








・
Stable Diffusionの著作権・商用利用を徹底解説!安全に使うための検証フロー

「Stable Diffusionで作った画像は、本当に商用利用しても大丈夫?」「著作権侵害で訴えられることはないの?」
画像生成AIの普及に伴い、このような法的な不安を感じている方は多いのではないでしょうか。特にビジネスや副業でAIを活用したいと考えている方にとって、権利関係のルールは死活問題です。特に、2024年以降にリリースされたモデル(SD3, SD3.5など)と、それ以前のモデル(SD1.5, SDXL)では、ルールが大きく異なるため注意が必要です。
この記事では、Stable Diffusionで著作権侵害リスクを回避して、安全に利用するための具体的な検証フローを解説します。法律や規約の難しい話を噛み砕き、明日から安心して画像生成を楽しめるようガイドします。
✍️前提情報

まずは、Stable Diffusionがどのようなサービスなのか、その基本情報を整理しておきましょう。
本記事の想定読者
- Stable Diffusionを業務で利用したい企業の広報・マーケティング担当者
- 生成した画像をブログやSNS、販売物に使用したいクリエイター
- AI生成物の著作権リスクを正しく理解し、安全に運用したい方
Stable Diffusionとは?
Stable Diffusion(ステーブル・ディフュージョン)は、Stability AI社が開発・提供している画像生成AIです。テキスト(プロンプト)を入力することで、高品質な画像を生成できます。
他の多くの画像生成AIと異なり、オープンソースとしてモデルが公開されているため、自身のPC(ローカル環境)にインストールして利用できる点が大きな特徴です。これにより、生成回数の制限を気にせず、プライバシーを保ちながら画像を生成できます。
◎料金プラン
- 個人・小規模事業者(年商100万ドル未満):
基本的に無料で利用可能。商用利用も可能。(モデルのライセンスによる) - 企業(年商100万ドル以上):
Stable Diffusion 3 (SD3) / SD3.5 などの最新世代モデルを利用する場合、Enterpriseプラン(有料)の契約が必要。
※SD1.5やSDXLなどの旧モデルは、ライセンス体系が異なり、引き続き制限なく利用可能な場合が多い。(後述)
※この金額は「年間収益(Annual Revenue)」を指すため、売上高ベースでの判断が必要です。
◎Stable Diffusionのメリット・デメリット
【メリット】
- 高いカスタマイズ性と制御性:
オープンソースであるため、特定の画風を追加学習させたモデル(LoRA)や、構図を固定する拡張機能(ControlNet)などを自由に組み合わせて、理想の画像を追求できます。
- コストパフォーマンス:
ローカル環境を構築すれば、電気代を除き基本無料かつ無制限に画像を生成できます。オンライン版の無料枠でも、簡単な試行であればコストを抑えて利用可能です。
- プライバシーとセキュリティ:
ローカル環境での運用なら、生成プロセスやデータが外部サーバーに送信されないため、機密性の高いビジネス利用に適しています。
- 商用利用の柔軟性:
生成された画像は基本的に商用利用が可能ですが、使用する特定のモデルのライセンス(規約)に従う必要があります。
【デメリット】
- 環境構築とスペックの壁:
ローカル環境で快適に動かすには、高性能なGPU(特にNVIDIA製、VRAM 8GB〜12GB以上。SD3.5 Large等の高性能モデルをフル活用する場合は16GB〜24GB以上を推奨)を搭載したPCが必要です。
初期設定にはGitやPythonの知識が必要で、初心者にはハードルが高い場合があります。
- 著作権・肖像権のリスク:
既存のキャラクターや特定のアーティスト名を含むプロンプトを使用すると、意図せず権利侵害となる画像を生成してしまう恐れがあります。
- 品質の不安定さとスキル習得:
「呪文」と呼ばれるプロンプトの構成スキルがないと、低品質な画像や人体構造が不自然な(指の数がおかしい等)画像が生成されやすく、調整に時間がかかります。
- オンライン版の制限:
Webサービス版(無料枠など)では、生成枚数に上限があったり、詳細なパラメータ設定や拡張機能が使えなかったりと、自由度が大幅に制限されることがあります。
Stable Diffusionの著作権と商用利用の基本
結論から言うと、Stable Diffusionで生成した画像は、必ずしも著作権侵害になるわけではありません。 ただし、「どのように生成したか」によって法的評価は変わります。Stable Diffusionにおける著作権の問題は、大きく分けて次の3点です。
- 生成画像に著作権は発生するのか
- 既存作品との類似があった場合、侵害になるのか
- モデルのライセンスと著作権はどう違うのか
まずは「著作権」の観点から整理していきます。
〈1.生成画像に著作権は発生するのか?〉
日本の著作権法では、「思想または感情を創作的に表現したもの」が著作物と定義されています。 AIが生成した画像については、人間の創作的関与がどの程度あったかが判断基準になります。
例えば、
・単純なワンクリック生成のみの場合→ 著作物性が否定される可能性がある
・構図指定、スタイル設計、詳細なプロンプト調整、複数回の修正を行った場合→ 利用者に著作権が認められる可能性がある
現時点では、ケースバイケースで判断されるのが実務的な理解です。
〈2.Stable Diffusionで著作権侵害は成立するのか?〉
著作権侵害が成立するためには、一般的に次の2つが必要とされています。
- 類似性(既存作品と実質的に似ていること)
- 依拠性(既存作品を参照して制作したこと)
例えば、
・特定のキャラクター名を指定して生成する・実在のアーティスト名を明示する・既存画像をi2iで加工する
このようなケースでは、依拠性が問題になる可能性があります。
一方で、抽象的・一般的なプロンプトで生成された画像については、既存作品への依拠性を立証することは容易ではありません。
つまり、 商用利用が可能かどうかと、著作権侵害になるかどうかは別問題という点を理解しておく必要があります。
〈3.モデルのライセンスと著作権は別物〉
ここで重要なのが、「ライセンス」と「著作権」は別概念であるという点です。
ライセンスとは、モデルをどの条件で利用できるかという契約上のルールです。著作権は、生成物が法的に保護されるか、また侵害にあたるかという法律上の問題です。
Stable Diffusionは、モデルのバージョンによって適用されるライセンスが異なります。
- Stable Diffusion 1.5(SD1.5)/SDXL:ライセンス:CreativeML OpenRAIL系▶企業規模による年商制限は基本的にありません。
- Stable Diffusion 3(SD3)/SD3.5:ライセンス:Stability AI Community License▶年商100万ドルを超える企業は有料契約が必要です。
ここで説明しているのは「利用条件」であり、「著作権侵害の有無」とは直接イコールではありません。
📣Yoomは画像生成AIの管理業務を自動化できます
AIで画像を生成する際、「どのモデル」で、「どんなプロンプト」を使って生成したかを記録しておくことは、著作権トラブルのリスク管理として重要です。
2025年に施行されたAI基本法や、政府が策定した人工知能基本計画により、透明性の確保がより一層重視されるようになりました。この「記録」の重要性は以前にも増して高まっています。しかし、生成するたびにExcelやスプレッドシートに手動で記録するのは手間がかかります。
Yoomを使えば、生成した画像ファイルやプロンプト情報を、Google DriveやNotionなどのデータベースへ自動的に保存・管理できます。これにより、万が一の際の「生成プロセスの証明」をスムーズに行えるようになります。
まずは、以下のテンプレートから自動化を体験してみてください。
■概要
記事コンテンツの作成は、企画、構成案、執筆と多くの工程があり、手間がかかる業務ではないでしょうか。特にアイデア出しや下書き作成に時間がかかり、本来の業務を圧迫することもあります。このワークフローを活用すれば、フォームに情報を入力するだけでGeminiが記事案を自動で生成し、Google Driveに保存までの一連の流れを自動化できます。コンテンツ生成の自動化を実現し、コンテンツ作成業務の効率化を支援します。
■このテンプレートをおすすめする方
- 記事作成のアイデア出しや下書き作成業務の効率化を目指しているコンテンツ担当者の方
- コンテンツ生成の自動化に関心があり、具体的な実現方法を探している方
- GeminiやGoogle Driveを活用し、コンテンツ制作フローを改善したいと考えている方
■このテンプレートを使うメリット
- フォームにキーワードなどを入力するだけで記事案の生成から保存までが完了するため、コンテンツ作成にかかる時間を短縮できます
- 生成AIへの指示(プロンプト)が標準化されるため、担当者による品質のばらつきを防ぎ、属人化の解消に繋がります
■フローボットの流れ
- はじめに、Gemini、Googleドキュメント、Google DriveをYoomと連携します
- 次に、トリガーでフォームトリガー機能を選択し、記事作成に必要な情報を入力するためのフォームを設定します
- 続いて、オペレーションでGeminiを選択し、フォームで受け取った内容をもとに記事案を生成するよう設定します
- 次に、オペレーションでGoogleドキュメントの「新しいドキュメントを作成する」アクションを設定します
- さらに、Googleドキュメントの「文末にテキストを追加」アクションで、先ほどGeminiで生成した記事案をドキュメントに追記します
- 最後に、オペレーションでGoogle Driveの「ファイルの格納先フォルダを変更」を設定し、作成したドキュメントを指定のフォルダに保存します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガー機能では、記事案を生成するために必要なキーワードやテーマなどを自由な項目で設定できます
- Geminiでテキストを生成するアクションでは、どのような記事案を作成するかを指示するプロンプトを任意の内容にカスタマイズでき、フォームで取得した情報を変数として活用することが可能です
- Googleドキュメントでドキュメントを作成するアクションでは、ドキュメントのタイトルをフォームで取得した情報などをもとに任意に設定できます
- Googleドキュメントにテキストを追加するアクションでは、固定のテキストや、前段のフローで取得した情報を変数として設定できます
- Google Driveでファイルの格納先を変更するアクションでは、保存先のフォルダを固定値や変数を用いて任意に設定できます
■注意事項
- Gemini、Googleドキュメント、Google DriveのそれぞれとYoomを連携してください。
■概要
記事コンテンツの作成は、企画、構成案、執筆と多くの工程があり、手間がかかる業務ではないでしょうか。特にアイデア出しや下書き作成に時間がかかり、本来の業務を圧迫することもあります。このワークフローを活用すれば、フォームに情報を入力するだけでGeminiが記事案を自動で生成し、Google Driveに保存までの一連の流れを自動化できます。コンテンツ生成の自動化を実現し、コンテンツ作成業務の効率化を支援します。
■このテンプレートをおすすめする方
- 記事作成のアイデア出しや下書き作成業務の効率化を目指しているコンテンツ担当者の方
- コンテンツ生成の自動化に関心があり、具体的な実現方法を探している方
- GeminiやGoogle Driveを活用し、コンテンツ制作フローを改善したいと考えている方
■このテンプレートを使うメリット
- フォームにキーワードなどを入力するだけで記事案の生成から保存までが完了するため、コンテンツ作成にかかる時間を短縮できます
- 生成AIへの指示(プロンプト)が標準化されるため、担当者による品質のばらつきを防ぎ、属人化の解消に繋がります
■フローボットの流れ
- はじめに、Gemini、Googleドキュメント、Google DriveをYoomと連携します
- 次に、トリガーでフォームトリガー機能を選択し、記事作成に必要な情報を入力するためのフォームを設定します
- 続いて、オペレーションでGeminiを選択し、フォームで受け取った内容をもとに記事案を生成するよう設定します
- 次に、オペレーションでGoogleドキュメントの「新しいドキュメントを作成する」アクションを設定します
- さらに、Googleドキュメントの「文末にテキストを追加」アクションで、先ほどGeminiで生成した記事案をドキュメントに追記します
- 最後に、オペレーションでGoogle Driveの「ファイルの格納先フォルダを変更」を設定し、作成したドキュメントを指定のフォルダに保存します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガー機能では、記事案を生成するために必要なキーワードやテーマなどを自由な項目で設定できます
- Geminiでテキストを生成するアクションでは、どのような記事案を作成するかを指示するプロンプトを任意の内容にカスタマイズでき、フォームで取得した情報を変数として活用することが可能です
- Googleドキュメントでドキュメントを作成するアクションでは、ドキュメントのタイトルをフォームで取得した情報などをもとに任意に設定できます
- Googleドキュメントにテキストを追加するアクションでは、固定のテキストや、前段のフローで取得した情報を変数として設定できます
- Google Driveでファイルの格納先を変更するアクションでは、保存先のフォルダを固定値や変数を用いて任意に設定できます
■注意事項
- Gemini、Googleドキュメント、Google DriveのそれぞれとYoomを連携してください。
🤔著作権侵害を回避して画像を安全に生成できるか試してみた
著作権侵害やライセンス違反のリスクを避け、商用利用可能な画像を安全に生成するフローを実際に検証してみました。
検証内容
今回は、以下のような検証をしてみました!
検証:著作権侵害を回避した画像生成
【検証項目】
以下の項目で、検証していきます!

検証目的
本検証の目的は、AI生成画像における「意図しない既存作品への類似」や「学習元由来のウォーターマーク混入」といった法的・倫理的リスクを実務レベルでどこまで最小化できるかを明らかにし、ビジネス現場で安全にAIを活用するための標準的なワークフローと選定基準を確立することにあります。
使用モデル
画像生成:Stable Diffusion XLモデル(SDXL)(オンライン版 無料)
類似画像検索:Google レンズ
🔍検証:著作権侵害を回避した画像生成
ここからは、実際に検証した内容とその手順を解説します。
まずは実際の検証手順のあとに、それぞれの検証項目について紹介していきます!
〈検証方法〉
本検証では、Stable Diffusionを使用し、著作権侵害のリスクを抑えた画像の自動生成を行います。その後、生成された画像に類似した画像がないか検索します。
プロンプト:
cyberpunk city street, neon lights, highly detailed, futuristic atmosphere, 8k resolution, no watermark.
(特定のキャラクターやアーティスト名を入れず、一般的な風景を指定)
〈想定シーン〉
企業の広報担当者がブログのアイキャッチ画像を作成する場面
検証手順
ログイン後、「テキストから画像生成」をクリックします。
その後、こちらの画面が表示されるので、プロンプトを入力したら「生成」をクリックします。
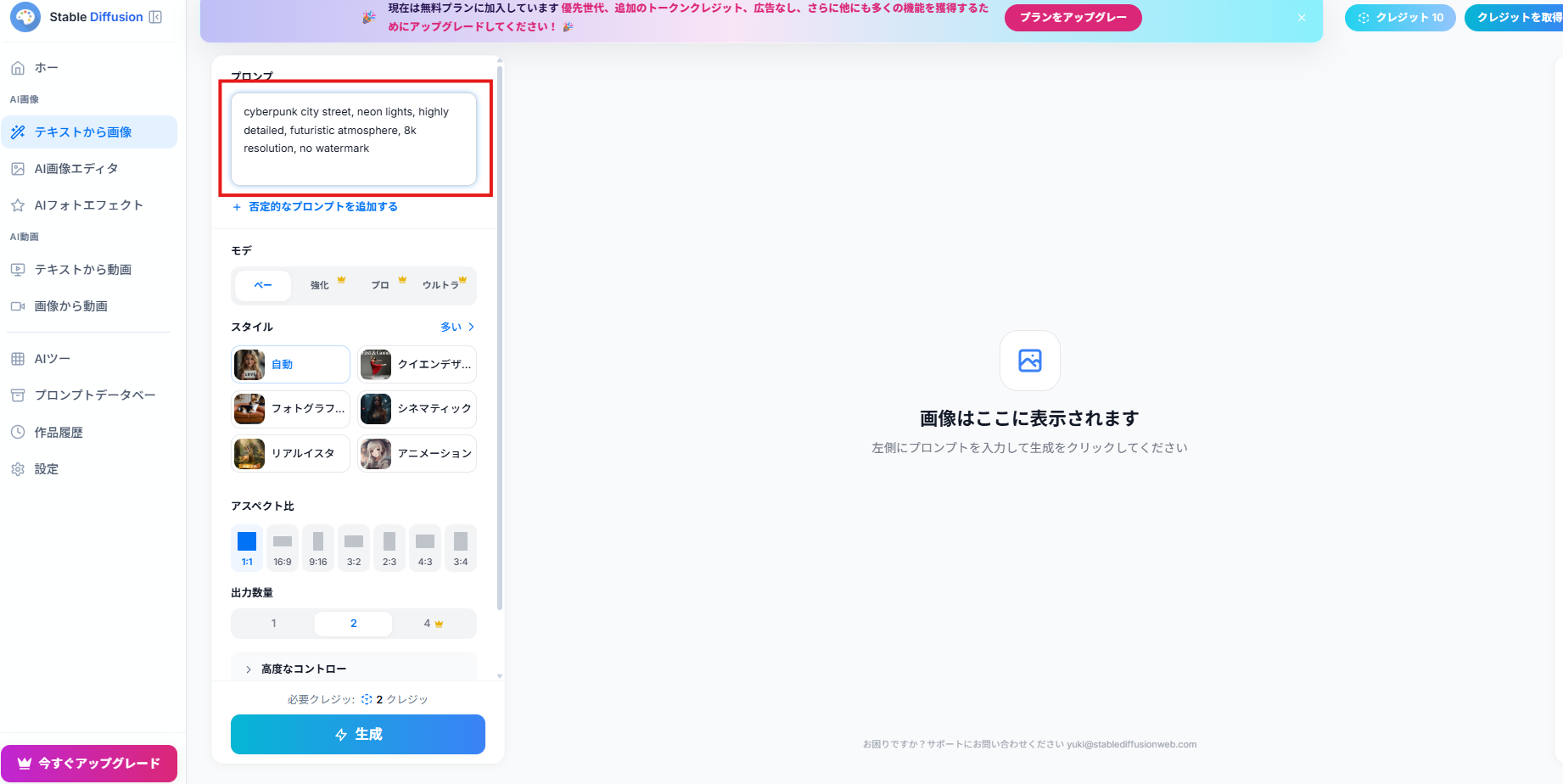
1分以内で生成が完了しました!
結果は以下のものとなりました。

類似した画像の検索結果
リアルな使用感
検証の結果、著作権における安全性がかなり高い画像生成が可能であることが実証されました。
生成されたサイバーパンク風の未来都市は、特定の既存作品を想起させない独創的なディテールを保っています。Google レンズによる類似性チェックでも「完全に一致する画像」は検出されず、これはAIが訓練データの断片をそのまま複製(依拠)したのではなく、プロンプトの概念を正しく再構成した結果と言えます。
本検証を通じて、適切なモデル選定と抽象的な指示文を用いることで、法的リスクを最小化しつつ高品質なビジュアルを確保できる運用の妥当性が確認できました。
🖊️検証結果
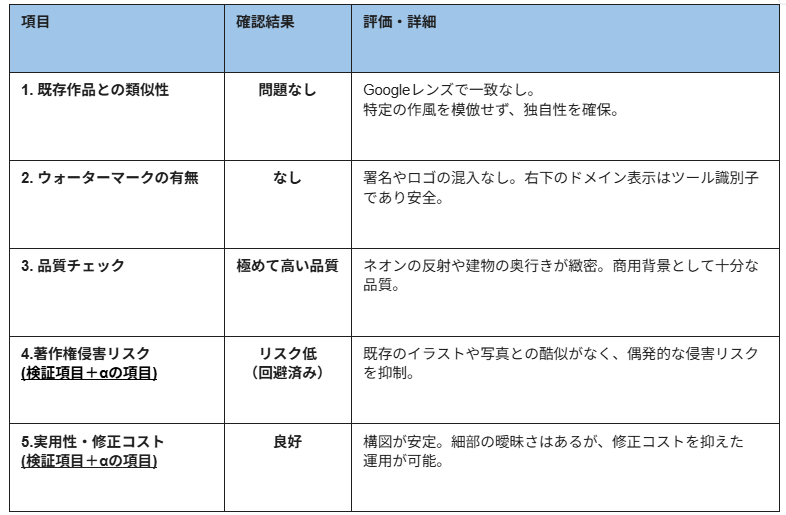
実際にStable Diffusionを使って、安全性検証を行った結果を以下に画像とともにまとめています。
1.既存作品との類似性
Googleレンズを用いた画像検索の結果、「完全に一致した画像は見つかりませんでした」との判定が得られました。この結果から、特定のアーティストの作風や既存の著作物を直接的に模倣した箇所は確認されず、以下の点が評価できます。
- 独自性の確保:
一般的なキーワードのみで構成されたプロンプトにより、特定の権利を侵害しない独自の風景が生成されています。 - 偶発的類似の回避:
既存のイラストや写真との酷似が見られないため、意図しない著作権侵害のリスクを効果的に抑制できています。
2.ウォーターマークの有無
生成された画像内には、著作権侵害の疑いがある「学習元の名残り(透かし)」は一切確認されませんでした。
- 署名やロゴの不在:
特定のストックフォトサイトのロゴや絵師の署名といった、権利関係に抵触する混入物はありません。 - ドメイン表示の性質:
画面右下に見える「stablediffusionweb.com」という文字は、利用した生成ツールの識別子であり、第三者の権利を侵害するものではないと判断できます。
3.品質チェック
サイバーパンク特有の「ネオンの光が濡れた路面に反射する様子」や「緻密な建物の奥行き」が非常に高い解像度で描写されています。
- 視覚的完成度:
8k resolutionを指定した通り、テクスチャやライティングが自然で、商用デザインの背景素材として十分なクオリティを保持しています。 - 不自然な破綻のなさ:
看板の文字など細部にAI特有の曖昧さは見られますが、全体として構図が安定しており、実務上の修正コストを抑えた運用が期待できる仕上がりです。
〈余談〉著作権侵害を避けるための3つのポイント
1. モデルのライセンスを必ず確認する:
特にSD3 / SD3.5ベースのモデルや、LoRAを使用する際は注意が必要です。Civitaiなどのプラットフォームでは、モデルごとのライセンス条項が明記されているので、必ず目を通しましょう。
2. i2i(画像から画像生成)では元画像の著作権に注意する:
既存のキャラクター画像や、他人が撮影した写真を読み込んで生成する場合、元画像の著作権を侵害する可能性が高くなります。商用利用時はt2i(テキストから画像生成)を基本としましょう。
3. 生成画像、プロンプト、使用モデルを記録・保存する:
いつ、どのモデルで、どんな指示で生成したかを記録しておくことは、自身の身を守るために重要です。AI基本法などの新しい潮流においても、生成プロセスの透明性確保(ログ保存)は企業にとって必須のアクションとなりつつあります。
✅まとめ
Stable Diffusionは強力なツールですが、著作権の知識なしに利用するのは危険です。
「AIで作ったから著作権フリー」と安易に考えず、以下の点を守って安全に活用しましょう。
- 使用するモデルのライセンスを必ず確認する。
- i2iの元画像には、自作の絵や著作権フリー写真を使う。
- 「〇〇風」といった特定の作家名をプロンプトに入れない。
- 生成した画像はGoogleレンズなどで類似性チェックを行う。
法的なルールは日々変化しています。常に最新の情報をキャッチアップしながら、クリエイティブな活動を楽しみましょう。
💡Yoomでできること
AI画像の生成業務において、著作権管理のための「記録」は不可欠ですが、手動で行うのは面倒です。Yoomを活用すれば、生成した画像やプロンプト情報を自動的にデータベースへ保存し、管理コストを削減できます。
例えば、以下のようなフローを自動化できます。
Google Driveへの自動保存: 生成画像を特定のフォルダに自動アップロードし、バックアップ。
Notionでのデータベース化: 画像とともに、使用したプロンプト、モデル名、生成日時をNotionのデータベースに自動登録。
是非、以下のテンプレートを活用して、安全で効率的な画像生成ワークフローを構築してください。
■概要Notionでコンテンツを管理する際、内容に合わせた画像を都度探したり作成したりする作業に手間を感じていませんか。このワークフローは、Notionにテキスト情報を追加するだけで、OpenAIによる画像作成からURLの自動反映までを実現します。手作業による画像作成のプロセスを自動化し、コンテンツ制作の効率を向上させたい場合に役立ちます。■このテンプレートをおすすめする方- Notionでコンテンツ管理をしており、画像作成や選定に時間を要している方
- OpenAIを活用した画像作成プロセスを自動化し、業務に組み込みたいと考えている方
- 手作業による画像の検索や作成依頼をなくし、企画などのコア業務に集中したい方
■このテンプレートを使うメリット- Notionへの情報追加を起点にOpenAIでの画像作成が自動で実行されるため、これまで手作業で行っていた画像関連業務の時間を短縮できます。
- 生成された画像URLは自動でNotionに反映されるため、手作業によるURLの転記ミスや更新漏れといったヒューマンエラーの防止に繋がります。
■フローボットの流れ- はじめに、NotionとOpenAIをYoomと連携します。
- 次に、トリガーでNotionを選択し、「ページが作成されたら(Webhook)」を設定します。
- 続いて、Notionの「レコードを取得する(ID検索)」アクションを設定し、トリガーとなったアイテムの詳細情報を取得します。
- 次に、OpenAIの「テキストから画像を生成する」アクションで、Notionから取得したテキスト情報をもとに画像を生成します。
- 最後に、Notionの「レコードを更新する(ID検索)」アクションで、生成された画像のURLを該当のレコードに反映させます。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Notionでは、自動化の対象としたいデータベースに連携してください。
- OpenAIの画像生成オペレーションでは、Notionの特定のプロパティ情報などを組み合わせて、画像生成の指示(プロンプト)を任意で設定できます。
■注意事項- Notion、OpenAIのそれぞれとYoomを連携してください。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- Notionでコンテンツ管理をしており、画像作成や選定に時間を要している方
- OpenAIを活用した画像作成プロセスを自動化し、業務に組み込みたいと考えている方
- 手作業による画像の検索や作成依頼をなくし、企画などのコア業務に集中したい方
- Notionへの情報追加を起点にOpenAIでの画像作成が自動で実行されるため、これまで手作業で行っていた画像関連業務の時間を短縮できます。
- 生成された画像URLは自動でNotionに反映されるため、手作業によるURLの転記ミスや更新漏れといったヒューマンエラーの防止に繋がります。
- はじめに、NotionとOpenAIをYoomと連携します。
- 次に、トリガーでNotionを選択し、「ページが作成されたら(Webhook)」を設定します。
- 続いて、Notionの「レコードを取得する(ID検索)」アクションを設定し、トリガーとなったアイテムの詳細情報を取得します。
- 次に、OpenAIの「テキストから画像を生成する」アクションで、Notionから取得したテキスト情報をもとに画像を生成します。
- 最後に、Notionの「レコードを更新する(ID検索)」アクションで、生成された画像のURLを該当のレコードに反映させます。
■このワークフローのカスタムポイント
- Notionでは、自動化の対象としたいデータベースに連携してください。
- OpenAIの画像生成オペレーションでは、Notionの特定のプロパティ情報などを組み合わせて、画像生成の指示(プロンプト)を任意で設定できます。
- Notion、OpenAIのそれぞれとYoomを連携してください。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
プログラミング知識なしで手軽に構築できます。



