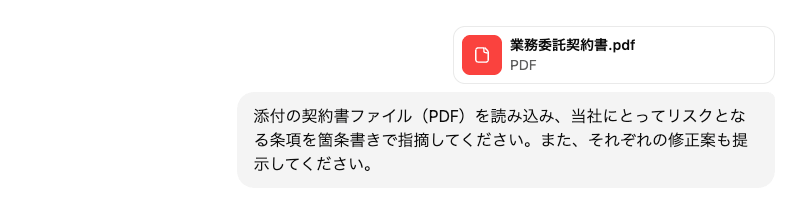
添付の契約書ファイル(PDF)を読み込み、当社にとってリスクとなる条項を箇条書きで指摘してください。また、それぞれの修正案も提示してください。
検証2:仕事での失敗を相談するユーザーに対し、それぞれのモデルがどのような構成、トーン、アドバイスで応答するかを比較

仕事でミスをして落ち込んでしまったときに、AIがどのような言葉をかけ、どうサポートしてくれるのかを検証しました。
【検証条件】
- 共感度/フレンドリーさ
- 行動計画の視認性
- 実務的なアドバイス
- 全体の構成
【検証で使うプロンプト】
私は仕事で大きなミスをしてしまい、とても落ち込んでいます。次に何をすればいいか分かりません。私の気持ちに寄り添い、「フレンドリー」なトーンで具体的な行動案を提案してください。
検証方法
検証は、以下の手順で行います。
1.ChatGPTアカウントにログイン
2.ChatGPTのモデルを選択
3.プロンプトを入力して検証開始
✅検証結果1:契約書のリーガルチェックとリスク抽出

結論からお伝えすると、契約書のリーガルチェックとリスク抽出においては、無料版でも利用可能なGPT-4oのほうが網羅性と具体性が高く、実務的な修正案を提示できているという結果になりました。
一方、GPT-5.1 Thinkingは要点を絞った指摘が得意なものの、一部の重要なリスクを見逃す傾向がありました。
以下にそれぞれの評価をまとめます。
GPT-5.1 Thinkingの評価

【総評】
重要なコアリスクに絞った、エグゼクティブサマリーのような出力です。
【メリット】
- 重要論点への集中(ノイズが少ない)
「第4条 権利帰属」「第6条 再委託」「第7条 損害賠償」という、ビジネスにおいて特に致命傷となりうる3つの主要リスクだけをピンポイントで抽出しています。
- リスクの理由が明確
再委託について「業務の質が保証されなくなる」「甲が直接的に対応できない」といった、ビジネス上の具体的な懸念点を簡潔に言語化しています。法的な正しさだけでなく、ビジネスへの影響を重視した解説です。
【デメリット】
- 指摘漏れがある
契約管理において重要な「自動更新条項」のリスクをスルーしています。これを見逃すと、解約したいときに解約できないトラブルにつながりかねません。
- 修正案が「指示」止まり
「甲の承諾を得ることを義務化し…条項を追加」といった方針を示すのみで、具体的な条文テキストを生成していません。具体的な文言はユーザー自身が考える必要があります。
GPT-4o の評価

【総評】
網羅的なリスク検知と、具体的な「書き換え案」の提示に優れています。
【メリット】
- リスク検知の網羅性が高い(5項目検出)
GPT-5.1が見逃してしまった「第2条 自動更新(予期せぬ契約更新)」のリスクを指摘できています。意図せず契約が更新され、不要な費用が発生するリスクを防げる点は大きいです。
また、「第5条 秘密保持」についても言及しており、より多くの条項を漏れなくチェックできていました。
- 「修正条文案」が具体的
単なるアドバイスにとどまらず、「契約終了の意向を示す場合は、期間満了の30日前までに…」といった、そのままコピペして契約書に反映できる具体的な修正文言を提示しています。ユーザーが自分で条文を書き直す手間が削減されます。
【デメリット】
- 文脈理解の誤り(論理エラー)に注意
「第5条 秘密保持」について、「3ヶ月間に短縮すべき」という提案をしていました。本来、情報を開示する側(甲)としては、秘密保持期間は長いほうが有利ですが、このように自社の利益と逆行する誤ったアドバイスが含まれることがあるため、盲信は禁物です。
- 記述が長く、情報の選別が必要
指摘項目が多岐にわたるため、重要な「損害賠償」などのリスクと、判断が分かれる「秘密保持期間」などのリスクが並列で扱われています。優先順位の判断は人間に委ねられます。
使ってみて感じたこと
GPT-4oは細かな気づきを与えてくれますが、最終的なジャッジは人間が行う必要があります。
- GPT-4o:契約書全体の網羅的なチェックを行い、具体的な修正条文まで作成してほしい場合。
ただし、提示された内容が自社の利益に合致しているか、論理的な確認は必須。 - GPT-5.1 Thinking:時間がない中で、契約書の「主要な急所」だけをざっくりと把握したい場合。
契約書業務の効率化を目指す法務担当者やフリーランスの方は、まずGPT-4oで全体をチェックし、重要な論点整理にGPT-5.1 Thinkingを活用するといった二刀流も検討してみてください。
✅検証結果2:個別配慮のコミュニケーション

出力されたテキストを読み比べると、両者のアプローチには明確な違いが現れました。
GPT-5.1 Instantは感情面への深いアプローチと具体的な改善策を混ぜ込むスタイルであり、GPT-4oは情報を整理して安心感を与えるスタイルです。
それぞれの特徴を詳しく分析します。
GPT-5.1 Instant の評価

【総評】
GPT-5.1 Instantは、感情への寄り添いが深く、具体的な業務改善のアドバイスを含んでいる点が強みです。ただし、行動案が箇条書きになっていないため、情報の整理という点ではやや劣ります。
【メリット】
- 共感表現が豊かで深い
「まずはその気持ち、すごくわかります」「仕事でのミスって、誰にでもあることだけど、それでも落ち込んでしまいますよね」といった、より感情に深く寄り添う表現から入り、心のケアを最優先しています。
- 具体的な業務改善のヒントがある
「今後同じミスを繰り返さないために、チェックリストを作るとか、進捗をこまめに報告するといった方法が役立ちます」と、具体的な実務レベルの改善策を提案しています。
- 自己肯定を促すメッセージ
「まず最初にやるべきは、自分を責めないことです」と、自己肯定を促すメッセージを冒頭に配置しており、心理的サポートの意識が高いです。
【デメリット】
- 行動案の視認性が低い
行動案が番号や箇条書きで整理されておらず、段落形式で連続して書かれています。そのため、ユーザーが「すぐに実行すべきこと」を瞬時に見つけ出しにくいです。
- 構成がやや散漫
「自分を責めない」「ミスを整理」など、行動ステップが明確に区切られていません。内容がやや重複して感じられ、GPT-4oに比べると論理的な構成が整理されていません。
GPT-4o の評価

【総評】
GPT-4oは、混乱しているユーザーを論理的にサポートする能力に長けています。落ち着いたトーンで共感を示しつつ、体系的かつ実行しやすい5つの行動ステップを提示しました。
【メリット】
- 行動案が体系的で分かりやすい
行動案が「ミスを冷静に振り返る」「関係者に素直に謝罪する」といった番号付きの箇条書きで提示されています。ユーザーは次に何をすべきか、ステップを追って把握しやすいです。
- バランスの取れた行動提案
「謝罪」や「振り返り」といった現実的な問題解決だけでなく、「小さな目標を設定する」「休憩を取る」といった精神的なケアも網羅しており、バランスが良いです。
- 親しみやすく、圧迫感のないトーン
「自分を責めすぎず」「焦らず、まずは自分に優しく」といった、優しさと落ち着きを感じさせるトーンで終始一貫しています。ユーザーの心理的な負担を軽減します。
【デメリット】
- 実務的な具体例が少ない
行動案が「冷静に振り返る」「謝罪する」など、普遍的・精神的な内容に集中しています。具体的な業務改善策のヒント(例:チェックリスト、報告の頻度など)は含まれていません。
使ってみて感じたこと
今回の検証では、「情緒と具体策のGPT-5.1 Instant」と「整理整頓のGPT-4o」という個性の違いが見えました。
落ち込みが激しく誰かに寄り添ってほしい、あるいは具体的な再発防止策(チェックリスト作成など)のヒントまで欲しいという場合は、GPT-5.1 Instantが最適です。
一方で、心が混乱してパニック状態にあり、まずは順序立てて何をすべきかを知りたい場合は、GPT-4oが適しています。
🚩ChatGPTはYoomで使えます
ChatGPTは単体チャットでももちろん有力なツールですが、自動化ツール Yoomと連携させることでAI生成後のアウトプットの共有や連携も効率化できます。AI活用のその先の実務を自動化したい方は、ぜひチェックしてみてください!👀
👉毎月20時間以上の工数削減に成功!Yoom導入事例集のダウンロードはこちら
🖊️検証結果まとめ
今回の検証で、モデル選択の鍵は「タスクの性質」であることが裏付けされたように感じます。
契約書チェックのような網羅性と具体性が求められる実務では、GPT-4oが修正条文案まで生成し、即戦力となりました。ただし、自社に不利な修正を提案する論理エラーには注意が必要という結果です。
一方、GPT-5.1は、Thinkingが重要論点への集中、Instantが深い共感と実務ヒントというように特化型の強みを発揮しています。
したがって、GPT-4oでは網羅的にベースを作成し、GPT-5.1で論点整理や対話を行う「二刀流」が、最も効率的な活用法といえるでしょう。
プログラミング知識なしで手軽に構築できます。



