








・
ElevenLabsの使い方を実務検証|台本からの音声生成フローは仕事で使えるか

ElevenLabsは、自然な音声や効果音、画像、動画などを生成できるプラットフォームです。直感的なインターフェースを備え、テキストからスムーズに高品質なコンテンツを作成できます。本記事では、ElevenLabsの基本的な使い方や各機能の詳細な設定方法、および商用利用時の注意点を徹底的に解説します。また、実際にElevenLabsを利用してわかった検証結果も紹介するので、参考にしてみてください。
✍️ElevenLabsのダッシュボード構成と各メインメニューの役割

ElevenLabsのダッシュボードは、直感的に目的の機能へアクセスできるよう、画面左側にメインメニューが配置されています。ここでは、以下のメニューについて役割を解説します。
- ボイス(Voice)
- スタジオ(Studio)
- フロー(Flow)
- テンプレート(Templates)
- ファイル(Files)
ボイス(Voice)
ボイス(Voice)メニューは、生成する音声の「声」を管理するための機能です。あらかじめ用意された高品質なデフォルトボイスから、自分の声や特定の声を再現するボイスクローニングのデータまでをここで一元管理します。
- ボイスライブラリの探索:
多種多様なアクセントや年齢、性別のボイスが用意されており、日本語の読み上げに適したボイス(Liam、Sakuyaなど)を検索・お気に入り登録できます。 - カスタムボイスの追加:
ボイスデザイン機能を使って理想の声を新規作成したり、要件を満たした音声ファイルをアップロードしてクローンボイスを作成したりできます。 - ボイス設定の微調整:
声のトーンや安定性をボイスごとに基本設定として保存しておくことが可能です。
スタジオ(Studio)
スタジオ(Studio)は、長文の読み上げや複数人が登場する対話形式の音声コンテンツを制作するための編集環境です。単発のテキスト読み上げではなく、プロジェクト単位で音声を管理したい場合に適しています。
- プロジェクトの作成:
オーディオブックやポッドキャストなど、章や段落ごとに構成された長尺のコンテンツを作成します。 - テキストエディタの活用:
画面上でテキストを入力し、段落ごとに異なるボイスや読み上げスピード、間の長さを細かく指定できます。 - 発音辞書の適用:
プロジェクト全体に対して、特定の専門用語やキャラクター名の読み方を固定する発音辞書(.plsや.txt形式)を一括適用できます。
フロー(Flow)
フロー(Flow)は、無限に広がるキャンバス上で複数のAI機能を視覚的に繋ぎ合わせ、一連のワークフローを構築する機能です。テキストから音声、画像生成までを一つのキャンバス内で完結させます。
- ノードの追加と接続:
LLM(テキスト生成)、テキスト読み上げ、画像生成、メディアアップロードなどの「ノード」を画面に追加し、線で繋ぎます。 - 直感的な操作:
ブロックを配置する感覚で処理の流れを設計できるため、プロンプトの出力をそのまま次の機能に入力する自動化が簡単です。 - コメントと共有:
ノードごとにコメントを残すことができ、作成したフローは他のユーザーと共有して共同作業に活用できます。
テンプレート(Templates)
テンプレート(Templates)は、目的のコンテンツを素早く作成するためにあらかじめ用意された設定のひな型です。ゼロから設定を行う手間を省き、スムーズに作業を開始できます。
- ユースケース別の選択:
ポッドキャストのイントロ作成、動画のナレーション、オーディオブックのひな型など、用途に応じたテンプレートが揃っています。 - カスタマイズ性:
テンプレートを読み込んだ後、ボイスの変更やプロンプトの調整など、自分のプロジェクトに合わせて自由に内容を修正できます。 - 効率化への貢献:
既成テンプレートを読み込んで再利用することで、同じ品質のコンテンツを繰り返し生成する際の作業時間を短縮します。
ファイル(Files)
ファイル(Files)メニューは、アップロードした素材やElevenLabsで生成したすべてのメディアデータを管理するストレージです。過去のプロジェクトデータへのアクセスが容易になります。
- データのアップロード:
ボイスクローニング用の音声データや、文字起こし・吹き替え用の動画ファイルをこの画面から一括してアップロード・管理できます。 - 生成履歴の確認:
作成した音声やサウンドエフェクト、動画などのファイルが履歴として保存され、いつでも再ダウンロードやプレビューが可能です。 - ストレージ容量の管理:
プランに応じたファイルサイズの制限やクレジットの消費状況を確認しながら、不要なデータを削除して容量を整理します。
⭐Yoomは音声生成に関する業務全体を自動化できます
ElevenLabsは、テキストから音声を自動作成できる優れたツールです。しかし、効率化できるのは、業務全体の一部ではないでしょうか。企画のリサーチにはじまり、ElevenLabsへのデータ入力、そして作成されたファイルの保存といった作業は依然として手作業になります。Yoomを使えば、リサーチから音声作成、そしてストレージへの保存までのすべてのプロセスを自動化できます。[Yoomとは]
Yoomを利用することで、リサーチや音声作成に追われている担当者の負担が軽減し、同じ時間でより多くのコンテンツを作成できるようになります。ノーコードで設定でき、すぐに導入できるので、まずは以下のようなテンプレートを試して、業務全体が自動化される環境を体験してみてください。
- Slackでメッセージが送信されたら、AIワーカーで投稿内容の文脈を分析しElevenLabsでナレーションの原案を作成する
- Inoreaderでコンテンツが公開されたら、AIワーカーでポッドキャスト用にElevenLabsで変換しGoogle Driveにアップロードする
- Slackの投稿内容を元に、手軽に音声コンテンツを制作したいと考えている方
- ElevenLabsなどをの操作をAIエージェントを活用して自動化することに関心がある方
- 日々の情報発信やコンテンツ制作の効率化を目指しているマーケティング担当者の方
- Slackへの投稿をきっかけにAIが自動で原稿を作成するため、手作業での原稿起こしの手間を省き、音声コンテンツ制作にかかる時間を短縮できます。
- 原稿作成から音声合成まで、一連の制作フローが自動化されるため、担当者による品質のばらつきを防ぎ、業務の標準化に繋がります。
- はじめに、Slack、Google Drive、ElevenLabsをYoomと連携します。
- 次に、トリガーでSlackを選択し、「メッセージがチャンネルに投稿されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを設定し、Slackの投稿内容の文脈を分析してナレーション原稿を生成したうえで、ElevenLabsで音声化しGoogle Driveへ保存するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Slackのトリガー設定では、通知を検知するチャンネルや、特定のキーワードが含まれる投稿のみを対象にするなど、任意で条件を設定してください。
- AIワーカーに与える指示(プロンプト)は、生成したいナレーションのトーン&マナーに合わせて自由にカスタマイズが可能です。
- ElevenLabsで音声を作成する際のボイスID(話者)や、生成された音声ファイルを保存するGoogle Driveのフォルダは任意で設定してください。
- Slack、Google Drive、ElevenLabsのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- Inoreaderで収集した情報をもとに、ポッドキャストなどの音声コンテンツを効率的に制作したい方
- AIワーカーやElevenLabsを活用し、手作業によるコンテンツ制作から脱却したいと考えている方
- Google Driveへのファイルアップロードを含め、コンテンツ管理のプロセスを自動化したい方
- Inoreaderでの情報収集から音声ファイルの生成、Google Driveへのアップロードまでが自動化され、コンテンツ制作にかかる時間を短縮できます
- 手作業による台本作成時の表現の揺れや、音声変換、アップロード作業でのミスや漏れを防ぎ、コンテンツの品質を安定させます
- はじめに、ElevenLabs、Google Drive、InoreaderをYoomと連携します
- 次に、トリガーでInoreaderを選択し、「指定のフィードでコンテンツが公開されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを設定し、公開コンテンツをもとにポッドキャスト用の台本を生成や声のトーン設定、音声コンテンツの生成および保存を行うためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- Inoreaderのトリガー設定では、コンテンツの取得元としたい任意のフィードURLを設定してください
- AIワーカーのオペレーションでは、利用したいAIモデルを選択し、生成したい台本やコンテンツ、保存先などの内容に合わせて指示(プロンプト)を任意に設定してください
- Inoreader、ElevenLabs、Google DriveのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
📖ElevenLabsの各機能の使い方と設定方法
ElevenLabsは音声以外にも多彩な生成機能を備えています。ここでは、ダッシュボードから利用できる以下の主要機能の具体的な設定方法と使い方を解説します。
- 音声作成
- サウンドエフェクト
- ボイスチェンジャー
- ボイスアイソレーター
- スピーチ to テキスト(文字起こし)
- 吹き替え
- 画像作成
- 映像作成
- 音楽作成
音声作成(Text to Speech)の使い方
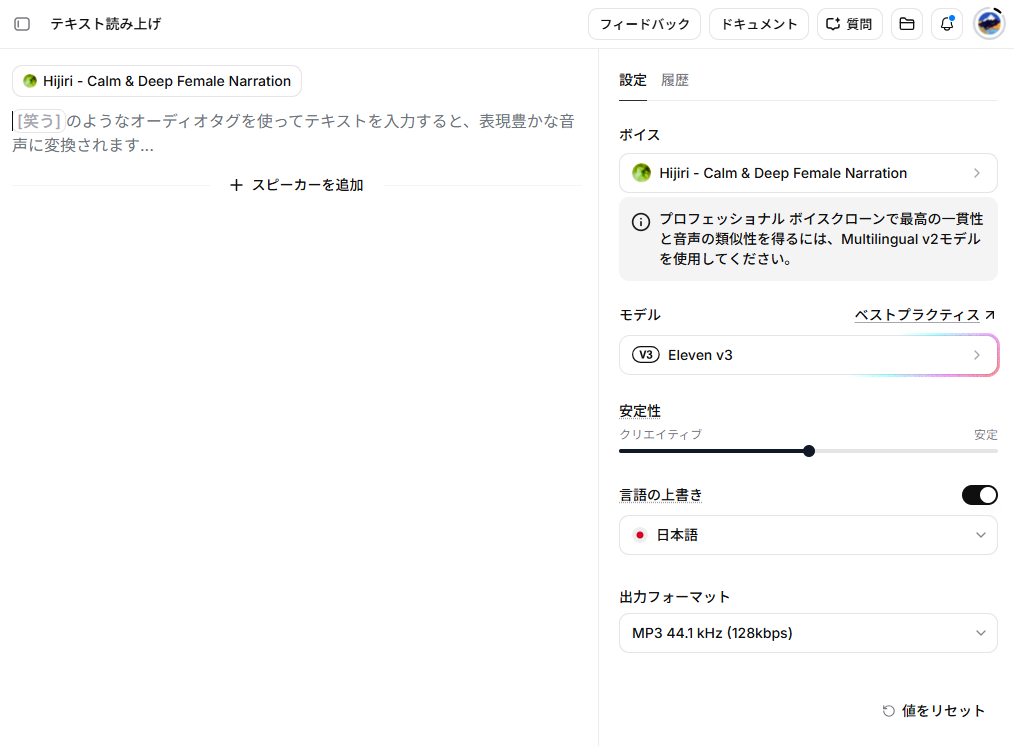
音声作成(Text to Speech)は、テキストを入力して自然な合成音声を出力するElevenLabsの中核機能です。
- ボイスの指定:
メニューから「言語」や「アクセント」などでフィルタリングし、用途に合った声(Liam、Sakuyaなど)を選べます。 - モデルの選択:
日本語の読み上げには「Eleven v3」や「Eleven Multilingual v2」などの対応モデルを選択します。 - Stability(安定性)の調整:
スライダーを高く(Robust寄り)すると安定したナレーションになり、低く(Creative寄り)すると感情豊かになりますが、ハルシネーション(意図しない音声の混入)のリスクが高まります。 - 出力フォーマットの指定:
編集用途であれば「WAV」、Web配信用途であれば「MP3」を選択して音声を生成します。 - テキストの入力:
音声にしたいテキストを入力し、「音声を生成」をクリックすると、ファイルが作成されます。
なお、モデルによっては、設定項目が増える場合があります。
サウンドエフェクト(Sound Effects)の使い方
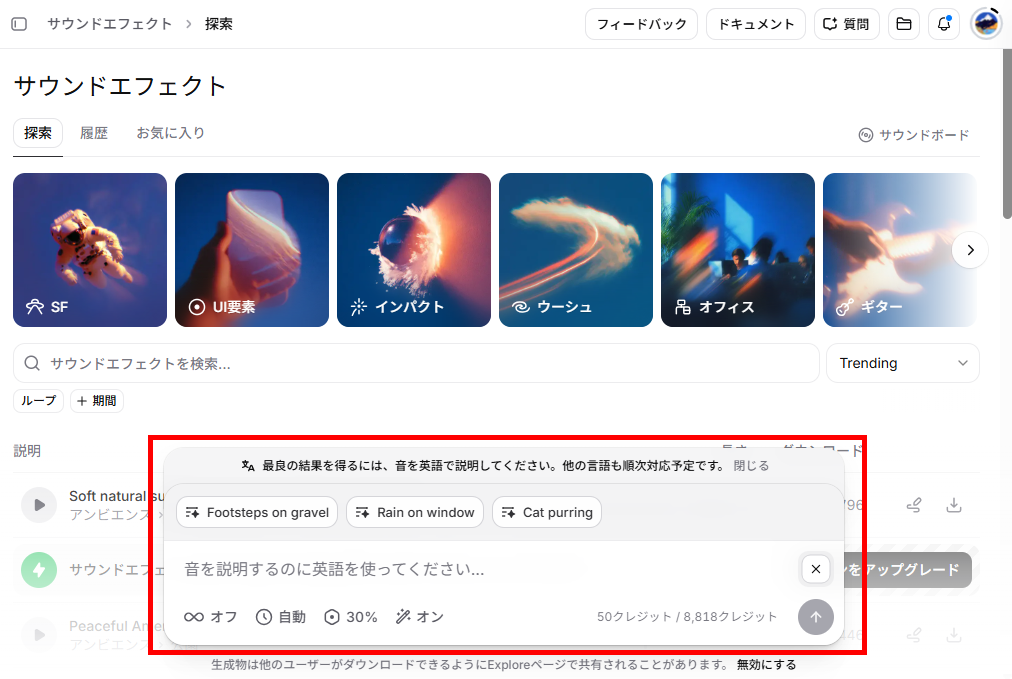
サウンドエフェクト(Sound Effects)は、プロンプト(指示文)を入力するだけで高品質な効果音を生成する機能です。
- プロンプトの入力:
生成したい音のイメージを入力します。日本語も入力可能ですが、英語での指示の方がより精度の高い結果を得られます。 - Loop(ループ)設定:
背景音として繰り返し再生したい場合は、ループ設定をオンにします。 - Duration(長さ)の指定:
Auto(自動)のほか、必要な秒数を指定して生成時間をコントロールします。 - Intensity/Volumeの調整:
エフェクトの強さや音量をパーセンテージ(例:30%)で指定し、生成ボタンをクリックします。
ボイスチェンジャー(Voice Changer)の使い方
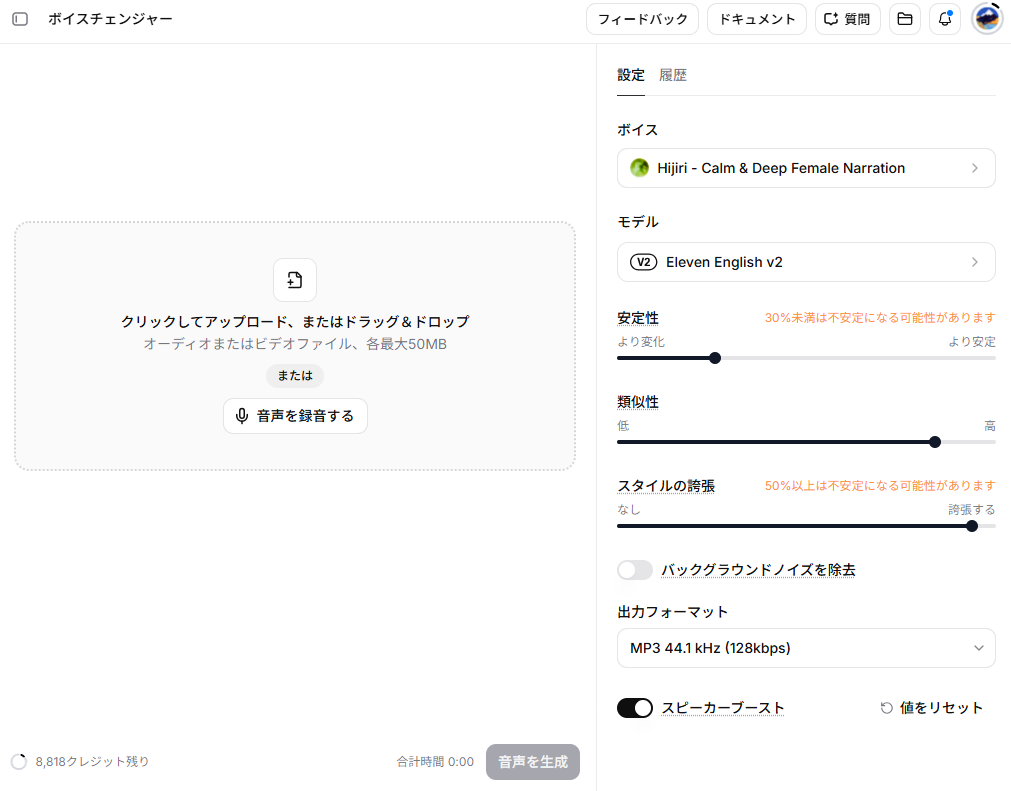
ボイスチェンジャー(Voice Changer)は、録音した自分の声や既存の音声ファイルを、別のキャラクターの声に変換する機能です。
- 音声のアップロード:
オーディオまたはビデオファイル(最大50MB)をドラッグ&ドロップでアップロードするか、マイクで直接録音します。 - ターゲットボイスの選択:
変換先となる目的のボイスを指定します。 - モデルの設定:
変換に利用するモデルを指定します。変換したい言語に対応しているモデルを選ぶことが重要です。 - Stability(安定性)の調整:
スライダーを右へ移動すると安定したナレーションになり、左へ移動すると感情豊かになりますが、ハルシネーション(意図しない音声の混入)のリスクが高まります。 - Similarity(類似度)の設定:
ターゲットのボイスにどれだけ忠実に似せるかを「低〜高」で調整します。 - Style Exaggeration(誇張)の調整:
声の抑揚や特徴をどれだけ強調するかを設定します。50%以上に設定すると出力が不安定になる場合があるため注意が必要です。 - バックグラウンドノイズを除去:
オーディオ入力からバックグラウンドノイズを除去する機能です。 - 出力フォーマットの指定:
編集用途であれば「WAV」、Web配信用途であれば「MP3」を選択して音声を生成します。 - スピーカーブースト:
生成速度が落ちるかわりに、合成音声との声の類似性が高まります。
ボイスアイソレーター(Voice Isolator)の使い方
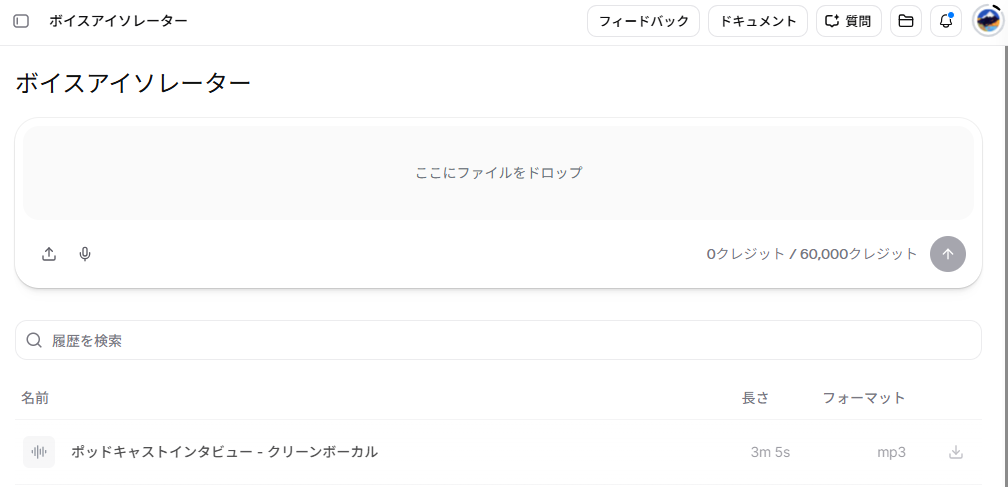
ボイスアイソレーター(Voice Isolator)は、音声ファイルから背景ノイズやBGMを取り除き、人の声だけをクリーンに抽出する機能です。言語に依存しないため、日本語の音声にも問題なく使用できます。
- ファイルのドロップ:
対象となる動画ファイルや音声ファイル(mp3、mp4、wav等)をアップロードエリアにドラッグ&ドロップします。 - 自動抽出:
特別な設定は不要で、矢印ボタンをクリックすると自動的にノイズが除去された音声が生成されます。 - 履歴の確認とダウンロード:
処理が完了したファイルは履歴テーブルに「名前」「長さ」「フォーマット」とともに一覧表示され、必要に応じてダウンロードできます。
スピーチ to テキスト(Speech to Text)の使い方
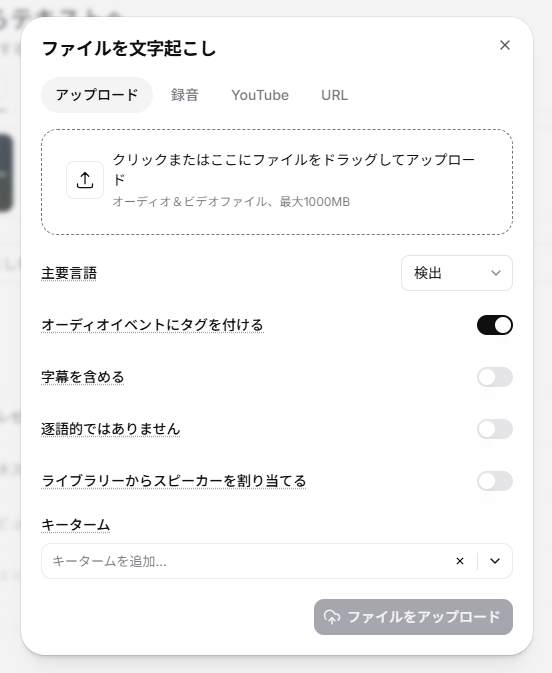
スピーチ to テキスト(Speech to Text)は、高い精度で音声や動画ファイルから文字起こしを行う機能です。日本語にも対応しています。
- ソースの準備:
ファイルのアップロード(プランによって最大3GB)、マイク録音、YouTubeリンクなどのURLから対象を指定します。 - 言語とキータームの設定:
「主要言語」を日本語(または検出)に設定し、固有名詞がある場合は「キーターム」に単語を事前登録して認識精度を上げます。 - オーディオイベントにタグを付ける:(笑い声)、(足音)などのオーディオイベントをトランスクリプションに表示するかどうかを切り替えます。
- 逐語的ではありません:
フィラー(あー、うーなど)を除去するかどうかを切り替えます。 - 字幕を含める:
字幕付きをプロジェクトのデフォルトにするかどうかを切り替えます。 - ライブラリーからスピーカーを割り当てる:
スピーカーライブラリーに登録されているスピーカーと照合するかどうかを切り替えます。 - 文字起こしの実行:
設定完了後、ボタンをクリックしてテキストデータを生成します。
吹き替え(Dubbing)の使い方
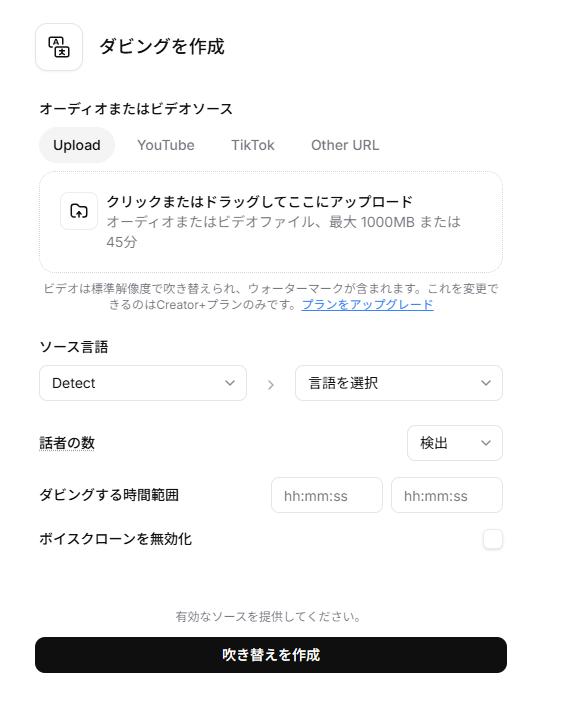
吹き替え(Dubbing)は、動画や音声ファイルの言語を別の言語へ自動的に翻訳し、元の声のトーンを維持したまま吹き替え音声を生成する機能です。
- ソースのアップロード:
動画や音声ファイル(最大1GB/45分)、またはYouTubeやTikTokのURLを入力します。 - 言語の設定:
「ソース言語」と「ターゲット言語(例:日本語から英語)」を指定します。 - 話者の設定:
動画内の話者の数を指定(または自動検出)し、吹き替えを行う「時間範囲」を設定します。 - ボイスクローンの選択:
デフォルトでは元の話者の声がクローンされますが、「ボイスクローンを無効化」にチェックを入れると標準的な声で吹き替えられます。
画像作成(Image)の使い方
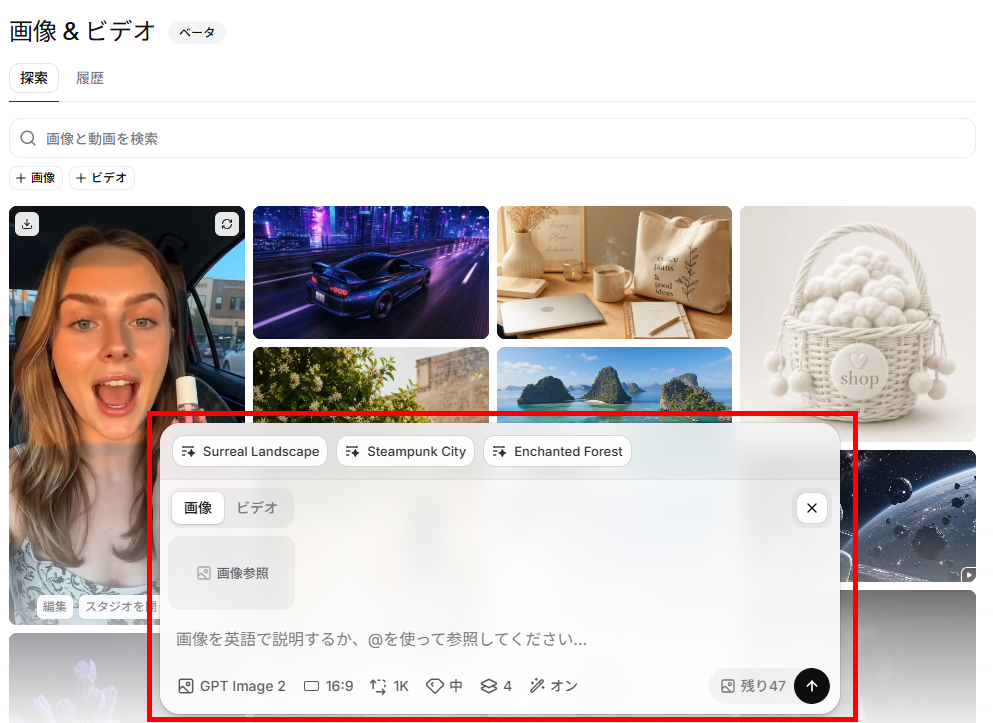
画像作成(Image)は、テキストプロンプトから高画質な画像を生成する機能です。現状は英語プロンプトでの入力が推奨されています。
- プロンプトの入力:
生成したい情景や被写体の詳細を英語で入力します。 - アスペクト比の選択:
用途に合わせて画像の縦横比(16:9、1:1、9:16など)を指定します。 - 解像度とスタイルの指定:
出力解像度(1K等)を指定し、必要に応じて「Surreal Landscape」や「Photorealistic」などのスタイルタグを付与します。 - 生成と保存:
バッチサイズ(一度に生成する枚数)を指定して生成し、気に入った画像を保存します。
映像作成(Video)の使い方
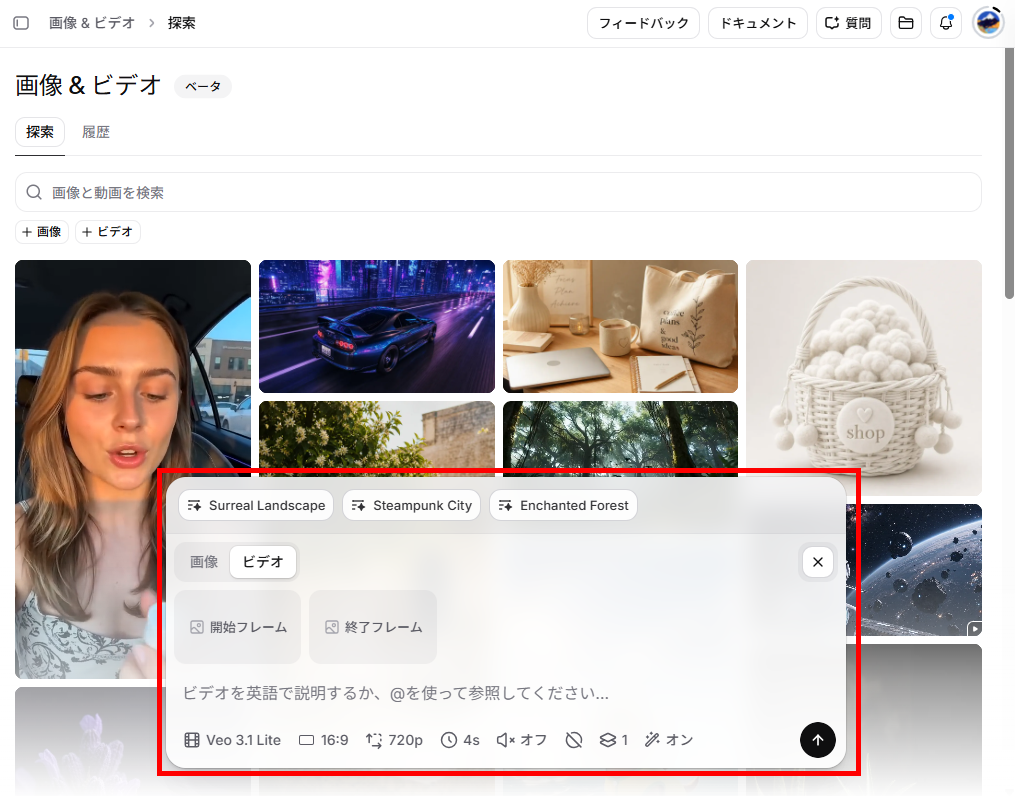
映像作成(Video)は、テキストや参照画像をもとに短い動画クリップを生成する機能です。
- プロンプトとアセットの設定:
動画のシーンを説明します。「@」記号を使用して、保存済みのキャラクターアセットなどを参照することも可能です。モデルによっては、英語での指示が推奨されます。 - 参照画像のアップロード:
動画の開始フレームとして使いたい画像がある場合は、参照画像をアップロードします。 - 動画スペックの指定:
解像度(720p、1080pなど)と、生成する動画の長さ(4秒など)を設定します。 - 生成の実行:
設定内容を確認し、生成ボタンを押して動画を出力します。
音楽作成(Music)の使い方
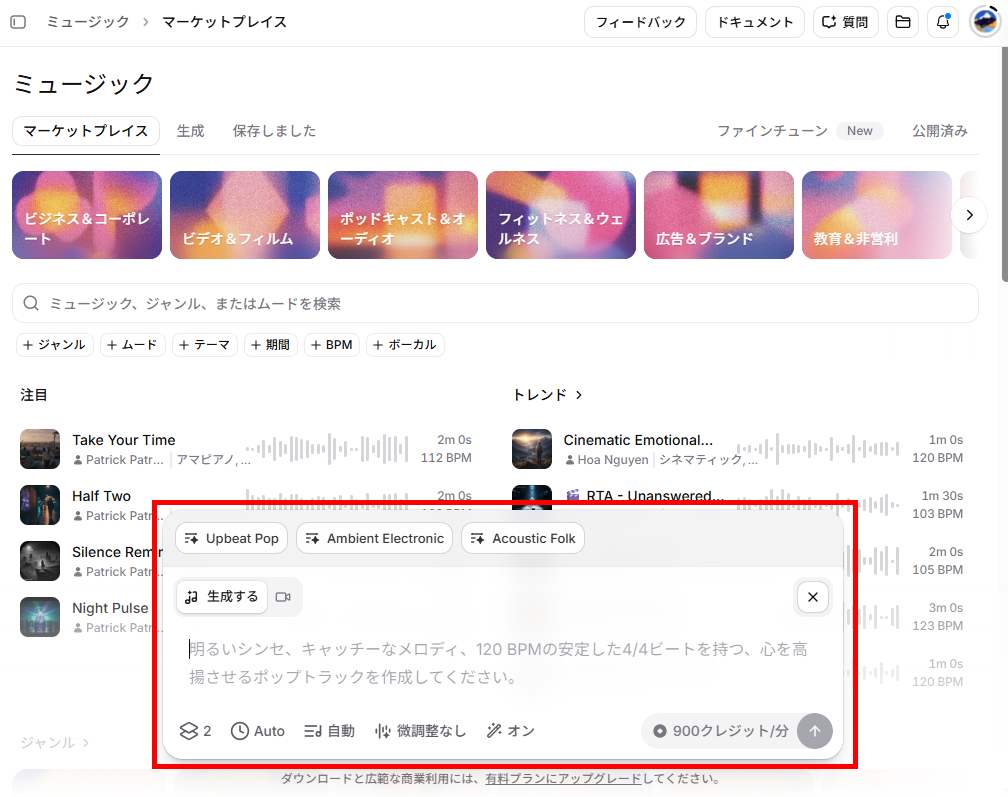
音楽作成(Music)は、プロンプトに基づいてBGMや楽曲を生成する機能です。簡単な日本語指示にも対応していますが、詳細なニュアンスを伝えるには英語が適しています。
- プロンプトとタグの入力:
作りたい楽曲のジャンルやムードを入力し、「Upbeat Pop」などのスタイルタグを指定します。 - 生成数:
一度に1〜4曲までを作成可能です。 - 歌詞の有無:
インストゥルメンタル(歌詞なし)か、歌詞入りかを選択します。 - 長さとBPMの指定:
楽曲の長さやテンポ(BPM)を調整します。 - ループ・微調整設定:
ループ音源として使いたい場合はループ設定を有効にし、生成された楽曲に対してファインチューニングを行って完成させます。
🤔【検証1】Elevenlabsのテキスト読み上げ機能を使ってみた!

ここでは、実際に音声作成(Text to Speech)機能を使用し、入力したテキストからどの程度自然な日本語音声が生成されるかを検証します。
検証条件
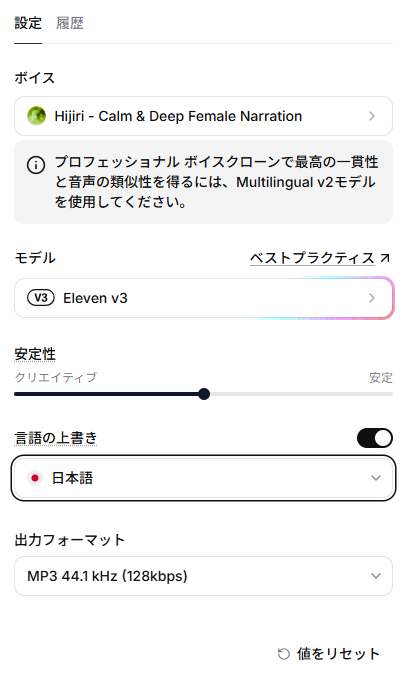
検証した条件は、以下の通りです。
- アカウント:無料プラン
- 使用機能:テキスト読み上げ(Text to Speech)
- 使用モデル:Eleven v3
- 安定性:中間
- 使用ボイス:Hijiri - Calm & Deep Female Narration
- 言語の上書き:オン(日本語)
- 出力フォーマット:MP3 44.1 kHz (128kbps)
音声の作成
先ほど解説した手順で、音声を作成していきます。
- メニューから「テキスト読み上げ(Text to Speech)」を選択します。
- モデルなどを以下のように設定しました。
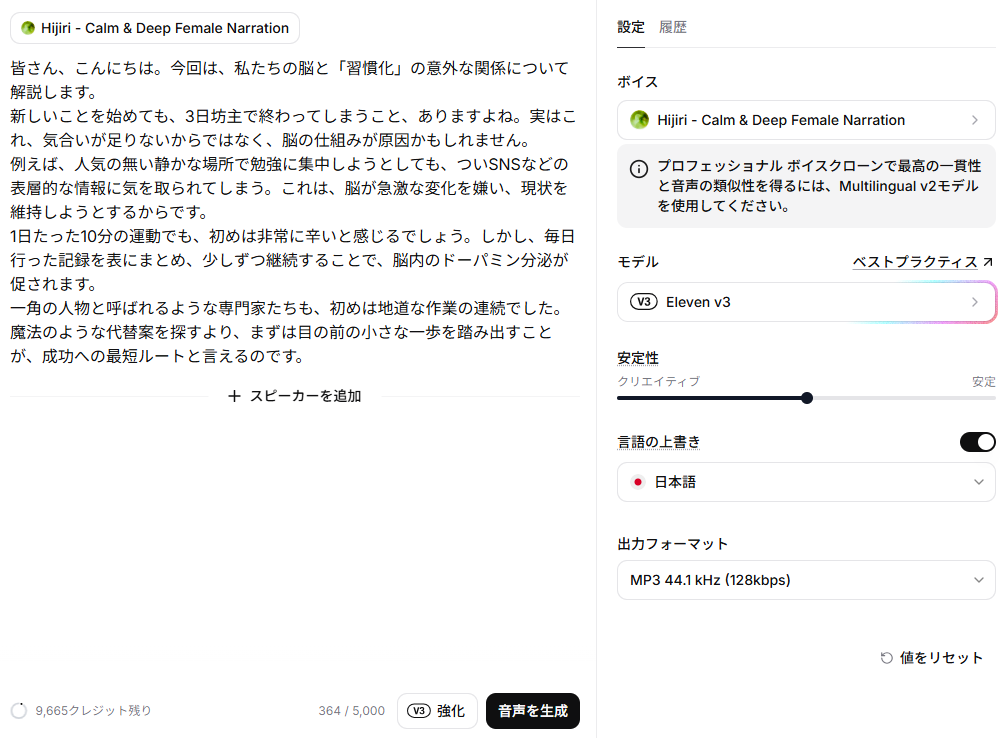
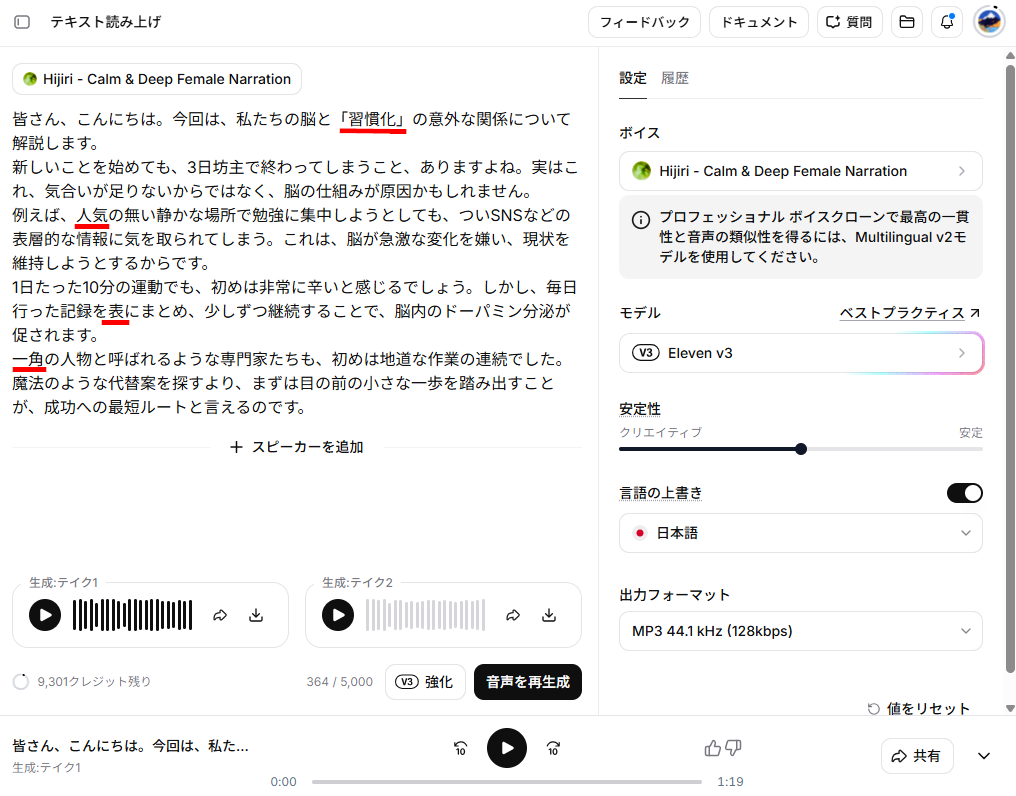
- テキストを入力して、「音声を生成」をクリックします。入力したテキストは以下の通りです。
【入力テキスト】
皆さん、こんにちは。今回は、私たちの脳と「習慣化」の意外な関係について解説します。
新しいことを始めても、3日坊主で終わってしまうこと、ありますよね。実はこれ、気合いが足りないからではなく、脳の仕組みが原因かもしれません。
例えば、人気の無い静かな場所で勉強に集中しようとしても、ついSNSなどの表層的な情報に気を取られてしまう。これは、脳が急激な変化を嫌い、現状を維持しようとするからです。
1日たった10分の運動でも、初めは非常に辛いと感じるでしょう。しかし、毎日行った記録を表にまとめ、少しずつ継続することで、脳内のドーパミン分泌が促されます。
一角の人物と呼ばれるような専門家たちも、初めは地道な作業の連続でした。魔法のような代替案を探すより、まずは目の前の小さな一歩を踏み出すことが、成功への最短ルートと言えるのです。 - 約5秒で変換が完了し、音声が再生されました。
検証結果
テキストの読み上げ機能を使ってみて、以下のことがわかりました。
- 364文字のテキストが約5秒という短時間で自然なイントネーションの音声に変換された
- 括弧書きのキーワードも文脈に合わせて強調される
- 初心者でも「ボイス」「モデル(v3推奨)」「言語の上書き」の3項目を設定するだけで直感的に操作が可能
- 複数の読み方がある簡単な漢字で3箇所の誤読が発生した
🔷初心者にも扱いやすい直感的な操作性と高い音声品質
今回の検証において最も重要な発見は、特別なスキルがなくても、ごくわずかな設定のみで非常に自然な音声を生成できたことです。実際に「ボイス」「モデル」「言語の上書き」という3つの項目を設定するだけで、364文字のテキストが約5秒という短時間で音声化されました。
生成された音声は句読点での自然な区切りはもちろん、括弧で囲んだ「習慣化」といったキーワードも文脈に合わせて区切られ、強調した読み方になっていました。AIで作成したと言われなければ気づかないほど、人間が話しているかのような高いクオリティを実感できます。なお、Eleven v3モデルより前のモデルを使用すると設定項目が増えます。初めて利用する方にはシンプルな操作で完結する「Eleven v3モデル」の利用がおすすめです。
🔷複数読みを持つ漢字の誤読と対策
一方で、日本語特有の難しさによる課題も見つかりました。生成された音声を確認すると、「人気(ひとけ)」を「にんき」、「表(ひょう)」を「おもて」、「一角(ひとかど)」を「いっかく」と、3箇所で誤読が発生していました。
音声自体のアクセントや品質は完璧といえるレベルであるため、こうした読み方のバリエーションがある漢字については、あらかじめテキストをひらがなやカタカナに変換して読み込ませる工夫が必要です。裏を返せば、この「読み仮名の調整」さえ気をつけていれば、本当に日本人が話していると錯覚するほどの処理精度を引き出すことができます。
🤔【検証2】ElevenLabsのフローを使ってみた!

次にフロー(Flow)機能を利用して、テーマを提供するだけで、台本を作成し、音声ファイルに変換する業務プロセスの自動化を試してみます。
検証条件
- アカウント:無料プラン
- 使用機能:フロー(Flow)
フローの作成
以下の手順で、フローを作成していきます。
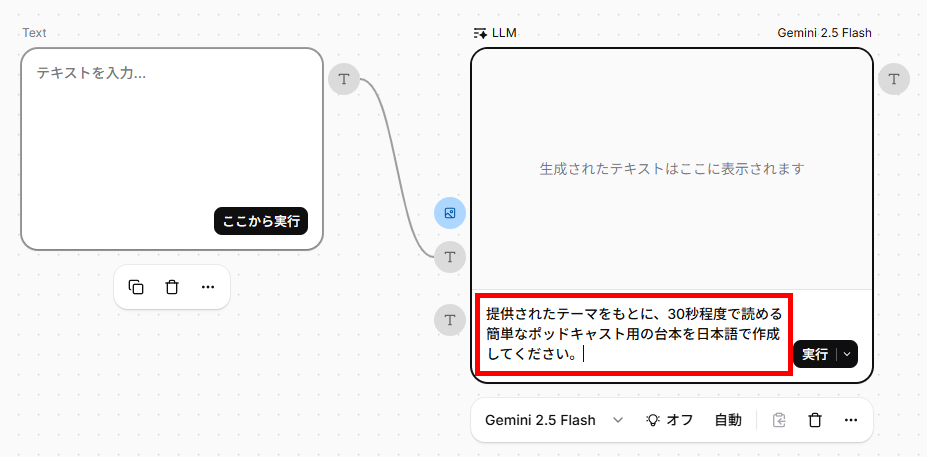
- メニューから「フロー(Flow)」を開き、新しい無題のフローを作成します。
- キャンバス上で右クリックをするか、下のメニューから「テキスト」ノードを追加します。
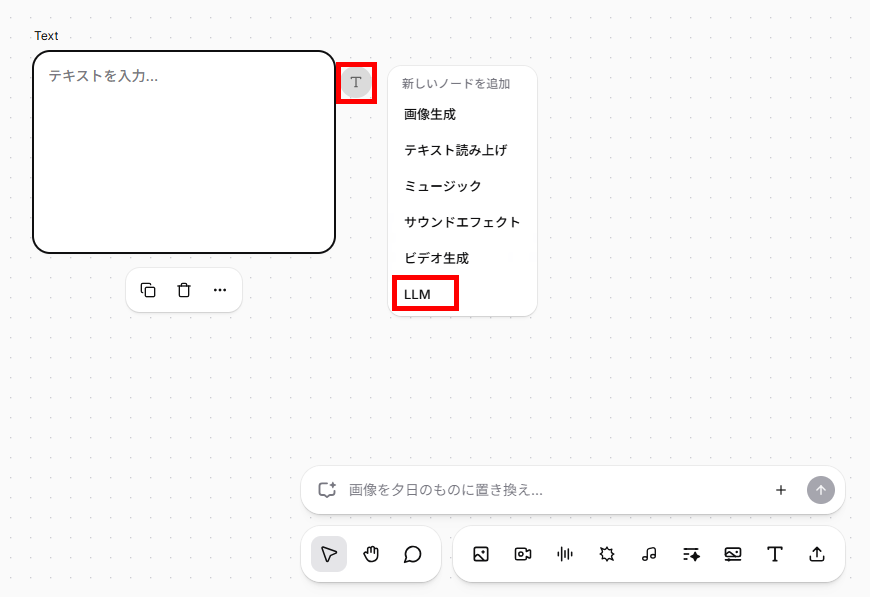
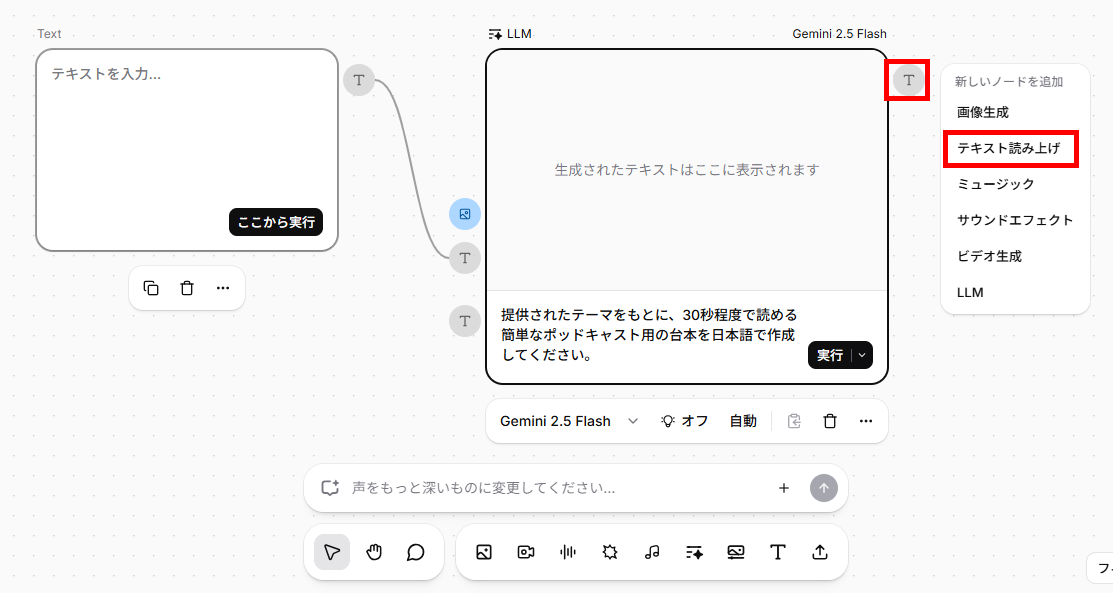
- 続けて「テキスト」ノードの「T」マークをクリックして、「LLM」ノードを追加します。
- 「LLM」ノードに台本を作成するためのプロンプトを設定します。今回は、以下のプロンプトを設定しました。
【台本作成プロンプト】
提供されたテーマをもとに、30秒程度で読める簡単なポッドキャスト用の台本を日本語で作成してください。 - 「LLM」ノードの「T」マークをクリックし、「テキスト読み上げ」ノードを追加します。
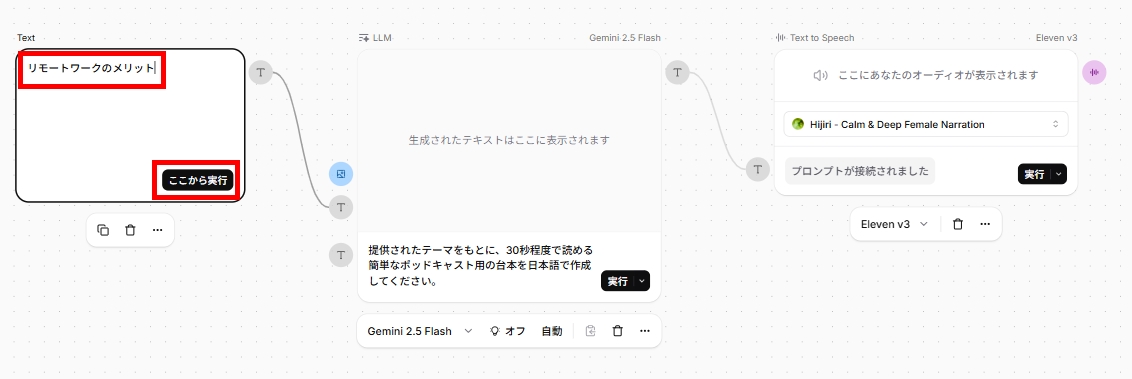
- 以上で、テーマから台本と音声を作成するフローの作成が完了です。動作を確認するため、以下のテーマを入力し、「ここから実行」をクリックしました。
【テーマ】
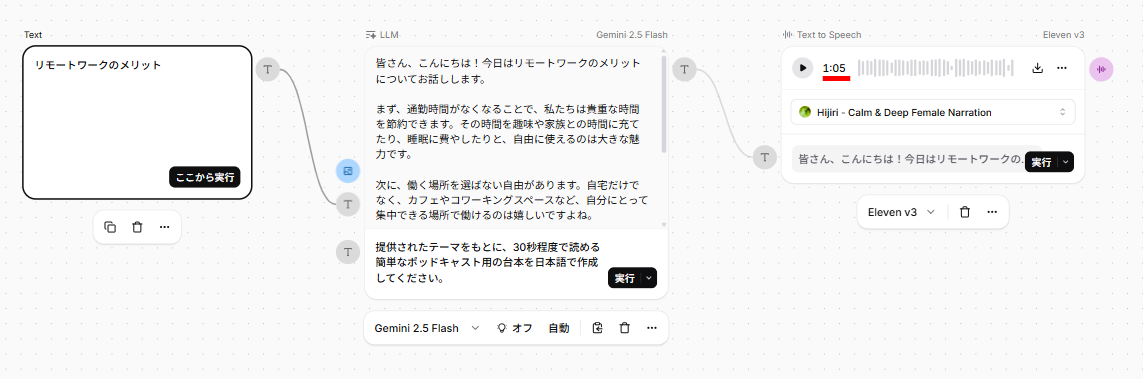
リモートワークのメリット - 約38秒で一連のタスクが完了し、1分5秒の音声が作成されました。
検証結果
フロー機能を使ってみて、以下のことがわかりました。
- キャンバス上にノードを設置するだけで、2分とかからずに音声作成の自動化フローを構築できた
- フローを経由して生成された音声も、イントネーションが自然で誤読のない完璧な仕上がりだった
- LLMによる台本作成(約320文字)から音声化まで全体で38秒かかり、通常の読み上げよりも処理時間を要した
- 「30秒程度」と指示したプロンプトに対し、1分5秒の音声が出力されたため、文字数での細かな指定が必要
🔷柔軟でスピーディなフロー構築と確かな処理性能
業務プロセスを自動化する「フロー機能」の検証で最初に注目すべきは、その直感的な操作性と構築の速さです。キャンバス上に「テキスト」「LLM」「テキスト読み上げ」といったノードを手動で配置し、線でつなぐだけで、設定とプロンプトさえ決まっていれば2分もかからずにワークフローを作成できました。さらに、フロー機能を通じて生成された音声も、自然なイントネーションの日本語で単語の誤読もない完璧なものでした。自動化プロセスを経由しても、生成される音声の品質が落ちないことを確認できました。また、今回は音声生成を試しましたが、画像生成ノードや有料プランの映像生成ノードも組み合わせられるため、利用シーンに合わせて柔軟に構成をカスタマイズできる点も非常に便利です。
🔷処理時間とプロンプトによる出力調整の課題
利便性が高い一方で、実際の運用にあたって注意すべき点も確認できました。まず、フローを通じた処理には、単体の読み上げ機能(364文字で5秒)よりも時間がかかります。今回の検証では、LLMによる約320文字の台本作成に10秒弱、そこから音声生成までに約30秒かかり、完了までに全体で38秒を要しました。長尺の台本を作成する場合はさらに時間がかかる可能性があるため、実業務では期限に余裕を持った運用が求められます。
また、LLMへのプロンプトで「30秒程度で読める台本」と指示したにもかかわらず、最終的に作成された音声は1分5秒となりました。意図した長さの音声コンテンツを作成するためには、時間ではなく「目安となる文字数」で指示を出すなど、プロンプトの出し方に工夫が必要です。
✅ElevenLabsを商用利用する際の注意点

ElevenLabsは優れた機能を持ちますが、ビジネスで利用する場合には以下のような点を正しく理解しておく必要があります。
- 有料プランと無料プランにおける商用利用の可否
- ボイスクローン利用時の権利とルール
- 生成した画像・音楽・動画の著作権や利用制限
有料プランと無料プランにおける利用範囲の違い
ElevenLabsでは、利用目的に応じて複数のプランが用意されています。プランによって商用利用の可否が異なるため注意が必要です。
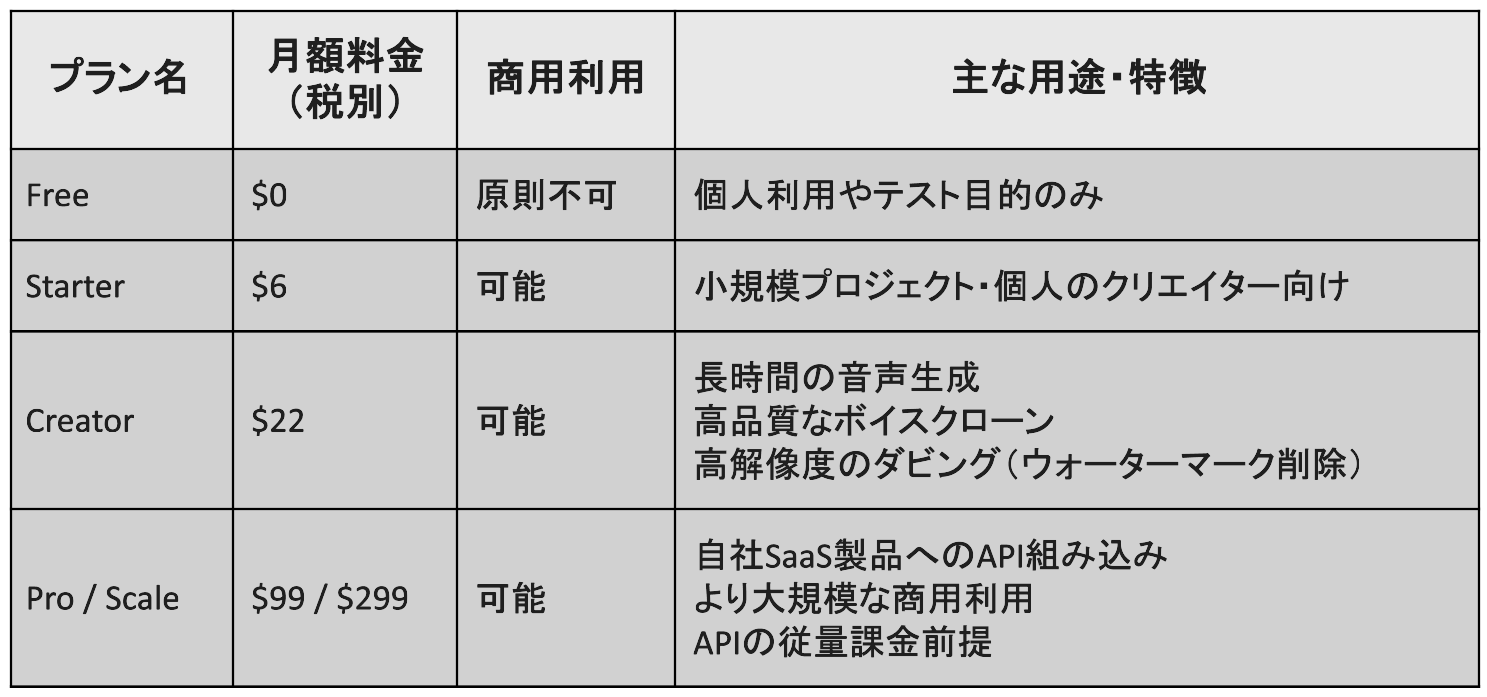
ボイスクローン利用時の権利とルール
ボイスメニューにあるボイスクローン機能を利用して実在の人物の声を再現する場合、厳格な法的・倫理的ルールが適用されます。他人の声を無断でクローンすることは規約違反であり、重大な法的リスクを伴います。
他者の音声をクローンする際は、必ず対象となる本人から明確な書面等での許諾を得る必要があります。ElevenLabsのプラットフォーム上でも、アップロードする音声の権利を保有しているか、または適切な許諾を得ていることを確認するプロセスが存在します。商用プロジェクトで声優やタレントの声をクローンする場合は、契約書にAI学習や音声生成に関する利用範囲を明確に記載することが重要です。
生成した画像・音楽・動画の著作権や利用制限
ElevenLabsで生成した各種メディア(画像、音楽、動画)の商用利用については、Starter以上の有料プランに加入していることが前提となります。ただし、生成したメディア素材の取り扱いには一定の制限があります。
生成物を自社のYouTube動画のBGMや挿入画像として使用したり、プロモーション資料の一部として利用することは問題ありません。しかし、生成した音楽トラック単体を「ストックミュージック」として再配布・販売したり、生成画像を素材集としてそのままの形で販売するような行為は、プラットフォームの規約で制限される場合があります。メディアを利用する際は、必ず公式の最新の利用規約を確認し、単体再販に該当しないコンテンツの構成要素として活用するようにしてください。
📝まとめ
本記事では、ElevenLabsのダッシュボード構成から、テキスト読み上げやサウンドエフェクト、フロー機能に至るまでの具体的な使い方を詳しく解説しました。各機能は直感的に操作でき、日本語対応のモデルを活用することで、高い精度の音声や翻訳を実現できます。
また、商用利用を行う際は、FreeプランではなくStarter以上の有料プランへの移行が必要であり、ボイスクローンにおける権利処理やメディアの利用制限といったルールを順守することが重要です。適切な設定とプランを選択し、日々のコンテンツ制作に役立ててみてください。
💡Yoomでできること
Yoomを利用することで、ElevenLabsを活用した音声生成フローだけでなく、日々の様々な業務プロセスを自動化し、手作業による負担を軽減できます。- 音声を翻訳する業務フロー
- 音声のノイズを削除する業務フロー
- 音声ファイルのボイスを変換する業務フロー
音声作成だけでなく、上記のような業務にも追われている方は、Yoomを利用することで重要な業務にあてる時間を生み出せます。ノーコードで設定でき、すぐに利用できるので、ぜひ試してみてください。
- Boxにファイルがアップロードされたら、ElevenLabsで指定言語の音声でダビングして別フォルダに保存する
- Zoomで会議が終了したら、録音からElevenLabsでNoiseを除去してメールで送付する
■概要
動画や音声コンテンツの多言語展開にあたり、ナレーションの作成や差し替えに手間を感じていませんか。手作業での対応は時間がかかるだけでなく、設定ミスなども起こりがちです。このワークフローは、Boxへのファイルアップロードをトリガーに、ElevenLabsのAPIと連携して自動で指定言語の音声へダビングし、別のフォルダへ保存します。これまで手動で行っていた一連の作業を自動化し、コンテンツ制作の効率を高めます。
■このテンプレートをおすすめする方
- BoxとElevenLabsを利用し、動画や音声のダビング作業を手作業で行っている方
- ElevenLabsのAPIを活用し、多言語コンテンツ制作の効率化を検討している方
- コンテンツのグローバル展開に向け、ナレーション作成の自動化を模索している方
■このテンプレートを使うメリット
- Boxにファイルをアップロードするだけでダビングから保存までが完結するため、これまで手作業に費やしていた時間を短縮できます
- 言語設定やファイルの保存先などを自動化することで、手作業による設定ミスやファイル取り違えといったヒューマンエラーを防ぎます
■フローボットの流れ
- はじめに、BoxとElevenLabsをYoomと連携します
- トリガーでBoxを選択し、「フォルダにファイルがアップロードされたら」アクションを設定します
- オペレーションで、まずBoxの「ファイルをダウンロード」アクションを設定します
- 次に、ElevenLabsの「Dub audio or video files into a specified language」アクションで、ダウンロードしたファイルを処理します
- 続けて、ElevenLabsの「Obtain the dubbed file」アクションで、生成されたファイルを取得します
- 最後に、Boxの「ファイルをアップロード」アクションで、取得したファイルを任意のフォルダに保存します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- Boxのトリガー設定では、ファイルのアップロードを検知したいフォルダを任意で指定してください
- ElevenLabsでのダビング処理では、プロジェクト名やダビングしたい音声の言語などを自由に設定できます
- ダビング後にBoxへファイルをアップロードする際、保存先のフォルダやファイル名を任意で設定することが可能です
■注意事項
- Box、ElevenLabsのそれぞれとYoomを連携してください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細はこちらをご参照ください。
■概要
Zoom会議の録音ファイルを共有する際、周囲の雑音などが気になった経験はないでしょうか。手作業でファイルをダウンロードし、ツールを使ってノイズを除去し、メールで共有するプロセスは手間がかかります。
このワークフローを活用すれば、Zoomでの会議終了をきっかけに、ElevenLabsによる音声ファイルのノイズ除去から共有までを自動で完結できます。手作業による手間を減らし、クリアな音声データをスムーズに関係者へ共有することが可能です。
■このテンプレートをおすすめする方
- Zoom会議の録音データを、より聞き取りやすい状態で関係者に共有したいと考えている方
- ElevenLabsを活用し、音声ファイルのノイズ除去を自動で行いたいと考えている方
- 会議後の録音ファイルのダウンロードやメール送付といった定型業務を効率化したい方
■このテンプレートを使うメリット
- 会議終了後、録音ファイルの取得からElevenLabsでのノイズ除去、メール共有までが自動化されるため、これまで手作業に費やしていた時間を短縮できます。
- ファイルのダウンロード忘れやメールの送信間違いといったヒューマンエラーを減らし、確実な情報共有の実現に繋がります。
■フローボットの流れ
- はじめに、ZoomとElevenLabsをYoomと連携します。
- 次に、トリガーでZoomを選択し、「ミーティングが終了したら」というアクションを設定します。
- 続いて、オペレーションでZoomの「ミーティングのレコーディング情報を取得」アクションを設定します。
- さらに、Zoomの「ミーティングのレコーディングファイルをダウンロード」アクションで録音ファイルを取得します。
- 次に、ElevenLabsの「Audio Noise Removal」アクションを設定し、ダウンロードした音声ファイルのノイズを除去します。
- 最後に、オペレーションの「メールを送る」で、ノイズ除去後のファイルを添付して指定の宛先にメールを送付します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- メールの送信先(To, Cc, Bcc)は、任意のアドレスに設定してください。会議の参加者や特定のチームなど、共有したい相手を自由に指定できます。
- 送付するメールの件名や本文も任意の内容に設定可能です。会議名や日付といった動的な情報を本文に含めることで、より分かりやすい通知を作成できます。
■注意事項
- ZoomとElevenLabsのそれぞれとYoomを連携してください。
- Zoomのプランによって利用できるアクションとそうでないアクションがあるため、ご注意ください。
- 現時点では以下のアクションはZoomの有料プランのみ利用可能です。
- ミーティングが終了したら
- ミーティングのレコーディング情報を取得する(クラウド上に存在するレコーディングのみ取得可能なため)
- 詳細は「Zoomでミーティングのレコーディング情報を取得する際の注意点」をご参照ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
【出典】
プログラミング知識なしで手軽に構築できます。



