








・
Google ImagenとStable Diffusionを徹底比較|画質・料金・商用利用の違いを解説

画像生成AIの技術は日々進化を続けており、ビジネスの現場やクリエイティブな制作活動において、その存在感はますます大きくなっています。
特に「Google Imagen」と「Stable Diffusion」は、それぞれ異なる強みを持つ代表的なAIモデルとして注目されています。
しかし、実際に導入を検討する際、「自社の目的にはどちらが適しているのか」「コストや商用利用の条件はどうなっているのか」といった疑問を持つ方も多いのではないでしょうか。
本記事では、これら2つの主要な画像生成AIについて、画質、料金体系、そして商用利用の権利関係といった重要なポイントを徹底比較します。
さらに、実際に両方のツールを使用して検証した結果をもとに、それぞれの特性を活かしたおすすめの選び方を解説します。
✍️Google ImagenとStable Diffusionの特徴
まずは、今回比較する2つの画像生成AI、「Google Imagen」と「Stable Diffusion」の基本的な特徴と、それぞれの背景にある開発思想について解説します。
Google Imagenの特徴
Google Imagenは、Googleが開発した高性能なText to Imageの拡散モデルです。
主にGoogle CloudのVertex AIプラットフォームを通じて提供されており、エンタープライズ(企業)向けの利用を強く意識して設計されています。
そのため、高いセキュリティ基準やスケーラビリティを備えているのが大きな特徴です。
Imagenは、Googleが持つ膨大なデータと強力な言語モデル(LLM)の技術を活かし、入力されたプロンプト(指示文)の意味を深く理解することに長けています。
これにより、フォトリアリスティックで高品質な画像の生成が可能であり、特に従来の画像生成AIが苦手としていた「画像内への正確な文字の描画」において優れた性能を発揮します。
また、Googleのエコシステムとの親和性が高く、他のGoogleサービスと連携しやすい点もメリットです。
Stable Diffusionの特徴
Stable Diffusionは、Stability AI社が開発し、そのモデルの重み(ウェイト)が公開されているオープンウェイトの画像生成AIです。
この「オープン」という性質が最大の特徴であり、世界中の開発者やクリエイターがモデルの改良や追加学習(ファインチューニング)を行っています。
ユーザーは、Stability AIが提供するAPIを利用するだけでなく、自身のPC(ローカル環境)にモデルをダウンロードして実行することも可能です。
これにより、インターネット接続がない環境での利用や、機密性の高い画像を外部に出さずに生成するといった運用ができます。
また、特定の画風やキャラクターを学習させた追加モデル(LoRAなど)が数多く存在し、非常に高いカスタマイズ性と自由度を誇ります。
🖊️徹底比較:画質・文字生成・プロンプト追従性

画像生成AIを選ぶ上で重要な要素が、生成される画像のクオリティとコントロール性です。
ここでは、画質、文字生成能力、そしてプロンプトへの忠実度という観点から比較します。
文字描写とプロンプト理解力の違い
Imagenは、Googleの言語モデル技術が背景にあるため、プロンプトの理解力において高い性能を示します。
特に「アルファベットの文字描写」に関しては、業界トップクラスの実力を持っています。
例えば、「カフェの看板に『Coffee Time』と書かれている」という指示を出した場合、Imagenはスペルミスなく、自然なフォントと配置で文字を描画する傾向があります。
一方、Stable Diffusionも旧来のモデルに比べれば向上していますが、Imagen 4の安定感にはまだ及ばない場面が見られます。
文字が崩れたり、意味不明な記号の羅列になったりすることがあり、正確な文字描写が必要な場合は、何度も再生成を行うか、生成後の画像編集が必要になることがあります。
画風の調整と自由度の違い
画風の調整に関しては、Stable Diffusionがより優れています。
Stable Diffusionは、ユーザーがモデル自体を微調整したり、特定の画風に特化した追加学習モデル(LoRA)を適用したりすることが簡単です。
これにより、アニメ調、水彩画風、実写風、特定のアーティスト風など、無限に近いバリエーションの画風を意図的に作り出すことができます。
対してImagenは、基本モデル自体が高品質で汎用的な画作りを目指しているため、極端な画風の変更や、ニッチなスタイルの再現には工夫が必要です。
プロンプトで詳しく指示することで画風を変えることは可能ですが、Stable Diffusionのようにモデルレベルで画風を固定するような使い方は難しく、あくまで「汎用的で美しい画像」を生成することに主眼が置かれています。
⭐Yoomは画像生成業務を自動化できます
画像生成AIは、単体で使用するだけでなく、他のツールと連携させることでその真価を発揮します。
Yoomは、様々なSaaSやAIツールをノーコードで連携させ、業務フローを自動化するプラットフォームです。
例えば、記事のタイトルや見出しをGoogle スプレッドシートに入力すると、Yoomが自動的に画像生成AIに指示を出し、生成されたアイキャッチ画像をGoogle Driveに保存できます。
また、フォームで送信された内容をもとに画像を生成し、指定のフォルダに保存することも可能です。
簡単な設定ですぐに自動化を導入できるので、気になる方は試してみてください。
- OpenAIで生成した画像をGoogle Driveにアップロードし、効率的に管理したい方
- Google スプレッドシートのリストを基に、複数の画像を自動で生成、整理したい方
- 画像生成からファイル管理までの一連のタスクを自動化し、作業時間を短縮したい方
- Google スプレッドシートへの入力だけでOpenAIの画像生成からGoogle Driveへのアップロードまでが自動化され、手作業の時間を削減できます。
- 手動でのアップロード作業が不要になるため、ファイルの格納忘れやプロンプトの指定ミスといったヒューマンエラーの防止に繋がります。
- はじめに、Google Drive、Google スプレッドシート、OpenAIをYoomと連携します。
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します。
- 次に、オペレーションでOpenAIの「テキストから画像を生成する」アクションを設定します。
- 続けて、オペレーションでRPA機能の「ブラウザを操作する」アクションを設定します。
- 最後に、オペレーションでGoogle Driveの「ファイルをアップロードする」アクションを設定し、前のステップで準備したファイルをアップロードします。
- Google スプレッドシートのトリガー設定では、連携対象としたい任意のスプレッドシートIDとタブ名を設定してください。
- OpenAIで画像を生成するアクションでは、出力したい画像のサイズを任意の値に設定してください。
- Google Driveにファイルをアップロードするアクションでは、格納先としたい任意のフォルダIDを設定してください。
- OpenAI、Google スプレッドシート、Google DriveのそれぞれとYoomを連携してください。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ブラウザを操作するオペレーションはサクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプラン・チームプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやブラウザを操作するオペレーションを使用することができます。
- ブラウザを操作するオペレーションの設定方法は「『ブラウザを操作する』の設定方法」をご参照ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- Leonardo AIで生成した画像のダウンロードや管理に手間を感じているコンテンツ制作者の方
- マーケティングや資料作成などで、定型的な画像を効率的に生成したいと考えている方
- フォームへの入力を起点に、Leonardo AIでの画像生成から格納までを自動化したい方
- フォーム入力からLeonardo AIでの画像生成、OneDriveへのアップロードまでが自動化され、手作業による画像ダウンロードなどの時間を削減できます。
- 手動での作業による、画像のダウンロード忘れや保存先の間違いといったヒューマンエラーの防止に繋がります。
- はじめに、Leonardo AIとOneDriveをYoomに連携します。
- 次に、トリガーでフォームトリガーを選択し、画像生成に必要な情報を入力するためのフォームを設定します。
- 次に、オペレーションでLeonardo AIの「画像を生成する」アクションを設定し、フォームの回答を基に画像を生成します。
- 次に、「生成情報を取得する」アクションと「処理繰り返し」を組み合わせ、画像生成が完了するのを待ちます。
- 次に、Leonardo AIの「生成された画像をダウンロードする」アクションを設定します。
- 最後に、OneDriveの「ファイルをアップロードする」アクションで、ダウンロードした画像を任意のフォルダに格納します。
■このワークフローのカスタムポイント
- フォームトリガーで設定するフォームのタイトルや質問項目は、ユーザーの業務に合わせて任意で編集が可能です。例えば、「生成したい画像のテーマ」や「画像のスタイル」などを質問項目として追加できます。
- OneDrive、Leonardo AIのそれぞれとYoomを連携してください。
- 「同じ処理を繰り返す」オペレーション間の操作は、チームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションやデータコネクトはエラーとなりますので、ご注意ください。
- チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
🤔【検証】実際に生成して比較:フォトリアルさと文字入れ能力

ここでは、実際に「Imagen」と「Stable Diffusion」を使用して、同じテーマで画像を生成し、その結果を比較検証します。
検証のポイントは「フォトリアルな描写」と「文字入れの精度」の2点です。
検証条件
検証では、それぞれ以下のプラットフォームを利用しました。
- Imagen:Flow
- Stable Diffusion:Stable Diffusion オンライン
検証1:フォトリアルな人物写真
まずは、実写に近い人物写真の生成能力を検証します。
ビジネスシーンで利用できるような、自然な日本人のビジネスマンの画像を生成してみます。
【検証プロンプト】
日本のモダンなオフィスで、窓際に立ってタブレットを操作している30代の日本人男性ビジネスマン。自然光、高解像度、フォトリアリスティック。
【Imagen】
【Stable Diffusion】
検証結果と考察
上記のプロンプトで、以下のように画像が生成されました。
【Imagen】

【Stable Diffusion】

生成された結果から、以下のことがわかりました。
- Google Imagenは細部まで極めてリアルでストックフォトとして実用的な品質
- Stable Diffusionも高画質だが、光や影の描写に不自然さが残る
- 物理法則(影の落ち方や物体の持ち方など)の正確性ではImagenが勝る
Imagenで生成された画像は、肌の質感や髪の毛のディテール、オフィスの背景などが非常にリアルに表現されており、一見してAI生成とは分からないレベルの品質でした。
特に、自然光の当たり方や影の落ち方が極めて自然であり、そのままビジネス用のストックフォトとして十分に活用できるクオリティを誇ります。
一方で、Stable Diffusionも全体として非常に高品質な画像を生成できましたが、細部を観察すると不自然な点が見受けられました。
たとえば、人物の影に対して窓枠の影が薄すぎたり、手に持っているはずのタブレットが宙に浮いていたりするなど、物理法則を無視した描写となっていました。
結論として、単純な人物像の美しさや高画質さではどちらも優秀ですが、周囲の環境や物理的な正確さを考慮した実写レベルの画像生成においては、Imagenに軍配が上がる結果となりました。
検証2:文字入り看板の生成
次に、AIが苦手とする「文字入れ」の能力を検証します。
カフェの看板に特定の日本語と英語のテキストを表示させるよう指示します。
【検証プロンプト】
おしゃれなカフェの入り口にある木製の看板。看板には「Fresh Coffeeあります!」という文字が大きくはっきりと書かれている。周囲には観葉植物。高画質。
【Imagen】
【Stable Diffusion】
検証結果と考察
上記のプロンプトで、以下のように画像が生成されました。
【Imagen】
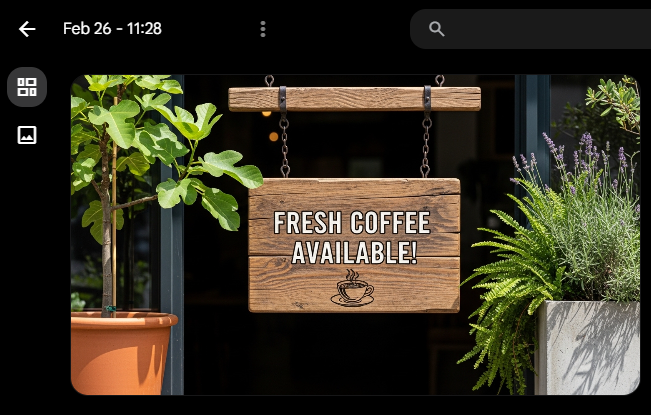
【Stable Diffusion】

生成された結果から、以下のことがわかりました。
- アルファベット(英語)の文字入れは、両モデルとも高い精度で可能
- 日本語の文字入れは現状どちらのモデルも困難
- 正確な日本語を入れるなら生成後に画像編集ソフトを使うのが確実
看板への文字入れを検証した結果、アルファベットの処理性能に関しては、Google ImagenとStable Diffusionのどちらも非常に高く、実用的なレベルであることが確認できました。
英語をそのままデザインに組み込む用途であれば、両者とも大いに活躍します。
しかし、日本語の描写については依然としてハードルが高いと言わざるを得ません。
Imagen4は日本語の処理性能が旧モデルと比べて向上しているものの、「Fresh Coffee Available」と勝手に英語へ翻訳して描写してしまいました。
一方のStable Diffusionは日本語の出力に挑戦したものの、「あります」が「まます」と崩れてしまい、あと一歩及ばない結果となりました。
画像生成AIは英語の学習データが圧倒的に多いため、日本語の処理を苦手としています。
現状、正確な日本語のテキストを入れたい場合は、AIで背景画像を生成した後、画像編集ソフトを利用して文字入れを行うのが最も確実な運用方法と言えます。
✅徹底比較:料金体系とコスト

導入を検討する際、ランニングコストは避けて通れない問題です。
両者の料金体系は大きく異なるため、利用頻度や環境に合わせて比較する必要があります。
Imagenの料金構造
Imagenは、主にGoogle CloudのVertex AIプラットフォーム経由で利用する場合、生成した画像の枚数に応じた従量課金制となります。
初期費用はかかりませんが、生成枚数が増えればリニアにコストが増加するため、予算管理が必要です。
料金はモデルのグレードによって異なります。
-
Imagen 4 Fast:$0.02/枚
高速かつ低コストなモデルで、大量生成やドラフト作成に向いています。 -
Imagen 4 Standard:$0.04/枚
画質と速度のバランスが取れた標準モデルです。 -
Imagen 4 Ultra:$0.06/枚
最高画質を誇るモデルでプロフェッショナルな用途向けです。
Stable Diffusionの料金構造
Stable Diffusionの料金体系は、どのように利用するか(提供形態)によって大きく変わります。
-
ローカル環境での利用
高性能なGPUを搭載したPCを自前で用意できる場合、Stable Diffusionのモデル自体は無料でダウンロード・利用できます。
生成にかかるコストはPCの電気代のみとなり、実質的なランニングコストは非常に低く抑えられます。
生成枚数を気にせず試行錯誤できるのが最大のメリットです。 -
Stability AI APIの利用
Stability AI社が提供するAPIを利用する場合、クレジット制の従量課金となります。
モデルや設定により消費クレジットは変動しますが、0.9クレジット(1クレジット=$0.01)から利用可能です。
サーバー管理の手間がなく、最新モデルを利用できるメリットがあります。
大量に生成する予定があり、ハードウェアへの初期投資が可能ならローカル環境が最も安上がりですが、手軽に導入したい場合はAPI利用やクラウドサービスの利用が現実的です。
💰徹底比較:商用利用とライセンス

ビジネスで画像生成AIを利用する場合、著作権や商用利用の可否は法的なリスクに関わる重要な問題です。
ここでは、それぞれのライセンス形態について解説します。
プラットフォームによる規約の違いと重要性
まず大前提として、画像生成AIを利用できるプラットフォームは多岐にわたり、それぞれ利用規約が異なるという点に注意が必要です。
例えば、Stable Diffusionというモデル自体は同じでも、それを「ローカル環境」で動かす場合、「Stability AI社のAPI」で動かす場合、あるいは「サードパーティ製の画像生成サービス」で動かす場合で、商用利用の可否や生成物の権利の扱いが異なることがあります。
同様にImagenも、Vertex AI経由とその他のツール経由で規約が異なる可能性があります。
必ず利用するプラットフォームごとの最新の利用規約(Terms of Service)を確認してください。
Google Imagen (Vertex AI) の商用利用
Google CloudのVertex AIを通じてImagenを利用する場合、一般的に「入力および出力(生成物)の権利をGoogleが主張しない」とされています。
Googleは、ユーザーが生成した画像をGoogleのモデル学習に勝手に利用しないことを規約で明示している場合が多く、企業にとっては安心して利用できるポイントです。
商用利用も可能ですが、Googleは生成AIの透明性を確保するため、生成された画像に電子透かし技術「SynthID」を埋め込むことがあります。
これは人間の目には見えませんが、ツールを使えばAI生成であることを判別できます。
また、生成物を公開する際には、AIによって生成されたものであることを表示することが推奨されています。
Stable Diffusion (Community License) の権利関係
Stable Diffusion 3以降の新しいモデルでは、「Stability AI Community License」というライセンス形態が採用されています。
このライセンスでは、年間の総収益(または資金調達額)が100万ドル(約1.5億円)未満の個人や企業であればモデルを直接商用利用する場合(生成物を売る、サービスに組み込む等)であっても無料で利用可能です。
一方で、年商が100万ドルを超える企業が商用利用する場合には、「Enterprise License」という有料の契約が必要になります。
また、モデルのバージョン(SDXL、SD1.5など)によってライセンス形態が異なる点に注意が必要です。
このように、企業の規模やモデルのバージョンによって権利関係が変わるため、特に成長中のスタートアップや大企業が導入する際は、自社の売上規模と照らし合わせて契約形態を確認する必要があります。
なお、権利自体はライセンスを遵守する限りユーザーに帰属します。
💡実際に使ってみて分かったおすすめの選び方

画質、料金、ライセンスの違いを踏まえ、実際に両方のツールを使用して感じた「どのようなケースでどちらを選ぶべきか」の指針をまとめました。
Imagenを選ぶべきケース
-
企業として安全かつ手軽に導入したい場合
Google Cloudの堅牢なセキュリティ基盤上で動作し、権利関係もクリアであるため、コンプライアンスを重視する企業に最適です。 -
デザイン素材として英語の文字入り画像が必要な場合
ポスター、バナー、パッケージデザインのラフなど、文字情報を含む画像を生成したい場合、Imagenの文字描写力は強力な武器になります。 -
プロンプトだけで高品質な結果が欲しい場合
複雑なパラメータ調整や呪文のようなプロンプトを駆使しなくても、自然言語の指示だけで意図を汲み取ってくれるため、AI操作に慣れていないメンバーでも扱いやすいツールです。
Stable Diffusionを選ぶべきケース
-
コストを気にせず大量に生成したい場合
ローカル環境を構築できれば、生成枚数による課金を気にする必要がありません。
納得いくまで何度でも試行錯誤したいクリエイターや研究開発に向いています。 -
特定のキャラクターや画風を固定したい場合
LoRAなどの追加学習機能を使えば、自社キャラクターや特定のイラストレーター風の画風をモデルに学習させ、一貫性のある画像を生成し続けることができます。 -
検閲なしで自由に生成したい場合
クラウドベースのサービスでは生成できないような表現(例えば、暴力的な表現や成人向けコンテンツなどではなく、単にプラットフォームの安全フィルターに引っかかりやすい芸術的な表現など)も、ローカル環境であれば自己責任の範囲で生成可能です。
📉まとめ
本記事では、ImagenとStable Diffusionについて、画質、料金、商用利用の観点から比較しました。
Imagenは「企業向けの信頼性」「高い英語描写力」「容易な操作性」が強みであり、ビジネスシーンでの即戦力として期待できます。
一方、Stable Diffusionは「圧倒的なカスタマイズ性」「ローカル運用による低コスト」「コミュニティによる拡張性」が魅力で、クリエイティブな自由度を求めるユーザーに適しています。
どちらのツールも一長一短があり、正解は1つではありません。
自社のビジネス規模、利用目的、そして誰が使うのか(エンジニアか、デザイナーか、マーケターか)を考慮して選定することが重要です。
また、単にツールを導入するだけでなく、Yoomのような自動化プラットフォームと組み合わせることで、画像生成AIのポテンシャルを最大限に引き出し、業務変革につなげてみてはいかがでしょうか。
⭐Yoomでできること
記事の中盤でも触れましたが、Yoomを活用することで、画像生成AIを業務フローにシームレスに組み込むことができます。
API連携の知識がない方でも、直感的なインターフェースで自動化フローを構築できるのがYoomの魅力です。
ECサイトの商品画像を自動で生成したり、イベント告知画像の作成と共有を自動化したりするなど、さまざまな自動化フローを構築できるので、ぜひ試してみてください。
■概要
Shopifyで新しい商品を登録するたびに、商品画像を準備する作業に手間がかかっていませんか?特に、多くの商品を扱うECサイトでは、画像作成や管理が大きな負担になることもあります。
このワークフローを活用すれば、Shopifyへの商品登録をトリガーに、OpenAIが自動で画像を生成し、その結果を指定のGoogle スプレッドシートに記録するため、こうした課題をスムーズに解消できます。
■このテンプレートをおすすめする方
- Shopifyでの商品登録と画像作成を手作業で行っており、効率化したいEC担当者の方
- Shopifyの運用で、商品画像の生成を自動化したい方
- 商品画像の作成コストや管理の手間を削減し、コア業務に集中したいストアオーナーの方
■このテンプレートを使うメリット
- Shopifyへの商品登録を起点に画像生成から記録までが自動化されるため、これまで手作業で対応していた時間を短縮できます
- 生成された画像のURLや関連情報が自動でGoogle スプレッドシートに集約されるため、情報管理が容易になり、確認漏れなどを防げます
■フローボットの流れ
- はじめに、Shopify、OpenAI、Google スプレッドシートをYoomと連携します
- 次に、トリガーでShopifyを選択し、「商品情報が作成されたら(Webhook)」というアクションを設定します
- 次に、オペレーションでOpenAIの「テキストから画像を生成する」アクションを設定し、Shopifyから取得した商品情報を基に画像を生成します
- 最後に、オペレーションでGoogle スプレッドシートの「レコードを追加する」アクションを設定し、商品情報と生成された画像のURLなどを指定のシートに記録します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- OpenAIの画像生成アクションでは、プロンプト(指示文)を自由にカスタマイズできます。Shopifyから取得した商品名などの情報を変数としてプロンプトに含めることで、商品に合わせた画像を生成することが可能です
- Google スプレッドシートへの記録アクションでは、出力先のスプレッドシートやシート、書き込む列などを任意で設定できます。既存の商品管理シートなど、用途に応じた場所に情報を記録してください
■注意事項
- Shopify、OpenAI、Google スプレッドシートのそれぞれとYoomを連携してください。
- Shopifyはチームプラン・サクセスプランでのみご利用いただけるアプリとなっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションやデータコネクトはエラーとなりますので、ご注意ください。
- チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリを使用することができます。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- Discordでのブレインストーミングを、より円滑に進めたいチームリーダーの方
- OpenAIのAPIを利用した画像生成の自動化に興味がある企画担当者や開発者の方
- テキストベースの指示から素早く参考画像を生成し、チームに共有したいと考えている方
- Discordへの投稿から画像生成、共有までが自動化されるため、ツール間の移動や手動操作の時間を短縮し、スムーズなアイデア共有が可能になります。
- 画像生成のフローが標準化されるため、誰でも手軽にイメージを具体化でき、デザインや企画に関する議論の質の向上に繋がります。
- はじめに、DiscordとOpenAIをYoomと連携します。
- 次に、トリガーでDiscordを選択し、「チャンネルでメッセージが送信されたら」というアクションを設定します。
- 次に、オペレーションで分岐機能を設定し、特定のキーワードを含むメッセージを受信した場合のみ、後続の処理に進むよう設定します。
- 続いて、オペレーションでOpenAIを選択し、「テキストから画像を生成する」アクションを設定し、プロンプトとしてDiscordのメッセージ内容を指定します。
- 最後に、オペレーションで再度Discordを選択し、「メッセージを送信」アクションを設定し、生成された画像のURLを元の投稿のスレッドに送信します。
- Discordのトリガー設定では、メッセージを監視する対象のサーバーIDやチャンネルIDを任意で設定してください。
- 分岐機能では、特定のキーワード(例:「/generate」)を含む投稿のみを対象とするなど、後続の処理に進むための条件を自由にカスタマイズできます。
- OpenAIのアクションでは、画像生成の基になるプロンプトをカスタマイズでき、Discordで取得したメッセージ内容を変数として利用することが可能です。
- Discordへの通知アクションでは、通知先のチャンネルやスレッドを任意に設定したり、本文に固定テキストや前段のオペレーションで取得した値を組み込んだりできます。
- Discord、OpenAIのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 分岐はパーソナルプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- パーソナルプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。詳しくは、料金プランのページをご参照ください。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- 詳しくはOpenAIの「API料金」ページをご確認ください。
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
【出典】
Vertex AI の料金 | Google Cloud/Generate and edit images on Vertex AI/Introducing Stable Diffusion 3.5 — Stability AI/Stability AI License/SynthID — Google DeepMind/Pricing/Stable Diffusion オンライン/Flow is an AI creative studio, built with and for creatives Create, refine, and compose your videos, images, and stories with Google's most advanced AI models.
プログラミング知識なしで手軽に構築できます。



