








・
ElevenLabsの日本語性能を検証|ナレーションの作成から判断する利用時のポイント

本記事では、自然な音声を作成できるAIツールとして知られるElevenLabsの日本語対応状況や、読み上げの精度を高めるためのテクニックを詳しく解説します。音声生成AIを活用する際、意図した通りのイントネーションや間(ポーズ)を作り出すことは課題の一つですが、いくつかの設定を工夫するだけで品質が向上しやすくなります。工夫の有無で、どう変わるかを実際に試した比較結果も紹介するため、ぜひ参考にしてみてください。
✍️ElevenLabsとは?日本語対応の状況や対応モデル

ここでは、ElevenLabsがどのようなツールであるか、また日本語対応の現状やモデルごとの違いについて解説します。
ElevenLabsの基本概要
ElevenLabsは、テキストから自然な音声を生成する「Text to Speech」や、既存の音声を学習して別の声を再現する「ボイスクローニング」機能を提供する音声生成AIプラットフォームです。言語の壁を越えた多様な音声作成が可能であり、個人から企業まで幅広いユーザーに活用されています。主な特徴は以下の通りです。- 多言語対応:
70以上の言語に対応しており、グローバルなコンテンツ制作に適しています。 - 商用利用の許可:
有料プランに加入することで、生成した音声を商用目的で利用できます。 - API/Agents向けの従量課金:
APIを経由した大規模な音声生成や、AIエージェントへの組み込み用途にも対応し、使用量に応じた柔軟な課金体系が用意されています。
個人利用の動画ナレーション作成から、企業のカスタマーサポート自動化まで、用途に合わせて柔軟に活用できる点が大きな強みです。
ElevenLabsの機能別日本語対応状況
ElevenLabsが提供する各種機能において、日本語に対応しているかどうかを以下にまとめました。基本的には多くの機能で日本語が利用可能ですが、機能によっては英語でのプロンプト入力が推奨される場合があります。- Text to Speech:対応済み。ただし、選択するモデルによっては非対応の場合あり。
- Speech to Text:対応済み。
- Dubbing(吹き替え):対応済み。日本語と他言語間の相互吹き替えを利用可能。
- Voice Changer:対応済み。
- Voice Isolator:言語非依存の機能であるため、日本語の音声データでも問題なく利用可能。
- Sound Effects:対応済み。ただし、英語での指示の方が安定して意図した効果音を生成可能。
- Music:簡単な日本語の指示には対応済み。詳細なニュアンスを指定したい場合は英語プロンプトが推奨。
- Image & Video:対応済み。ただし、選択するモデルによっては英語でのプロンプト入力が推奨。
日本語対応モデルとボイス・出力フォーマットの選択
ElevenLabsの「Text to Speech」機能で日本語を読み上げさせる場合、適切なモデルの選択が重要です。ElevenLabsには複数のAIモデルが存在し、それぞれ得意な処理や対応言語が異なります。ここでは、日本語に対応している主要なモデルの特徴を解説します。🔷 日本語対応モデルの特徴
- Eleven v3:
日本語のイントネーションや漢字の読みに対応し、感情表現や対話表現の豊かさに優れたモデルです。感情の起伏を表現したい場合に適しています。 - Eleven Multilingual v2:
多言語対応の大規模モデルで、長文読み上げ時の安定性が高いとされています。数字や記号を文脈に合わせて正規化して読み上げる能力にも長けています。 - Eleven Flash v2.5:
処理速度と軽量さを重視したモデルです。リアルタイム性が求められる用途に向いていますが、数字や記号はテキスト通りにそのまま読み上げる傾向があります。 - Eleven Turbo v2.5:
高速なレスポンス向けの旧モデルです。現在は公式に非推奨(Deprecated)扱いとなっており、同等機能のFlash v2.5の利用が推奨されています。
※なお、ElevenLabsには「Eleven English v1」や「Eleven Turbo v2」「Eleven Flash v2」など、日本語に非対応(英語専用など)のモデルも存在します。これらを選択した状態で日本語を入力すると、正しく読み上げられないため注意が必要です。
🔷ボイスの選択と出力フォーマット
「Text to Speech」機能では、さまざまなボイスモデルが用意されており、シーンに応じて使い分けることが可能です。フィルタリング機能も用意されており、「言語」「アクセント」「性別」などの項目で絞ることで、スムーズに選択できます。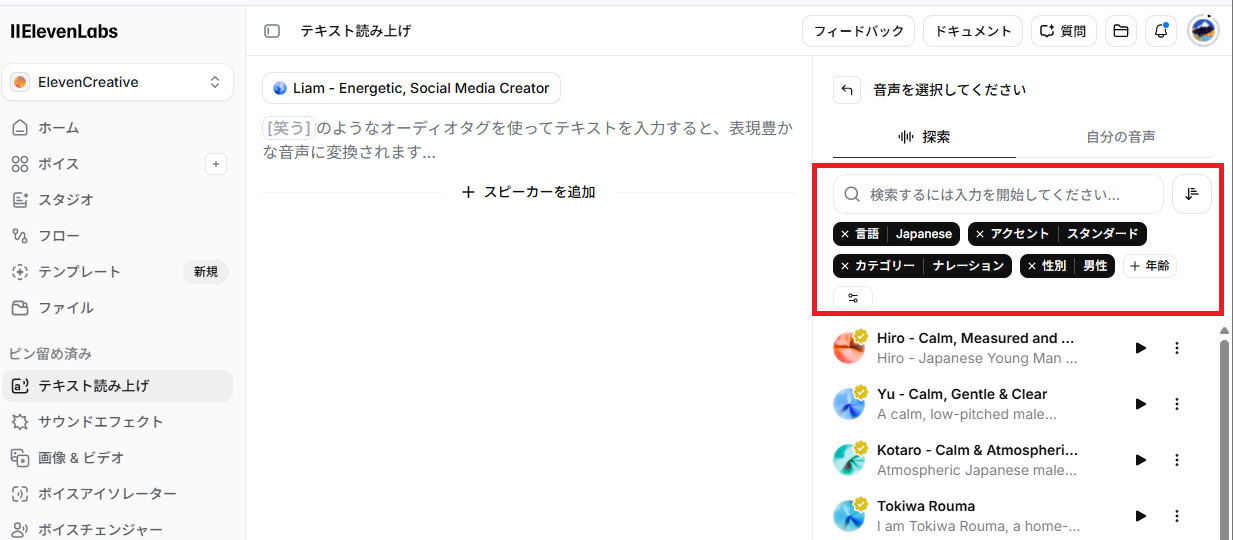
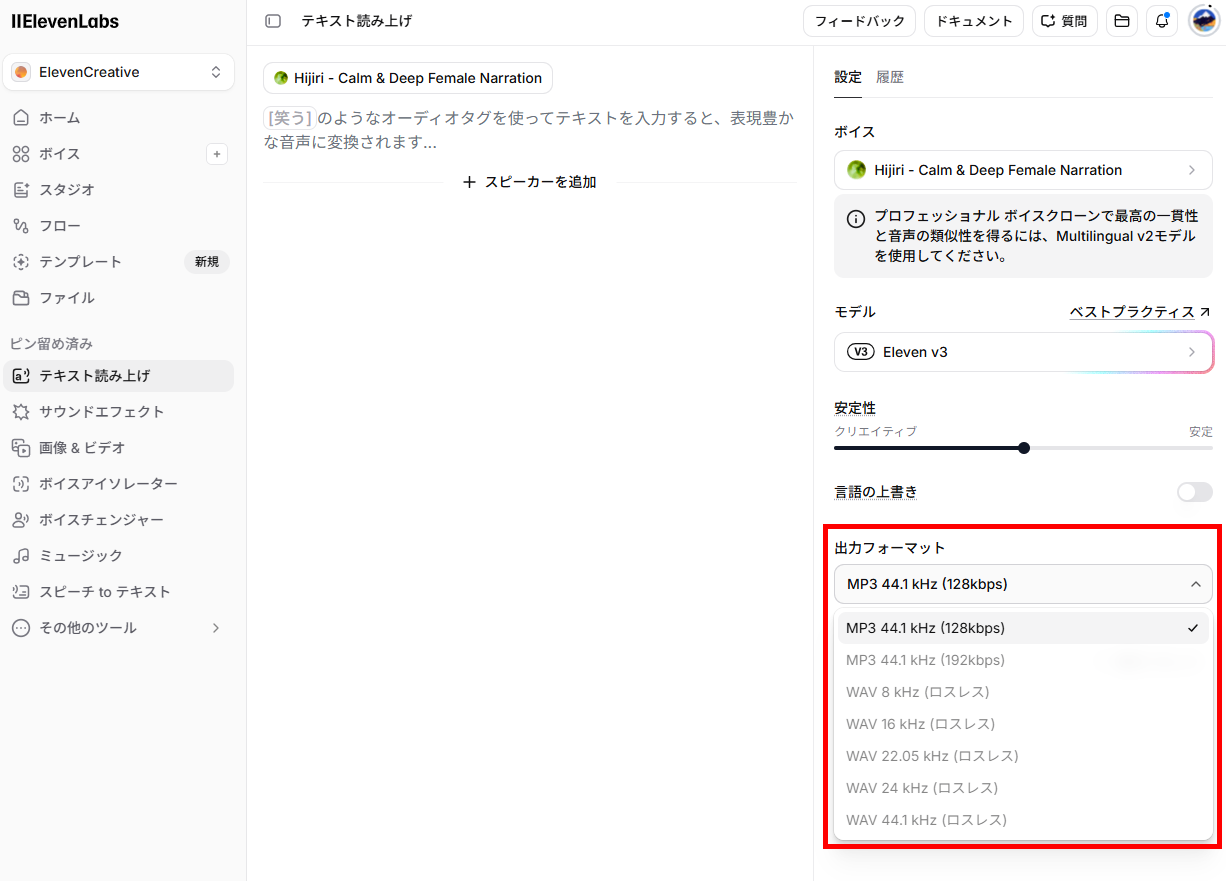
音声を生成する際には、出力フォーマットを選べます。用途に合わせて「MP3」や「WAV」形式などから選択でき、品質とファイルサイズのバランスを調整可能です。
⭐Yoomは音声生成に関する業務全体を自動化できます
ElevenLabsは、テキストから音声を自動作成できる優れたツールです。しかし、効率化できるのは、業務全体の一部ではないでしょうか。音声を作成する前の台本のリサーチにはじまり、テキストの作成、そして作成されたファイルの保存といった作業は依然として手作業になります。Yoomを使えば、リサーチから音声作成、そしてストレージへの保存までのすべてのプロセスを自動化できます。[Yoomとは]
Yoomを利用することで、リサーチや台本作成に追われている担当者の負担が軽減し、同じ時間でより多くの音声ファイルを作成できるようになります。ノーコードで設定でき、すぐに導入できるので、まずは以下のようなテンプレートを試して、業務全体が自動化される環境を体験してみてください。
- Slackでメッセージが送信されたら、AIワーカーで投稿内容の文脈を分析しElevenLabsでナレーションの原案を作成する
- Inoreaderでコンテンツが公開されたら、AIワーカーでポッドキャスト用にElevenLabsで変換しGoogle Driveにアップロードする
- Slackの投稿内容を元に、手軽に音声コンテンツを制作したいと考えている方
- ElevenLabsなどをの操作をAIエージェントを活用して自動化することに関心がある方
- 日々の情報発信やコンテンツ制作の効率化を目指しているマーケティング担当者の方
- Slackへの投稿をきっかけにAIが自動で原稿を作成するため、手作業での原稿起こしの手間を省き、音声コンテンツ制作にかかる時間を短縮できます。
- 原稿作成から音声合成まで、一連の制作フローが自動化されるため、担当者による品質のばらつきを防ぎ、業務の標準化に繋がります。
- はじめに、Slack、Google Drive、ElevenLabsをYoomと連携します。
- 次に、トリガーでSlackを選択し、「メッセージがチャンネルに投稿されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを設定し、Slackの投稿内容の文脈を分析してナレーション原稿を生成したうえで、ElevenLabsで音声化しGoogle Driveへ保存するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Slackのトリガー設定では、通知を検知するチャンネルや、特定のキーワードが含まれる投稿のみを対象にするなど、任意で条件を設定してください。
- AIワーカーに与える指示(プロンプト)は、生成したいナレーションのトーン&マナーに合わせて自由にカスタマイズが可能です。
- ElevenLabsで音声を作成する際のボイスID(話者)や、生成された音声ファイルを保存するGoogle Driveのフォルダは任意で設定してください。
- Slack、Google Drive、ElevenLabsのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- Inoreaderで収集した情報をもとに、ポッドキャストなどの音声コンテンツを効率的に制作したい方
- AIワーカーやElevenLabsを活用し、手作業によるコンテンツ制作から脱却したいと考えている方
- Google Driveへのファイルアップロードを含め、コンテンツ管理のプロセスを自動化したい方
- Inoreaderでの情報収集から音声ファイルの生成、Google Driveへのアップロードまでが自動化され、コンテンツ制作にかかる時間を短縮できます
- 手作業による台本作成時の表現の揺れや、音声変換、アップロード作業でのミスや漏れを防ぎ、コンテンツの品質を安定させます
- はじめに、ElevenLabs、Google Drive、InoreaderをYoomと連携します
- 次に、トリガーでInoreaderを選択し、「指定のフィードでコンテンツが公開されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを設定し、公開コンテンツをもとにポッドキャスト用の台本を生成や声のトーン設定、音声コンテンツの生成および保存を行うためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- Inoreaderのトリガー設定では、コンテンツの取得元としたい任意のフィードURLを設定してください
- AIワーカーのオペレーションでは、利用したいAIモデルを選択し、生成したい台本やコンテンツ、保存先などの内容に合わせて指示(プロンプト)を任意に設定してください
- Inoreader、ElevenLabs、Google DriveのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
✅ElevenLabsで日本語の読み上げ精度を上げる設定テクニック7選
ElevenLabsでより自然で人間らしい日本語音声を生成するためには、単にテキストを入力するだけでなく、プロンプト(入力テキスト)の書き方や設定値に工夫を加える必要があります。ここでは、公式ドキュメントでも推奨されている精度の高い音声を作るためのテクニックを7つ解説します。
- 適切な句読点・記号と間のコントロール
- 日本語対応モデルと出力フォーマットの適切な選択
- 発音精度を向上させる辞書とタグの活用
- ひらがな・カタカナでの詳細な表記統一
- 感情・ペースの調整とテキスト正規化
- スタイル(Style)とカギカッコ等によるトーンのコントロール
- Stability調整とオーディオタグの活用(Eleven v3向け)
1.適切な句読点・記号と間のコントロール
音声の自然さを左右する大きな要因が「間(ポーズ)」です。ElevenLabsでは、テキスト内に特定の記号やタグを含めることで間をコントロールできます。- 記号の活用:
短いポーズを作りたい場合は、ダッシュ(「-」や「—」)を使用します。また、ためらいのあるトーンや少し長めの間を取りたい場合は、三点リーダー(…)を使用します。
※後半の検証部分で紹介するように、モデルによっては機能しない場合があります。 - ブレイクタグの活用:
SSML(音声合成マークアップ言語)のブレイクタグ 「<break time="1.5s" />」 を使用することで、最大3秒までの明確な間を指定できます。ただし、1回の音声生成でこのタグを多用しすぎると、音声が早口になったりノイズが混じったりと不安定になる原因となるため、必要な箇所に絞って使用します。
※Eleven v3モデルはSSMLのブレイクタグをサポートしていません。 - 読点(、)と句点(。)の徹底:
文章の意味の区切りごとに読点を打ち、文末には必ず句点を配置します。 - 改行の利用:
段落や大きな文脈の転換点では、改行を入れることで長めのポーズを持たせることが可能です。
2.日本語対応モデルと出力フォーマットの適切な選択
ElevenLabsには複数のモデルが存在するため、日本語テキストを処理する際は「Eleven v3」などの日本語対応モデルを選択することが大前提となります。さらに、出力設定を調整することで品質を安定させることができます。- 言語の上書き(Language Override):
多言語モデルを使用する際、プラットフォームが言語を誤認しないよう、強制的に「日本語」として処理させる設定を行うと発音が安定します。 - 出力フォーマットの選択:
用途に応じてMP3やWAVを選択します。高品質な音声編集を後から行う場合は非圧縮のWAV形式、Webでの軽量な配信が目的であればMP3形式を選択します。
3.発音精度を向上させる辞書とタグの活用
特定の専門用語やブランド名、固有名詞などを意図した通りに発音させるためのテクニックです。- 音素(Phoneme)タグの使用:
発音を直接指定したい場合、CMU ArpabetやIPA(国際音声記号)を用いた音素タグが推奨されます。
例:<phoneme alphabet="cmu-arpabet" ph="AE1 P AH0 L">Apple</phoneme>
※ただし、このタグは「Eleven Flash v2」および「Eleven English v1」でのみサポートされています。 - エイリアス(Alias)タグの使用:
音素タグが使えないモデル(Multilingual v2など)では、エイリアスタグを使用します。
例:<lexeme><grapheme>UN</grapheme><alias>United Nations</alias></lexeme>
これにより、「UN」という文字列を強制的に「United Nations」として読み上げさせることができます。 - 発音辞書の導入と表記統一:
プロジェクト全体でキャラクター名や社名の発音を統一したい場合、「.pls形式」または「.txt形式」の発音辞書(Pronunciation Dictionaries)をアップロードすることで、指定したルールを一括適用できます。
4.ひらがな・カタカナでの詳細な表記統一
AIは漢字の読み方を前後の文脈から推測しますが、特殊な固有名詞などで誤読が発生することがあります。これを防ぐためには、テキスト入力の段階で以下の工夫が必要です。- 難読漢字は「ひらがな」にする:
AIが間違いやすい漢字や専門用語は、最初からひらがなやカタカナで表記します。 - 数字の読み方を指定する:
「1本(いっぽん)」「1日(ついたち・いちにち)」など、文脈で読みが変わるものは、「いっぽん」と直接入力します。 - アルファベットの扱い:
略語や英単語(例:AI、SaaS)は、意図した通りに読まれない場合、カタカナ表記(エーアイ、サース)に変換して入力すると確実です。
5.感情・ペースの調整とテキスト正規化
音声のトーンやスピードを文脈に合わせて調整するためのアプローチです。🔷感情とペースのコントロール
- 物語調の文脈追加:
「〜と彼女は悲しそうに震える声で言った」といったナレーション的な文脈をテキストに追加することで、AIがトーンを理解しやすくなり、感情のこもった音声を生成しやすくなります。生成後、不要なナレーション部分は音声編集ソフトでカットします。 - スピード設定の調整:
スピード設定は0.7〜1.2の範囲で全体の速度を変更できますが、極端な値を設定すると音質が劣化する恐れがあるため、微調整にとどめるのが無難です。
※モデルによっては、スピード設定はありません。
🔷テキストの正規化(Text Normalization)
音声生成において必須級の対策となるのが、入力テキストの正規化(事前の整形)です。Eleven Flash v2.5のような軽量・高速モデルは、数字や記号をテキスト通りにそのまま読んでしまう傾向があります。これを防ぐため、音声生成にかける前にChatGPTなどのLLM(大規模言語モデル)を使って、「読み上げ用のフォーマット」に変換することも有効です。- 変換例1:「$42.50」→「42ドル50セント 」
- 変換例2:「100km」→「100キロメートル 」
- 変換例3:「Ctrl + Z」→「コントロール ゼット or コントロールプラスゼット」
6.スタイル(Style)とカギカッコ等によるトーンのコントロール
テキストの内容に合わせた感情やトーンを付与することで、音声の表現力が向上します。ElevenLabsでは、テキストの文脈をある程度自動で読み取りますが、設定によってさらに意図した表現に近づけることができます。- スタイル(Style)の調整:
スライダーを調整することで、音声の抑揚や感情の強さをコントロールできます。数値を上げると感情表現が豊かになりますが、上げすぎると発音が不安定になる傾向があります。
※モデルによっては、スタイルの設定はありません。 - 文脈による指示:
テキスト内に「!」や「?」を適切に配置することで、驚きや疑問のトーンを引き出します。 - カギカッコの活用:
会話文を「」で囲むことで、地の文とトーンを区別させやすくなります。
7.Stability調整とオーディオタグの活用(Eleven v3向け)
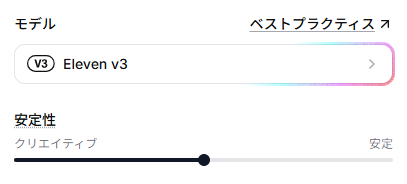
「Eleven v3」モデルを使用する場合に、性能を最大限に引き出すための専用テクニックが用意されています。🔷Stability(安定性)スライダーの調整
Eleven v3では、Stability(安定性)の設定によって出力の傾向が大きく変わります。用途に応じて適切な値を設定します。- Creative(低め):
感情的で表現豊かな音声になりますが、予測不能な音声(読みの揺れやハルシネーション)が発生しやすくなります。感情的なセリフ向きです。 - Natural(中間):
元の声のトーンに最も近く、表現力と安定性のバランスが良い設定です。 - Robust(高め):
非常に安定しており、ナレーションなど予測可能な出力を得たい場合に向いていますが、プロンプト(指示)に対する反応は薄くなります。
🔷オーディオタグ(Audio tags)と強調
Eleven v3モデルでは、テキスト内に特定のタグを記述することで、音声に効果を加えることができます。- laughs(笑い)
- whispers(囁き)
- sighs(ため息)
- sarcastic(皮肉っぽく)
- applause(拍手)
こうした感情タグや効果音タグを直接記述すると、出力音声に反映されます。
また、句読点や大文字化による強調も有効です。日本語の場合は特定の単語を括弧で囲んだり、記号を付与したりすることでアクセントをコントロールできます。
🤔ElevenLabsの日本語読み上げ精度を検証!テクニックの有無で比較

ここまで紹介したテクニックを活用することで、実際の音声品質にどの程度の差が生じるのかを検証しました。同一のテキストを用いて、「通常の文章をそのまま入力した場合」と「テクニックを適用した場合」の出力を比較します。
検証条件
以下の条件は、テクニックの有無にかかわらず共通です。- アカウント:無料プラン
- ボイス:Hijiri - Calm & Deep Female Narration
- モデル:Eleven v3
- 安定性:Natural(中間)
- 言語の上書き:オフ
- 出力フォーマット:MP3 44.1 kHz (128kbps)
音声の作成
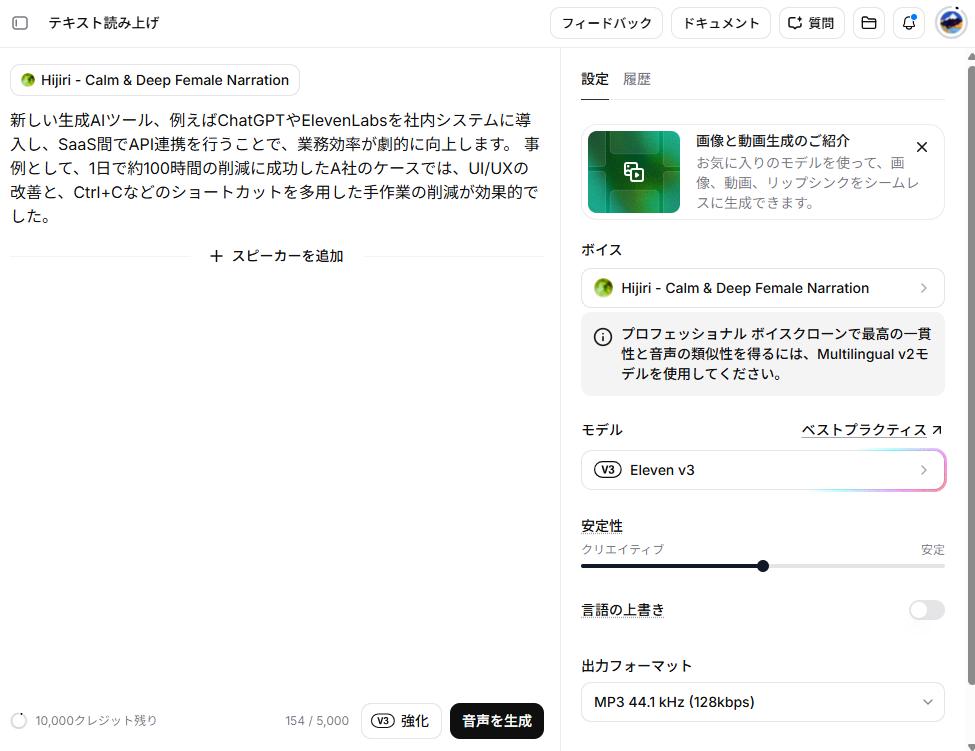
それでは、テクニックの有無で、生成される音声が変わるかを検証していきます。上記の設定が完了した後、以下のテキストを読み上げてもらいました。【テキスト(テクニック無し)】
新しい生成AIツール、例えばChatGPTやElevenLabsを社内システムに導入し、SaaS間でAPI連携を行うことで、業務効率が劇的に向上します。 事例として、1日で約100時間の削減に成功したA社のケースでは、UI/UXの改善と、Ctrl+Cなどのショートカットを多用した手作業の削減が効果的でした。
【テキスト(テクニック有り)】
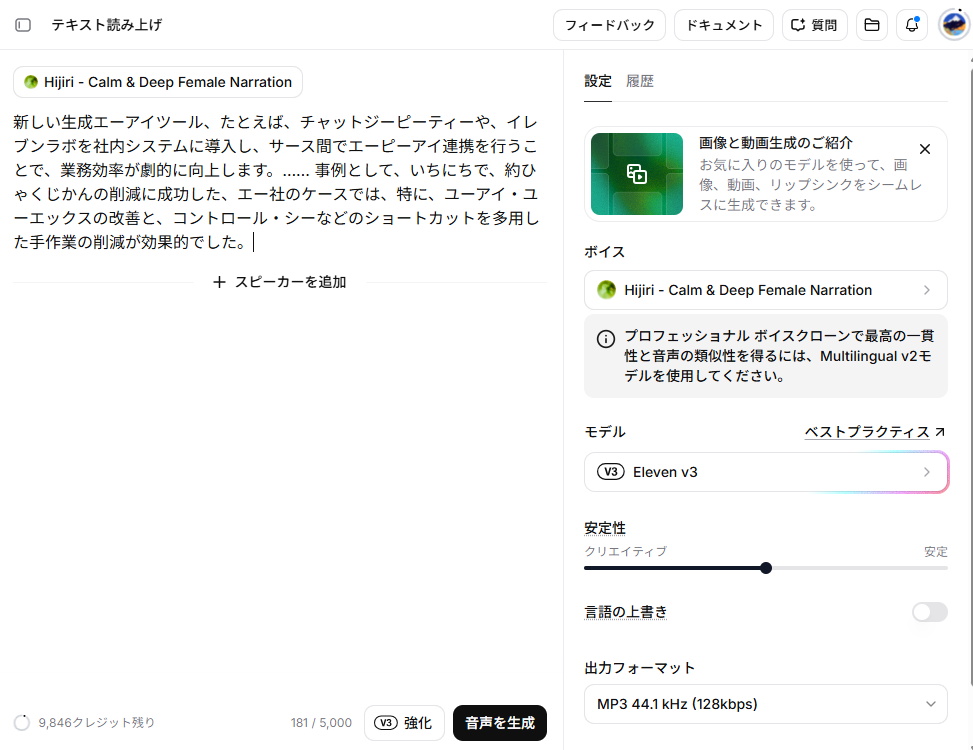
新しい生成エーアイツール、たとえば、チャットジーピーティーや、イレブンラボを社内システムに導入し、サース間でエーピーアイ連携を行うことで、業務効率が劇的に向上します。…… 事例として、いちにちで、約ひゃくじかんの削減に成功した、エー社のケースでは、特に、ユーアイ・ユーエックスの改善と、コントロール・シーなどのショートカットを多用した手作業の削減が効果的でした。
※「ひらがな・カタカナ化」「句読点と記号のコントロール」「数字の読み方指定」「テキストの正規化」のテクニックを適用しています。
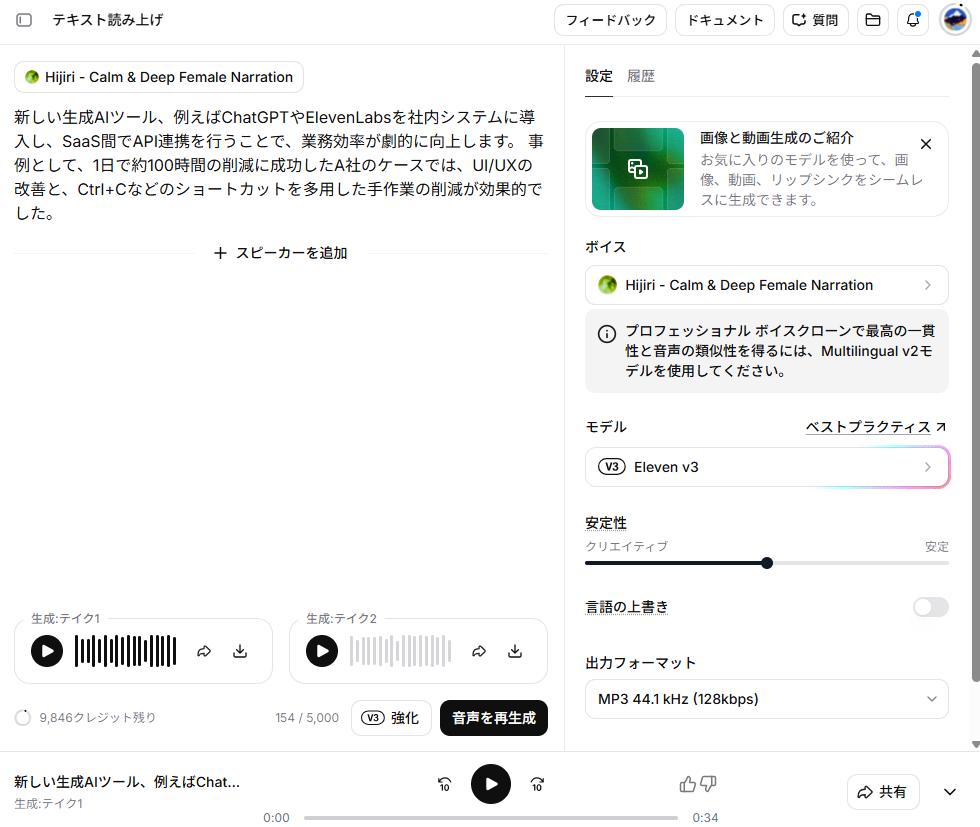
上記のテキストを送信すると、音声が作成されました。
【音声(テクニック無し)】
【音声(テクニックあり)】
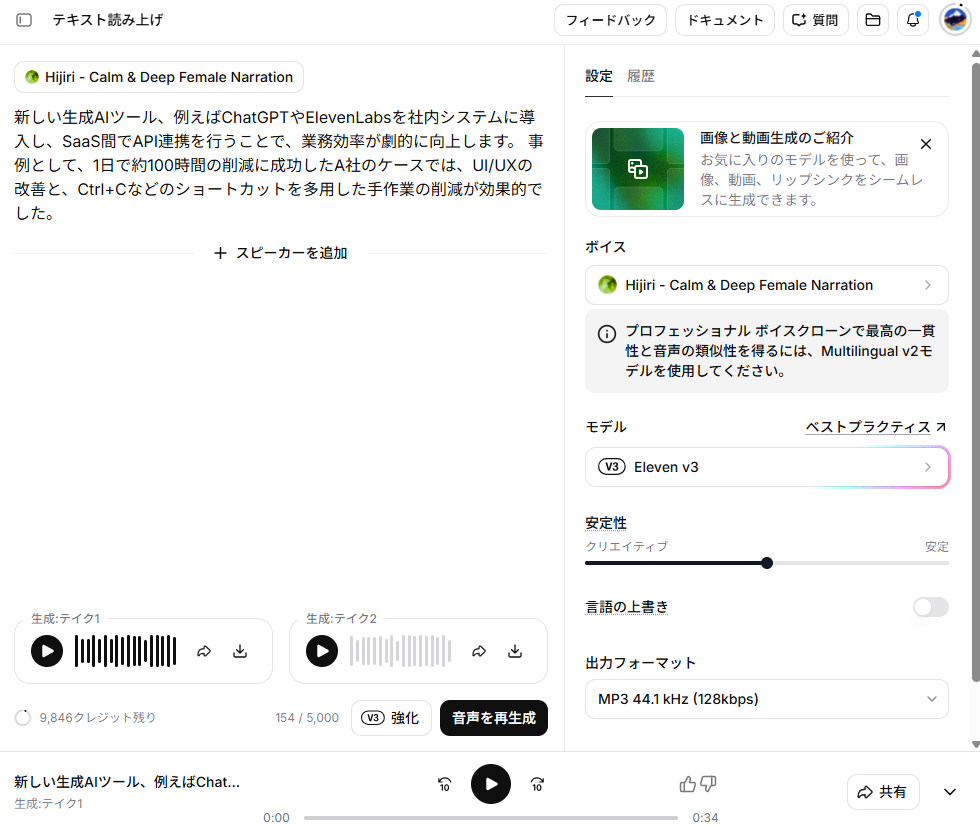
検証結果
テクニックの有無で音声を作成してみて、以下のことがわかりました。- Eleven v3モデルは基本性能が高く、テクニック不要で自然な音声を作成できた
- テクニックを使っても「……」を「てんてんてん」と誤読してしまうことがある
- 漢字や英語をカタカナに変換する手間を考慮すると、テクニックを使わない方が効率的な場合がある
🔷Eleven v3モデルの高い基本性能を確認
Eleven v3モデルの優れた性能により、事前のテキスト整形なしでも実用的な音声が生成できました。テクニック無しで生成した音声は、長さが34秒で、誤読と不自然なイントネーションは「0回」でした。この事実から、Eleven v3は文章をそのまま入力するだけで自然な音声を作成できることがわかります。事前の変換作業の手間を考慮すれば、テクニックを使わない方が作業を効率化できます。🔷テクニック利用による誤読が発生するリスク
テクニック有りで生成した音声は、長さが35秒と1秒長くなりました。これは間を作るための記号「……」を「てんてんてん」と誤読(1回)したことによる挙動です。また、「業務効率」のイントネーションが不自然になる現象も1回確認されました。イントネーションについては、モデルの安定性の影響も考えられますが、「……」の誤読のようにテクニックを使うことで、かえって予期せぬミスを招くことがわかりました。こうした挙動を踏まえて、基本的にはEleven v3モデルをテクニック無しで使い、上手くいかないときや、細かい設定・複雑な構成の音声を作成したい場合に、適したテクニックを使うことがポイントになります。ただし、モデルによっては、利用できないテクニックもあるため、作成したい音声に合わせたモデル設定も重要です。
📝まとめ
本記事では、ElevenLabsの日本語対応の現状と、自然な音声を作るための実践的なテクニックについて解説しました。一部のモデルや機能では日本語非対応・精度差がある場合もありますが、主要な機能の多くで日本語を利用できます。「Text to Speech」機能に限れば、高い日本語処理能力を持ったモデルが搭載されており、テクニックを使わずとも、自然な音声を作成することも可能です。ただし、思うようにいかない場合や、複雑な音声を作成するときは、モデルのポテンシャルを最大限に引き出すために、テキストの正規化や、記号・タグの利用といったコントロールを試してみてください。
💡Yoomでできること
Yoomを利用することで、ElevenLabsを活用した音声生成フローだけでなく、日々の様々な業務プロセスを自動化し、手作業による負担を軽減できます。- 音声を翻訳する業務フロー
- 音声のノイズを削除する業務フロー
- 音声ファイルのボイスを変換する業務フロー
音声作成だけでなく、上記のような業務にも追われている方は、Yoomを利用することで重要な業務にあてる時間を生み出せます。ノーコードで設定でき、すぐに利用できるので、ぜひ試してみてください。
- Boxにファイルがアップロードされたら、ElevenLabsで指定言語の音声でダビングして別フォルダに保存する
- Zoomで会議が終了したら、録音からElevenLabsでNoiseを除去してメールで送付する
■概要
動画や音声コンテンツの多言語展開にあたり、ナレーションの作成や差し替えに手間を感じていませんか。手作業での対応は時間がかかるだけでなく、設定ミスなども起こりがちです。このワークフローは、Boxへのファイルアップロードをトリガーに、ElevenLabsのAPIと連携して自動で指定言語の音声へダビングし、別のフォルダへ保存します。これまで手動で行っていた一連の作業を自動化し、コンテンツ制作の効率を高めます。
■このテンプレートをおすすめする方
- BoxとElevenLabsを利用し、動画や音声のダビング作業を手作業で行っている方
- ElevenLabsのAPIを活用し、多言語コンテンツ制作の効率化を検討している方
- コンテンツのグローバル展開に向け、ナレーション作成の自動化を模索している方
■このテンプレートを使うメリット
- Boxにファイルをアップロードするだけでダビングから保存までが完結するため、これまで手作業に費やしていた時間を短縮できます
- 言語設定やファイルの保存先などを自動化することで、手作業による設定ミスやファイル取り違えといったヒューマンエラーを防ぎます
■フローボットの流れ
- はじめに、BoxとElevenLabsをYoomと連携します
- トリガーでBoxを選択し、「フォルダにファイルがアップロードされたら」アクションを設定します
- オペレーションで、まずBoxの「ファイルをダウンロード」アクションを設定します
- 次に、ElevenLabsの「Dub audio or video files into a specified language」アクションで、ダウンロードしたファイルを処理します
- 続けて、ElevenLabsの「Obtain the dubbed file」アクションで、生成されたファイルを取得します
- 最後に、Boxの「ファイルをアップロード」アクションで、取得したファイルを任意のフォルダに保存します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- Boxのトリガー設定では、ファイルのアップロードを検知したいフォルダを任意で指定してください
- ElevenLabsでのダビング処理では、プロジェクト名やダビングしたい音声の言語などを自由に設定できます
- ダビング後にBoxへファイルをアップロードする際、保存先のフォルダやファイル名を任意で設定することが可能です
■注意事項
- Box、ElevenLabsのそれぞれとYoomを連携してください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細はこちらをご参照ください。
■概要
Zoom会議の録音ファイルを共有する際、周囲の雑音などが気になった経験はないでしょうか。手作業でファイルをダウンロードし、ツールを使ってノイズを除去し、メールで共有するプロセスは手間がかかります。
このワークフローを活用すれば、Zoomでの会議終了をきっかけに、ElevenLabsによる音声ファイルのノイズ除去から共有までを自動で完結できます。手作業による手間を減らし、クリアな音声データをスムーズに関係者へ共有することが可能です。
■このテンプレートをおすすめする方
- Zoom会議の録音データを、より聞き取りやすい状態で関係者に共有したいと考えている方
- ElevenLabsを活用し、音声ファイルのノイズ除去を自動で行いたいと考えている方
- 会議後の録音ファイルのダウンロードやメール送付といった定型業務を効率化したい方
■このテンプレートを使うメリット
- 会議終了後、録音ファイルの取得からElevenLabsでのノイズ除去、メール共有までが自動化されるため、これまで手作業に費やしていた時間を短縮できます。
- ファイルのダウンロード忘れやメールの送信間違いといったヒューマンエラーを減らし、確実な情報共有の実現に繋がります。
■フローボットの流れ
- はじめに、ZoomとElevenLabsをYoomと連携します。
- 次に、トリガーでZoomを選択し、「ミーティングが終了したら」というアクションを設定します。
- 続いて、オペレーションでZoomの「ミーティングのレコーディング情報を取得」アクションを設定します。
- さらに、Zoomの「ミーティングのレコーディングファイルをダウンロード」アクションで録音ファイルを取得します。
- 次に、ElevenLabsの「Audio Noise Removal」アクションを設定し、ダウンロードした音声ファイルのノイズを除去します。
- 最後に、オペレーションの「メールを送る」で、ノイズ除去後のファイルを添付して指定の宛先にメールを送付します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- メールの送信先(To, Cc, Bcc)は、任意のアドレスに設定してください。会議の参加者や特定のチームなど、共有したい相手を自由に指定できます。
- 送付するメールの件名や本文も任意の内容に設定可能です。会議名や日付といった動的な情報を本文に含めることで、より分かりやすい通知を作成できます。
■注意事項
- ZoomとElevenLabsのそれぞれとYoomを連携してください。
- Zoomのプランによって利用できるアクションとそうでないアクションがあるため、ご注意ください。
- 現時点では以下のアクションはZoomの有料プランのみ利用可能です。
- ミーティングが終了したら
- ミーティングのレコーディング情報を取得する(クラウド上に存在するレコーディングのみ取得可能なため)
- 詳細は「Zoomでミーティングのレコーディング情報を取得する際の注意点」をご参照ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
【出典】
プログラミング知識なしで手軽に構築できます。



