








・
思い通りの画像を作る!画像生成AIのプロンプト完全ガイド

画像生成AIの技術が急速に進化し、テキストを入力するだけで誰でも簡単に高品質なイラストや写真を作り出せるようになりました。
しかし、実際に試してみると「自分の思い描いていたイメージと違う」「不自然な画像になってしまう」といった悩みを抱える方も少なくありません。
この原因の多くは、AIに対する指示文である「プロンプト」の書き方にあります。
プロンプトは画像生成AIにおける設計図のようなものであり、その精度が完成する画像のクオリティを大きく左右します。
本記事では、画像生成AIのプロンプトの基本から、思い通りの画像を生成するための具体的な書き方、そして実践的なテクニックまでを詳しく解説します!
🔍画像生成AIにおけるプロンプトとは?

画像生成AIを利用する上で必ず耳にする「プロンプト」という言葉。
ここでは、その基本的な意味や仕組み、生成される画像に与える影響について詳しく解説します。
1.プロンプトが果たす役割と仕組み
画像生成AIにおけるプロンプトとは、AIに対して「どのような画像を生成してほしいか」を伝えるためのテキストデータのことを指します。
例えば「公園で走る犬」や「未来的な都市の夜景」といった言葉を入力することで、AIはそのテキストを解析し、合致する画像を生成します。
つまり、プロンプトはAIに対する「指示書」や「レシピ」のような役割です。内容が具体的であるほど、AIはユーザーの意図を正確に汲み取り、理想に近い画像を出力できます。
2.プロンプトの質が画像に与える影響
プロンプトの質は、生成される画像のクオリティや正確性に直接的な影響を与えます。
プロンプトの情報量が少なかったり、表現が曖昧だったりすると、AIは独自の解釈で画像を補完するため、意図しない結果になることが多々あります。
例えば、「海」とだけ入力した場合、AIは砂浜の風景を描くのか、荒波を描くのか、あるいは海中の景色を描くのかをランダムに決定してしまいます。しかし、「夕焼けの美しい静かな砂浜に打ち寄せる穏やかな波」と詳細に記述することで、AIの解釈の幅を狭め、自分が求めているイメージ通りの画像を生成することができます。
このように、プロンプトは画像生成における最重要の要素と言えます。
📖思い通りの画像を生成するための基本要素

イメージ通りの画像を生成するためには、プロンプトにいくつかの重要な要素を盛り込む必要があります。
ここでは、被写体から背景まで、プロンプトを構成する4つの基本要素について解説します。
①被写体を明確にする
まず、最も重要なのは「被写体(主題)」を明確にすることです。
誰が、あるいは何がメインの対象なのかをはっきりとさせます。
例えば「猫」だけでなく「三毛猫」や「黒い子猫」など、対象をできる限り絞り込むことが大切です。主役が曖昧なままだと、背景や装飾に埋もれてしまう可能性があります。
②視点や構図を指定する
次に、「視点や構図(アングルやカメラ位置)」を指定します。
「クローズアップ」「俯瞰(上からの視点)」「ローアングル」といったカメラの動きや視点を加えることで、画像にダイナミズムや特定の意図を持たせることができます。
まるでプロのカメラマンが撮影したかのような臨場感を出したい場合は、このカメラワークの指定が非常に大きな役割を果たしてくれます。
③画風や描写を伝える
「画風や描写(テイスト、色彩、スタイル)」を伝えることも欠かせません。
写真のようなリアルな画像が欲しいのか、それともイラスト風、あるいは特定の画家のようなタッチにしてほしいのかを指定します。「パステルカラー」「モノクロ」「4K高画質」などのキーワードが有効です。
これにより、同じ構図でも全く異なる印象を与える作品へと生まれ変わります。
④背景や環境、文脈情報を追加する
最後に、「背景や環境、文脈情報」を追加します。
被写体がどのような場所にいて、何をしているのか、周囲の環境はどうなっているのかを補足することで、AIはより背景と調和した説得力のある画像を生成してくれます。
例えば「コーヒーを飲む女性」だけでなく、「ヨーロッパのオープンカフェで、朝日を浴びながらコーヒーを飲む女性」と文脈を足すことで、ストーリー性のある一枚に仕上がります。
⭐Yoomは画像生成やプロンプト作成業務を自動化できます
Yoomは、日常の業務を自動化し、生産性を劇的に向上させることができるノーコードツールです。画像生成AIと他の業務アプリを連携させることで、例えば「フォームで送信されたテーマをもとにAIワーカーで画像生成して商用利用の可否を自律判定し通知する」といった、業務の安定性を高める自動化フローを簡単に構築できます。
[Yoomとは]
以下のような自動化が可能です。
気になる方はぜひチェックしてみてくださいね👀
■概要画像生成AIの活用において、プロンプトの考案や生成画像の商用利用可否の確認といった作業に時間を要していませんか? このワークフローを活用すれば、フォームにテーマを送信するだけで、AIエージェント(AIワーカー)が自律的にプロンプトを生成し、画像を作成、さらに商用利用の可否まで判定して通知します。属人化しがちなクリエイティブ業務を標準化し、手軽に質の高い画像を生成できる体制を構築できます。■このテンプレートをおすすめする方- AIエージェントを活用して、WebサイトやSNS投稿用の画像生成を効率化したいマーケティング担当者の方
- チームからの画像生成依頼をフォームで受け付け、制作プロセスを自動化したいと考えている方
- 画像生成AIのプロンプト考案や商用利用の確認作業を自動化し、属人化を解消したい方
■このテンプレートを使うメリット- フォーム送信を起点に画像生成から商用利用の判定、通知までが自動処理されるため、手作業の時間を短縮できます
- AIエージェント(AIワーカー) がプロンプト作成などを担うため、担当者のスキルに依存しない標準化された画像生成フローが構築できます
■フローボットの流れ- はじめに、OpenAIとDiscordをYoomと連携します
- 次に、トリガーでフォームトリガーを選択し、画像生成のテーマや要望を受け付けるためのフォームを設定します
- 最後に、オペレーションでAIワーカーを設定し、フォームで受け取った内容をもとに画像生成用のプロンプトを作成し、商用利用の可否を判定した上で、生成された画像と判定結果をDiscordに通知するための指示を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- トリガーとして設定するフォームでは、画像生成の依頼で受け付けたい内容に合わせて、質問項目を任意で設定することが可能です
- AIワーカーに与える指示の内容は、生成したい画像のスタイルなどに合わせて変更できます。また、通知先のDiscordアカウントやチャンネルも任意で設定可能です
■注意事項- OpenAI、DiscordのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- 詳しくはOpenAIの「API料金」ページをご確認ください。
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
■概要AIへの指示、いわゆるプロンプトの作成に毎回頭を悩ませていませんか?質の高い回答を得るにはコツが必要であり、作成に時間がかかることもあります。このワークフローは、Googleフォームに入力された内容をもとに、AIが自動でプロンプトを最適化する、まるで優れたAIプロンプト 作成ツールのような役割を果たし、誰でも質の高いプロンプトを効率的に生成できるようになるため、AI活用の幅が広がります。■このテンプレートをおすすめする方- AIへの指示(プロンプト)作成に時間がかかり、効率化したいと考えている方
- チーム内でのAI活用を推進しており、プロンプトの質を標準化したいマネージャーの方
- 手軽に導入できる高機能なAIプロンプト作成ツールを探している方
■このテンプレートを使うメリット- Googleフォームへの入力後、自動でプロンプトが生成されるため、毎回ゼロから考える手間を省き、作業時間を短縮できます。
- プロンプト作成のプロセスが標準化されることで、担当者による品質のばらつきを防ぎ、チーム全体のAI活用レベルの向上に繋がります。
■フローボットの流れ- はじめに、GoogleフォームとSlackをYoomと連携します。
- 次に、トリガーでGoogleフォームを選択し、「フォームに回答が送信されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを起動し、フォームの回答内容をもとにプロンプトを最適化しSlackに通知するためのマニュアル(指示)を作成します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Googleフォームのトリガー設定では、プロンプトのもととなる情報を収集するフォームを任意で設定してください。
- AIワーカーへの指示内容や、通知先として連携するSlackのチャンネルは、運用に合わせて任意で設定が可能です。
■注意事項- Googleフォーム、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Googleフォームをトリガーとして使用した際の回答内容を取得する方法は「Googleフォームトリガーで、回答内容を取得する方法」を参照ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIエージェントを活用して、WebサイトやSNS投稿用の画像生成を効率化したいマーケティング担当者の方
- チームからの画像生成依頼をフォームで受け付け、制作プロセスを自動化したいと考えている方
- 画像生成AIのプロンプト考案や商用利用の確認作業を自動化し、属人化を解消したい方
- フォーム送信を起点に画像生成から商用利用の判定、通知までが自動処理されるため、手作業の時間を短縮できます
- AIエージェント(AIワーカー) がプロンプト作成などを担うため、担当者のスキルに依存しない標準化された画像生成フローが構築できます
- はじめに、OpenAIとDiscordをYoomと連携します
- 次に、トリガーでフォームトリガーを選択し、画像生成のテーマや要望を受け付けるためのフォームを設定します
- 最後に、オペレーションでAIワーカーを設定し、フォームで受け取った内容をもとに画像生成用のプロンプトを作成し、商用利用の可否を判定した上で、生成された画像と判定結果をDiscordに通知するための指示を作成します
■このワークフローのカスタムポイント
- トリガーとして設定するフォームでは、画像生成の依頼で受け付けたい内容に合わせて、質問項目を任意で設定することが可能です
- AIワーカーに与える指示の内容は、生成したい画像のスタイルなどに合わせて変更できます。また、通知先のDiscordアカウントやチャンネルも任意で設定可能です
- OpenAI、DiscordのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- 詳しくはOpenAIの「API料金」ページをご確認ください。
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIへの指示(プロンプト)作成に時間がかかり、効率化したいと考えている方
- チーム内でのAI活用を推進しており、プロンプトの質を標準化したいマネージャーの方
- 手軽に導入できる高機能なAIプロンプト作成ツールを探している方
- Googleフォームへの入力後、自動でプロンプトが生成されるため、毎回ゼロから考える手間を省き、作業時間を短縮できます。
- プロンプト作成のプロセスが標準化されることで、担当者による品質のばらつきを防ぎ、チーム全体のAI活用レベルの向上に繋がります。
- はじめに、GoogleフォームとSlackをYoomと連携します。
- 次に、トリガーでGoogleフォームを選択し、「フォームに回答が送信されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを起動し、フォームの回答内容をもとにプロンプトを最適化しSlackに通知するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Googleフォームのトリガー設定では、プロンプトのもととなる情報を収集するフォームを任意で設定してください。
- AIワーカーへの指示内容や、通知先として連携するSlackのチャンネルは、運用に合わせて任意で設定が可能です。
- Googleフォーム、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Googleフォームをトリガーとして使用した際の回答内容を取得する方法は「Googleフォームトリガーで、回答内容を取得する方法」を参照ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
💻画像生成AI プロンプトの具体例

ここでは、風景、人物、画風の3つのカテゴリに分けて、すぐに使える具体的なプロンプト例を紹介します。
■風景・背景を生成するプロンプト例
風景や背景を生成する場合、時間帯や天候、場所のディテールを詳細に記載することがポイントです。さらに、カメラアングルや光の方向、描写したい雰囲気まで描き込むと、より完成度の高いビジュアルが得られます。
【プロンプト例】
・霧に包まれた深い森の中、朝の光が木々の間から差し込む、神秘的な雰囲気
・古いヨーロッパの街並み、石畳の道、カフェのテラス、午後の柔らかな日差し
・春の公園、満開の桜並木、小川に映る花びら、穏やかで夢のような世界
■人物・キャラクターを生成するプロンプト例
人物やキャラクターを生成する際は、外見の特徴だけでなく、表情や服装、ポーズまで細かく指定しましょう。加えて、照明の種類(自然光・スタジオライト)や構図の指定を行うと、より狙い通りのスタイルを再現しやすくなります。
【プロンプト例】
・金髪のショートヘアで緑色の瞳を持つ若い女性、アニメスタイル、全身ショット
・笑顔の子ども、風船を持って青空の下で跳ねている、フォトリアル
・スーツ姿の中年男性、コーヒーを手にして物思いにふける、シネマティックライティング
■スタイル・画風を指定するプロンプト例
スタイルや画風の指定も非常に重要です。
「水彩画風」「油絵風」「サイバーパンク」「フォトリアル(写真のようなリアルさ)」といったキーワードをプロンプトに含めることで、全体のテイストをコントロールできます。
また、年代・ジャンルを組み合わせると、作品のムードや質感をさらに明確に表現できます。
【プロンプト例】
・ニューヨークの街並み、サイバーパンク風、ネオンサイン、雨の夜
・近未来の都市、高層ビルとホログラム広告、フォトリアルスタイル、夜景の反射光
・江戸時代の町並み、浮世絵風、和風テクスチャと柔らかい線
🤔【検証】曖昧なプロンプトと具体的なプロンプトを比較してみた

プロンプトの具体性が画像の仕上がりにどれほど影響するのかを、実際にAIを使って検証します。
検証内容は、「非常にシンプルで曖昧なプロンプト」と「細かく条件を指定した具体的なプロンプト」の2パターンを用意し、画像生成AIに入力して仕上がりを比較していきます。
- 使用するツール:ChatGPT
- 検証のテーマ:公園で本を読む少女
まずは、なるべく簡単で曖昧な指示だけを与えてみます。
【パターンA:曖昧なプロンプトの例】
A girl reading a book in a park, illustration(公園で本を読んでいる少女のイラスト)
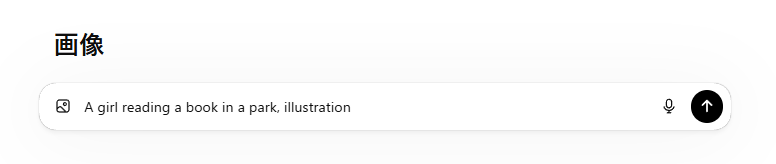
【パターンAの生成結果】
生成された画像は、確かに公園で本を読んでいる様子ですが、女の子の服装や髪型、年齢が一定せず、生成するたびに結果がバラバラでした。
AIが独自の判断で画像を構成しているため、特定のイメージを狙って作り出すことは困難であると断定できます。
1回目

2回目

3回目

次に、具体的な条件を盛り込んだプロンプトを入力しました。
【パターンB:詳細な指示】
A cozy anime-style illustration of a 16-year-old girl reading a book on a wooden bench in a quiet city park in the late afternoon in spring, cherry blossom petals softly falling around her. She has medium-length brown hair with soft waves, wearing a light beige cardigan over a white blouse and a navy pleated skirt. Warm golden sunlight shines from the right, creating gentle shadows. The background shows a few blurred buildings and green trees, with a calm and peaceful atmosphere, soft pastel colors, high detail, 4K.
この詳細な指示には、以下の要素を網羅しています。
- 年齢感:16歳の女の子
- 季節・時間帯:春の夕方
- ロケーション:静かな都会の公園、木製ベンチに座っている
- 見た目:髪型(ミディアム、ゆるいウェーブ)、服装(ライトベージュのカーディガン、白いブラウス、紺のプリーツスカート)
- 光と色:右側からの暖かい黄金色の夕日、やわらかいパステルカラー
- 画風と質感:アニメ風、高精細、4K
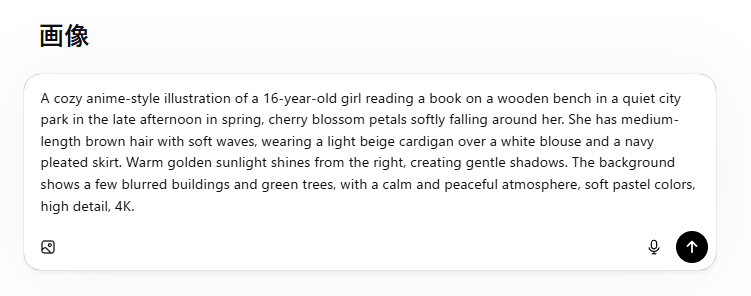
【パターンBの生成結果】
指示した内容が的確に盛り込まれており、女の子の見た目や服装が毎回かなり安定します。
同じキャラクターを登場させたい場合などは、具体的プロンプトの方が「ブランドとして固定化しやすい」という明確なメリットが確認できました。
1回目

2回目

3回目

▼検証まとめ
この比較検証からわかるように、AIはテキストの裏にある意図を推測することはできません。
ユーザーが頭の中に描いているイメージを、どれだけ言語化して具体的に伝えられるかが、画像生成の成功を分ける最大の要因となります。
面倒に感じても、詳細な条件をプロンプトに盛り込み、言語化の精度を高めることが、生成画像のクオリティ向上に直結します。
🪄プロンプト作成で使えるおすすめテクニック

基本を押さえた後は、さらに一歩進んだプロンプト作成のテクニックを活用してみましょう。
ここでは、画像のクオリティをより高めるための3つの実践的な方法を紹介します。
①要素を段階的に追加していく手法
最初から長文のプロンプトを入力するのではなく、まずは「公園で走る犬」のように基本的な被写体と行動だけで生成します。
その結果を確認した上で、「夕暮れ時」という時間を追加し、次に「水彩画風」というスタイルを追加するといった具合に、少しずつプロンプトを育てていく方法です。
これにより、どのキーワードが画像にどのような影響を与えているのかを把握しやすくなり、微調整が可能になります。
1.「公園で走る犬」

2.「公園で走る犬」+「夕暮れ時」

3.「公園で走る犬」+「夕暮れ時」+「水彩画風」

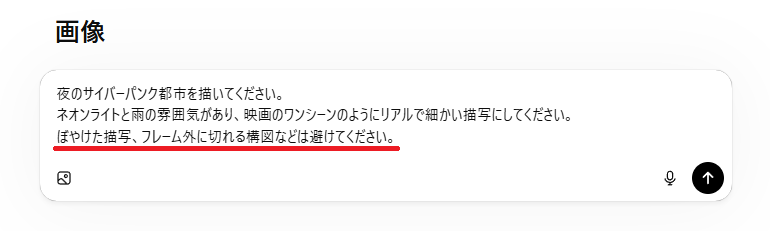
②ネガティブプロンプト(除外したい要素)の活用
これは「描いてほしくない要素」をAIに指示する機能です。
例えば、人物の画像を生成する際に「低画質、不自然な手、ぼやけた背景」などをネガティブプロンプトとして指定することで、画像の品質を底上げし、エラーを減らすことができます。
特に手や指の描写が苦手なAIモデルを使用する際には、このネガティブプロンプトが非常に役立ちます。
なお、Stable DiffusionやFLUXなどの一部モデルでは有効ですが、OpenAIのモデルのように自然言語で指示を出すタイプでは、指示文の中に『〜を描かないで』や『~を避けて』と含める方法が一般的です
③ChatGPTに画像生成用の英語プロンプトを考案させる
三つ目は「文章生成AIにプロンプトを考案させる」という方法です。
英語のプロンプト作成が難しい場合、ChatGPTやGeminiなどのAIに対して「美しい宇宙の風景の画像を生成するための、Midjourney用の詳細な英語プロンプトを5つ考えて」と指示します。
AIが提案してくれた専門的なプロンプトをそのまま画像生成AIに入力するだけで、驚くほど高品質な画像を手に入れることができます。プロンプト作成に行き詰まった時の解決策として非常におすすめです。

⚖️主要な画像生成AIモデルの特徴と使い分け

提供されている画像生成AIには、それぞれ得意とする表現や機能に違いがあります。
ここでは、主要なAIモデルの特徴と、目的に応じたおすすめの使い分けについて解説します。
▼OpenAIの画像生成モデル
OpenAIが提供する「DALL-Eシリーズ」は、ユーザーが入力したプロンプトに対する忠実度が非常に高いのが特徴です。複雑な指示や長文のプロンプトでも、しっかりと内容を理解して画像に反映してくれます。
また、ChatGPTの中で対話しながら画像を生成し、そのまま「ここを修正して」と指示を出せるため、ビジネス資料の挿絵作成やマーケティング素材の制作など、細かい調整が求められるシーンで大いに活躍します。
- DALL-Eシリーズで生成した画像

▼Googleの画像生成モデル
Googleの「Imagenシリーズ」は、非常に高速な生成スピードと、自然言語の文脈を深く理解する能力に長けています。複雑で会話的なプロンプトの意図を汲み取るのが得意であり、Google Workspaceなどの他のツールと連携させやすいのも大きなメリットです。
素早くアイデアを視覚化したい場合や、社内プレゼン用の簡単なイメージ画像を作成する際に便利です。操作感も非常にシンプルで、初心者からビジネスユーザーまで幅広く利用されています。
- Imagenシリーズで生成した画像

▼Fluxシリーズなどオープンソースモデル
「Fluxシリーズ」などのオープンソースモデルは、カスタマイズ性と自由度の高さが魅力です。
自身のPC環境に構築したり、クラウドサービス上で細かくパラメーターを調整したりできるため、特定のキャラクターを固定して生成したい場合や、独自の画風を学習させたいクリエイターに強く支持されています。アニメ調のイラストや、アート性の高い作品を作りたい場合に適しています。
ただし、オープンソースモデルを利用する際は、ライセンス条件の確認が非常に重要です。
モデルの配布形式やバージョンによって、「個人利用は無料だが商用利用にはライセンス契約が必要」といった条件が設けられている場合があります。ビジネスで利用する前には必ず提供元の最新規約を確認しましょう。
- Fluxシリーズで生成した画像

🔊画像生成のプロンプト作成時によくある質問

画像生成AIを使い始めると、言語の選択や文字数など、様々な疑問が浮かんでくるものです。
ここでは、プロンプト作成時によく寄せられる代表的な質問とその回答をまとめました。
📌日本語と英語どちらのプロンプトが良い?
A:基本的には英語での入力が推奨されます。
多くのモデルは多言語に対応しており、日本語でも高い精度で生成可能です。
ただし、AIの学習データの背景から、英語の方がより細かなニュアンスが伝わりやすい場合もあります。まずは日本語で試し、必要に応じて翻訳ツール等を併用するのが効率的です。
📌プロンプトの文字数や長さに制限はある?
A:利用するAIモデルによって異なりますが、一般的には上限が設けられています。
長すぎるプロンプトを入力すると、後半のキーワードが無視されたり、情報が多すぎてAIが混乱し、意図しない画像になったりすることがあります。必要な要素を簡潔にまとめ、重要なキーワードほどプロンプトの前半に配置するといった工夫が効果的です。
伝えたい情報を精査し、無駄のないプロンプトを組み立てるよう心がけましょう。
📌同じキャラクターや構図を、毎回できるだけ同じイメージで生成することはできる?
A:プロンプトを工夫すれば、毎回「まったく同じ」画像ではなくても、かなり近いイメージを安定して再現できます。
AIはランダムなノイズから画像を生成するため、同じプロンプトでも細部は毎回変化します。
ただし、キャラクターの年齢・髪型・服装・ポーズ・画風などを具体的に指定し、毎回同じプロンプトを使うことで、キャラクターや世界観の一貫性を高めることができます。
さらに、対応しているツールであれば「シード値(Seed)」を固定することで、構図や雰囲気をほぼ同じに保ったまま、ポーズ違いなどのバリエーションを作ることも可能です。
🖊️まとめ
画像生成AIを使いこなすためには、プロンプトの理解と工夫が不可欠です。
具体的な指示を心がけ、段階的な調整やネガティブプロンプトの活用、さらには他のAIツールを補助的に使うといったテクニックを駆使することで、あなたの頭の中にあるイメージを正確に視覚化できるようになります。
また、用途に応じて異なるAIモデルを使い分けることで、表現の幅はさらに広がります。
何度か試行錯誤を繰り返すことで、AIとの対話のコツが掴めてくるでしょう!
💡 Yoomでできること
Yoomは、業務を自動化するハイパーオートメーションプラットフォームです。
これまで手動で利用していた各ツールをメインとした自動化フローが、直感的な操作で実現可能です。もし自動化に少しでも興味を持っていただけたなら、ぜひ登録フォームから無料登録して、Yoomによる業務効率化を体験してみてください。
■概要Google スプレッドシートにまとめた情報を元に、手作業で画像を作成する業務に手間を感じていませんか。 このワークフローは、Google スプレッドシートの特定シートに行が追加されると、その情報を基にAIが画像を自動で生成し、指定のGoogle Driveフォルダに保存するまでの一連の流れを自動化します。 Google スプレッドシートの情報を活用した画像生成プロセスを効率化し、定型的なクリエイティブ業務にかかる時間を削減します。■このテンプレートをおすすめする方- Google スプレッドシートのデータに基づき、定期的に画像を生成しているマーケティングや広報担当の方
- AIによる画像生成を活用し、コンテンツ作成業務の効率化や自動化を進めたい方
- 手作業による画像作成の時間的コストや、品質のばらつきに課題を感じている方
■このテンプレートを使うメリット- Google スプレッドシートに行を追加するだけで画像が自動生成されるため、これまで手作業で行っていた画像作成の時間を削減できます。
- プロンプトの指示ミスや保存場所の間違いといった、手作業によるヒューマンエラーを防ぎ、業務の品質を安定させます。
■フローボットの流れ- はじめに、Google DriveとOpenAIをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 次に、オペレーションでAIワーカーオペレーションを選択し、Google スプレッドシートの情報を基にOpenAIで画像を生成するためのマニュアル(指示)を作成します
- 次に、オペレーションでRPA機能を設定し、生成画像をダウンロードします
- 最後に、オペレーションでGoogle Driveの「ファイルをアップロードする」を設定し、ダウンロードした生成画像を格納します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Google スプレッドシートのトリガー設定では、対象としたい任意のスプレッドシートIDとシートのタブ名を設定してください。
- AIワーカーオペレーションでは、利用したい任意のAIモデルを選択し、生成したい画像の内容に合わせた指示を設定してください。
- Google Driveの「ファイルをアップロードする」アクションでは、生成した画像の格納先となるフォルダのIDを任意で設定してください。
■注意事項- Google スプレッドシート、OpenAI、Google DriveのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- ブラウザを操作するオペレーションはサクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプラン・チームプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやブラウザを操作するオペレーションを使用することができます。
- ブラウザを操作するオペレーションの設定方法は「『ブラウザを操作する』の設定方法」をご参照ください。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
■概要アップロードされた画像の目視チェックに、多くの時間と手間がかかっていませんか。 特に、大量の画像を扱う業務では、確認漏れや判断基準のブレといった課題も発生しがちです。 このワークフローを活用すれば、Google Driveに保存された画像をトリガーに、AIによる画像検証の自動化が可能です。検証結果はSlackに通知されるため、一連のチェック業務を効率化し、人的ミスを減らすことに繋がります。■このテンプレートをおすすめする方- Google Driveにアップロードされる大量の画像の目視確認に追われている方
- AIを活用して画像検証を自動化し、チェック業務の精度を高めたい方
- 画像チェック後のSlackへの報告作業を効率化し、コア業務に集中したい方
■このテンプレートを使うメリット- Google Driveへの画像保存を起点に、AIによる検証からSlack通知までが自動で実行されるため、これまで手作業に費やしていた時間を短縮できます
- AIが一定の基準で検証を行うため、目視による確認漏れや判断の揺れといったヒューマンエラーを防ぎ、検証品質の安定化に繋がります
■フローボットの流れ- はじめに、Google DriveとSlackをYoomと連携します
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、アップロードされた画像の検証とSlackへの通知を行うためのマニュアル(指示)を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション■このワークフローのカスタムポイント- Google Driveのトリガー設定では、自動化の起動対象としたいフォルダのIDを任意で設定してください
- AIワーカーオペレーションでは、検証に使用したい任意のAIモデルを選択し、具体的な検証内容やSlackへの通知内容に関する指示を任意で設定してください
■注意事項- Google Drive、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- Google スプレッドシートのデータに基づき、定期的に画像を生成しているマーケティングや広報担当の方
- AIによる画像生成を活用し、コンテンツ作成業務の効率化や自動化を進めたい方
- 手作業による画像作成の時間的コストや、品質のばらつきに課題を感じている方
- Google スプレッドシートに行を追加するだけで画像が自動生成されるため、これまで手作業で行っていた画像作成の時間を削減できます。
- プロンプトの指示ミスや保存場所の間違いといった、手作業によるヒューマンエラーを防ぎ、業務の品質を安定させます。
- はじめに、Google DriveとOpenAIをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 次に、オペレーションでAIワーカーオペレーションを選択し、Google スプレッドシートの情報を基にOpenAIで画像を生成するためのマニュアル(指示)を作成します
- 次に、オペレーションでRPA機能を設定し、生成画像をダウンロードします
- 最後に、オペレーションでGoogle Driveの「ファイルをアップロードする」を設定し、ダウンロードした生成画像を格納します
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー設定では、対象としたい任意のスプレッドシートIDとシートのタブ名を設定してください。
- AIワーカーオペレーションでは、利用したい任意のAIモデルを選択し、生成したい画像の内容に合わせた指示を設定してください。
- Google Driveの「ファイルをアップロードする」アクションでは、生成した画像の格納先となるフォルダのIDを任意で設定してください。
- Google スプレッドシート、OpenAI、Google DriveのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- ブラウザを操作するオペレーションはサクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプラン・チームプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやブラウザを操作するオペレーションを使用することができます。
- ブラウザを操作するオペレーションの設定方法は「『ブラウザを操作する』の設定方法」をご参照ください。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Google Driveにアップロードされる大量の画像の目視確認に追われている方
- AIを活用して画像検証を自動化し、チェック業務の精度を高めたい方
- 画像チェック後のSlackへの報告作業を効率化し、コア業務に集中したい方
- Google Driveへの画像保存を起点に、AIによる検証からSlack通知までが自動で実行されるため、これまで手作業に費やしていた時間を短縮できます
- AIが一定の基準で検証を行うため、目視による確認漏れや判断の揺れといったヒューマンエラーを防ぎ、検証品質の安定化に繋がります
- はじめに、Google DriveとSlackをYoomと連携します
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、アップロードされた画像の検証とSlackへの通知を行うためのマニュアル(指示)を作成します
- Google Driveのトリガー設定では、自動化の起動対象としたいフォルダのIDを任意で設定してください
- AIワーカーオペレーションでは、検証に使用したい任意のAIモデルを選択し、具体的な検証内容やSlackへの通知内容に関する指示を任意で設定してください
- Google Drive、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
プログラミング知識なしで手軽に構築できます。



