








・
【Perplexityで論文要約してみた】調査・論文作成の効率を劇的に上げる活用法とは
資料の山に埋もれて、数字の根拠がどこにあるのかわからず焦った経験、ありませんか?
「その情報のソースは?」と聞かれてすぐに答えられないと、冷や汗が出ますよね。
ネットで検索しても関係ないページばかりヒットしたり、AIに聞いても本当かどうかわからなくて不安になったり……調べ物って、意外とストレスが溜まる仕事です。
そんな時に頼りになるのが、Perplexity AIというツールです。
AIをうまく活用することで、今まで数時間かかっていた裏取りや資料読みが、ぐっと楽になります。
Perplexityで論文要約をサクッと済ませてしまえば、難しい資料と格闘する時間を減らして、もっと大事な「考える時間」を増やせます。
本記事では、Perplexity AIの基本的な使い方から、実務で役立つちょっとしたコツまで紹介していきます。
新しいツールを味方につけて、情報の波をうまく乗りこなしていきましょう!
✍️そもそもPerplexityとは
本記事の想定読者
この記事は、特に以下のような課題をお持ちの方に役立ちます。
- 情報収集の非効率さに悩むビジネスパーソン・学生層:市場調査やレポート作成、学術論文の検索に多くの時間を費しており、より迅速かつ的確な情報収集手段を求めている方々
- 情報の正確性と出典を重視する研究者・専門職層:研究、記事執筆、企画立案など、根拠に基づいた正確な情報が不可欠な業務に従事し、情報の信頼性を担保できるツールを探している方々
- 業務へのAI統合を検討する開発者・技術職層:最新技術の動向調査やコードのデバッグ、仕様書の読解など、専門的な情報収集を効率化し、AIを実務ワークフローに組み込みたいと考えている方
Perplexityとは
Perplexity AIの基本的な概念と、従来のツールとの決定的な違いを、AIを初めて使う方にも分かりやすく解説していきます。
【Perplexityとは何か?】
Perplexity AIは、Web検索と生成AIを組み合わせて質問に答える「AI回答エンジン」です。文章で質問すると、関連する情報源をWebから探し出し、ポイントを整理した形で答えを返してくれます。
回答画面には、参照した記事やサイトへのリンクが並ぶため、自分で元情報を開いて詳しく読み込むこともできます。
複雑なテーマについて複数の情報源を横断的に調査し、レポート形式でまとめるリサーチ機能も提供されており、本格的なリサーチにも使いやすい設計になっています。
質問に対して最適な資料を探し出し、要点をまとめて報告してくれる、優秀な専門リサーチャーのような存在です。
出典:公式サイト
【従来手法との違い】
- 事前に学習した過去のデータだけを頼りに回答するため、最新の論文について聞いても「情報がありません」と返されたり、もっともらしい嘘(ハルシネーション)を事実は混在させて回答したりするリスクがありました。
そのため、出力された要約が本当に正しいのか、結局自分で原文を読み直して裏取りをする手間が発生していました。 - 「RAG(検索拡張生成)」という仕組みにより、常にリアルタイムでWeb情報を参照しながら回答を作成します。
論文PDFを読み込ませた際も、単にファイルを要約するだけではありません。ファイル内の情報と、Web上の最新情報を照らし合わせる「動的なグラウンディング」を行い、情報の正確性を担保します。
すべての情報に参照元(出典)が明記されるため、信頼性の確認が一瞬で完了します。
【利用上の重要事項】
Perplexityを業務で安心して使うために、知っておくと役に立つポイントをまとめました!
AIを使うシーンが増えてきた今だからこそ、基本仕様や注意点を軽く押さえておくと、ぐっと扱いやすくなります。
-
ファイルアップロード機能の制限について:一度にアップロードできるファイルは10件までで、1ファイルあたり40MBが上限です。音声・動画ファイルにも対応しており、会議の録音データを読み込ませると、話者ごとに誰が何を話したかを含めて文字起こしし、検索対象にできます。
なお、最新の制限値や対応形式はプランやアップデートにより変わる可能性があるため、都度アプリ内の表示を確認すると安心です。 -
リサーチ機能の利用条件について:2025年2月に追加されたリサーチ機能は、無料版でも利用できますが、1日に実行できる回数に上限があります。
Proプランであればかなり余裕をもって利用できるため、通常の業務で回数を気にする場面はあまりありません。
※利用可能な回数やクレジットの数は時期や契約プランの変更で変動することがあるため、事前にプラン内容を確認しておくと安心です。 -
データプライバシーについて:アップロードしたファイルややり取りの内容が、回答を作るために一時的に解析されます。。
個人向けのFree/Proプランでは、「AI Data Retention」が初期設定でオンになっていて、このまま使うと検索履歴や一部のコンテンツが学習に回されています。
研究資料や社外秘の情報を扱うときは、Settingsの「AI Data Retention」をオフに切り替えておきましょう。
なお、AI Data Retentionをオフにしても、サービスの運用や安全性確保のためにログが保存されるケースがあります。
どの範囲までPerplexityに預けるのか、一度考えておくと判断しやすくなります。 -
日本語対応の精度について:日本語での検索や要約も可能ですが、専門性の高い論文では英語で処理したほうが文脈の解釈精度が高くなる傾向があります。
必要に応じて「英語で内容を理解し、日本語で要約を出力する」といった使い分けも有効です。
⭐Yoomはリサーチ業務や論文の要約を自動化できます
👉Yoomとは?ノーコードで業務自動化につながる!Perplexityを活用することで、膨大な論文やWeb情報からの要点抽出や最新情報のキャッチアップは効率化されます。
しかし、AIが導き出した有益な情報を手動でドキュメントにまとめたり、チームのチャットツールに共有したりといった「情報の整理と伝達」に、まだ多くの時間を費やしてはいませんか?
ハイパーオートメーションツール「Yoom」を活用すれば、AIによるリサーチの実行から、その結果を元にした記事作成、さらには外部ツールへの投稿や通知までを自動化できます。
プログラミングの知識がなくても、簡単な操作だけでPerplexityを使った業務を自動化できるので、ぜひ試してみてください。
- Perplexityを活用したニュースの自動収集で、情報収集を効率化したい方
- 業界や競合の動向を毎日チェックし、チームへ共有している事業開発やマーケティング担当者の方
- 手作業でのニュースクリッピングやレポーティング業務に課題を感じている方
- Perplexityでの検索から要約、通知までが自動で実行されるため、情報収集と共有にかかる時間を短縮できます
- 毎日の定型業務を自動化することで、情報の共有漏れや遅延といった人的ミスを防ぎ、安定した情報共有が可能です
- はじめに、PerplexityとSlackをYoomと連携します
- 次に、トリガーでスケジュールトリガーを選択し、毎日特定の時刻にフローが起動するよう設定します
- 続いて、オペレーションでPerplexityの「情報を検索」アクションを設定し、収集したい情報のキーワードを指定します
- 次に、オペレーションでPerplexityの「テキストを生成」アクションを設定し、前段で取得した情報を任意のプロンプトを使用して要約します
- 最後に、Slackの「チャンネルにメッセージを送る」アクションで、要約した内容を指定のチャンネルに通知します
■このワークフローのカスタムポイント
- スケジュールトリガー機能では、フローを起動させたい曜日や時間を任意に設定できます
- Perplexityで検索するキーワードは、固定のテキストだけでなく、前段のオペレーションで取得した情報を変数として設定することも可能です
- Perplexityで生成するテキストは、前段で取得したインプットやプロンプトを使用して任意の文章を生成できます
- Slackへの通知先チャンネルは任意で設定でき、メッセージ本文にはAIが要約したテキストなどを変数として自由に組み込めます
- Perplexity、SlackのそれぞれとYoomを連携してください。
- Google スプレッドシートでコンテンツを管理しており、盗作検出のプロセスを効率化したいメディア担当者の方
- レポートや論文の類似性をチェックし、オリジナリティを担保する作業を自動化したいと考えている方
- Perplexityを活用して、テキストの関連情報リサーチや類似性チェックを自動化したい方
- Google スプレッドシートへの入力だけでPerplexityが自動で検索を行うため、これまで手作業で行っていたリサーチやチェックの時間を短縮できます
- 手作業による検索漏れや確認ミスといったヒューマンエラーを防ぎ、コンテンツチェックの精度向上に繋がります
- はじめに、Google スプレッドシートとPerplexityをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 次に、オペレーションでPerplexityの「情報を検索(AIが情報を要約)」アクションを設定し、追加された行のテキストを検索対象にします
- 最後に、オペレーションでGoogle スプレッドシートの「レコードを更新する」アクションを設定し、Perplexityの検索結果を特定のセルに反映させます
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー及びオペレーション設定では、対象のスプレッドシートIDやタブ名を任意で設定してください
- Perplexityで情報を検索するアクションでは、使用するAIモデルや、盗作検出の補助に適した指示を出すためのプロンプトを任意で設定することが可能です
- Google スプレッドシート、PerplexityのそれぞれとYoomを連携してください
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます
- プランによって最短の起動間隔が異なりますので、ご注意ください
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください
🤔実際に使ってみた
想定されるユースケース2点をPerplexityを実際に使ってみました。
設定方法も載せているので、ぜひ参考にしてみてくださいね。
検証条件
Perplexityの無料プラン
モデル:ベスト
使用する論文:以下のように約20000字の架空の卒業論文を使っています。卒論でよく見る長さに合わせているので、しっかり読み応えのあるテキストです。
これを読み込ませ、Perplexityがどれくらい整理して答えてくれるのかを見ていきます。

検証内容とポイント一覧
利用シナリオ案1:結論ファーストでの「3行要約」
- 想定されるユースケース:社内で統一されたトーンや必須フレーズを含む初回営業提案メールを、顧客情報に合わせて即座に生成する
-
検証項目:
論文の長いイントロダクションを飛ばして、核心となる「結論」だけを捉えているか
専門用語を噛み砕き、直感的にわかる日本語になっているか
わかりやすさを優先するあまり、論文の重要なニュアンス(「AだがBである」といった複雑な結果)を勝手に単純化したり、事実を歪めていないか
利用シナリオ案2:論文内のデータと「現在のWeb情報」の照合
- 想定されるユースケース: 論文内にある「2025年にはリモートワーク市場が〇〇%拡大するとの予測」という記述に対し、2025年12月時点の実際のWebニュースや統計データを検索させ、その予測が当たっていたかどうかを答え合わせさせる。
-
検証項目:
PDF内に書かれた「過去の予測値」と、検索で見つけた「現在の実績値」を混同することなく、明確に区別して比較できているか。
比較対象として持ってきたWeb上のデータは信頼できるものか、またそのソース(URL)が明示されているか。
単に「当たった/外れた」の数字合わせだけでなく、もし予測が外れていた場合、最新ニュースに基づいてなぜ外れたのかという要因まで推測・補足できるか。
検証方法
では、さっそく検証していきましょう!
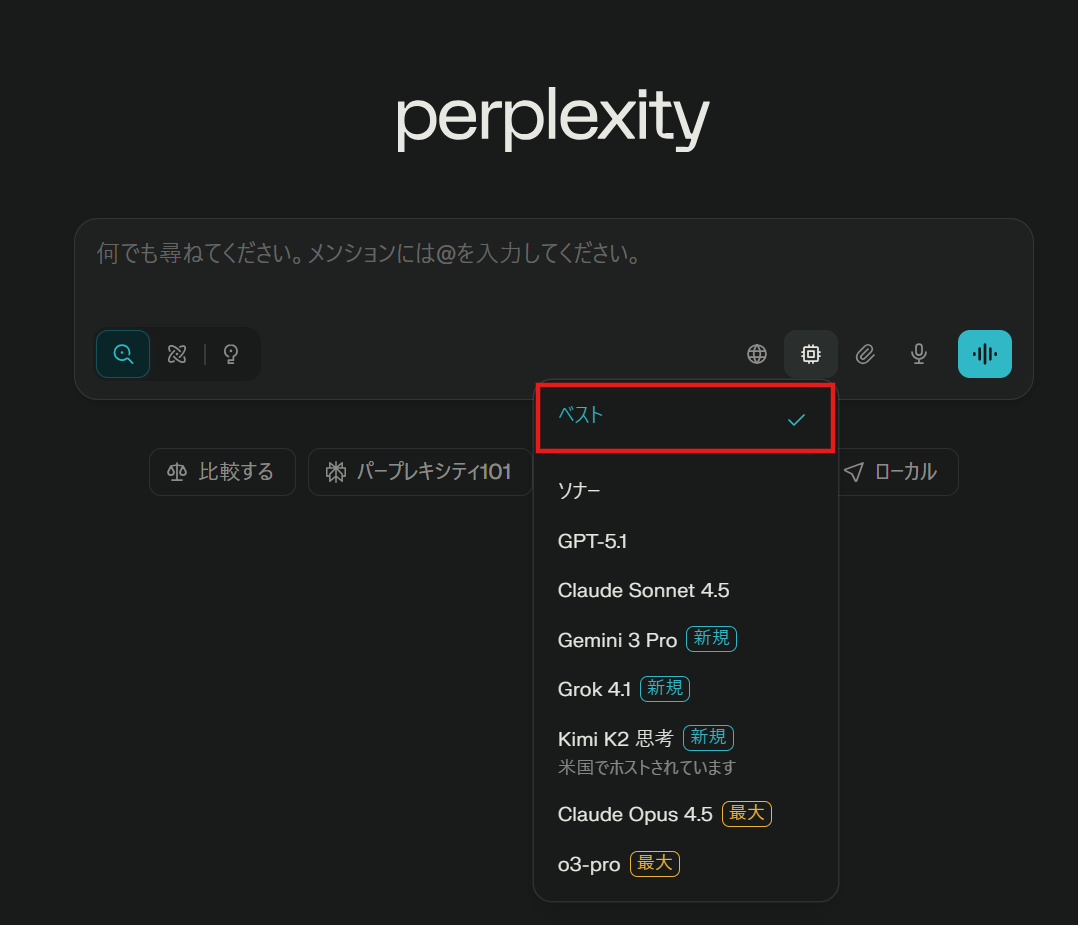
1.Perplexityにログインし、画像の歯車マークからモデルを選びましょう。
デフォルトでは「ベスト」になっているので、そのままベストにしておきます。
2.クリップのアイコンからファイルを添付できます。
ここに論文のファイルを添付します。

利用シナリオ案1:結論ファーストでの「3行要約」
Perplexityへの設定
では、さっそく論文を読み込んでもらいましょう!
今回は、読み手を「多忙な経営層」に設定し、学術的な正確さよりも、ビジネスの現場ですぐに使える「分かりやすさ」を最優先するよう指示を組みました。
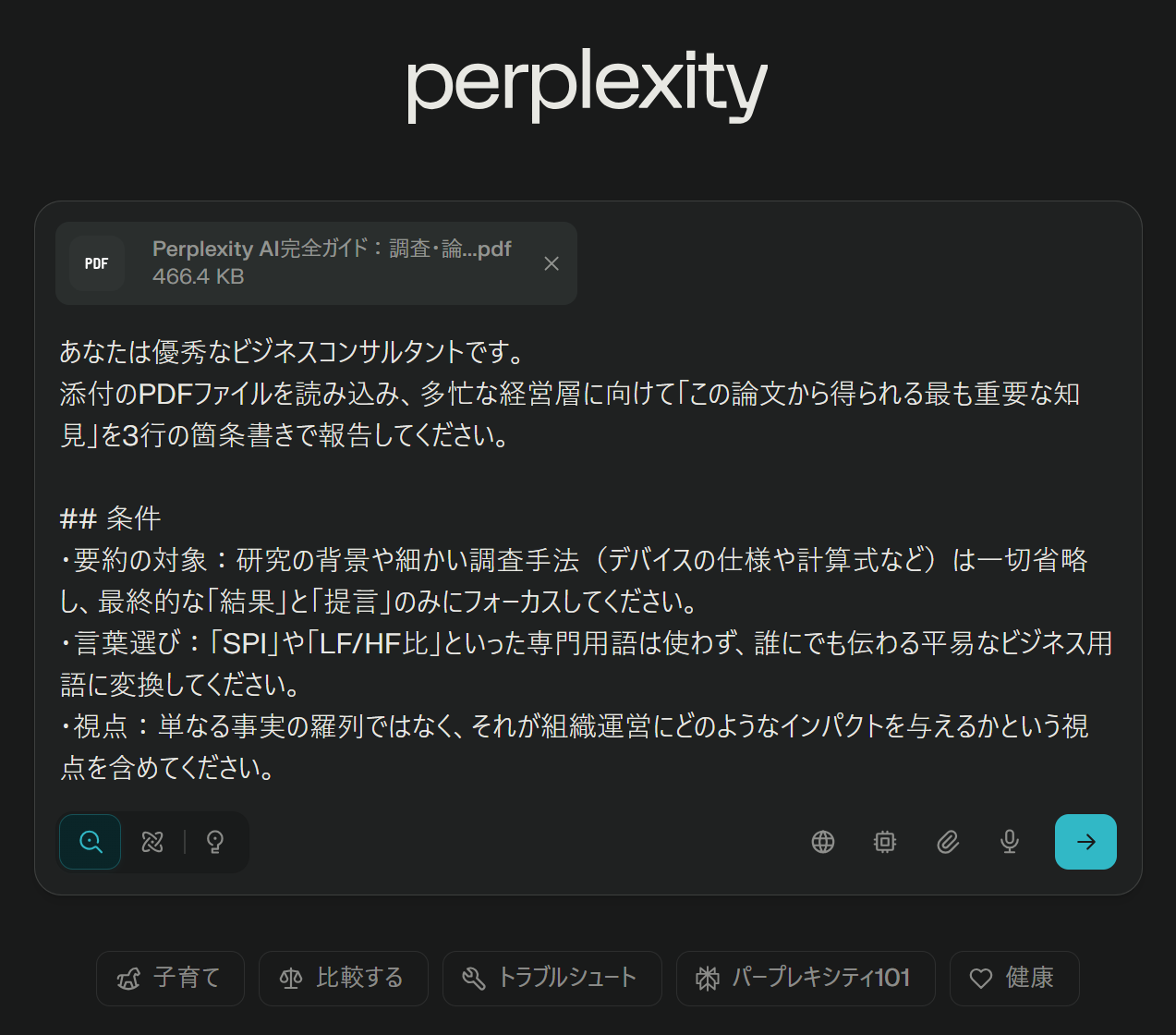
実際に使ったプロンプトはこちら
あなたは優秀なビジネスコンサルタントです。
添付のPDFファイルを読み込み、多忙な経営層に向けて「この論文から得られる最も重要な知見」を3行の箇条書きで報告してください。
## 条件
・要約の対象:研究の背景や細かい調査手法(デバイスの仕様や計算式など)は一切省略し、最終的な「結果」と「提言」のみにフォーカスしてください。
・言葉選び:「SPI」や「LF/HF比」といった専門用語は使わず、誰にでも伝わる平易なビジネス用語に変換してください。
・視点:単なる事実の羅列ではなく、それが組織運営にどのようなインパクトを与えるかという視点を含めてください。
このように、ターゲット(経営層)と制約(手法は省略・専門用語なし)を明確にすることで、AIが余計な情報を拾わないように制限をかけるイメージです。
検証結果
検証結果を以下の3つの観点で評価します。
① 指定した出力テンプレートに従っているか
以下の3つの観点で評価します。
① 論文の長いイントロダクションを飛ばして、核心となる「結論」だけを捉えているか
判定:⭕️
余計な前置きをカットすることに成功 「研究の背景や手法は省く」という指示はしっかりと守られました。
AIによる要約でありがちな「本研究では〜を対象に調査を行い」といった導入部分がなく、1行目から「業務の生産性は〜」と結論に入れている点は評価できます。
② 専門用語を噛み砕き、直感的にわかる日本語になっているか
判定:⭕️
論文内に登場する「デジタル・モノカルチャーの脆弱性」や「グレート・ブラックアウト」といった独自の文脈を持つ言葉を、そのまま使わずに「アナログのバックアップを含む危機時の業務継続計画」と言い換えたのは見事です。
専門外の人が読んでも意味が通じるレベルに噛み砕かれているなと感じました。
③ わかりやすさを優先するあまり、事実を歪めていないか
判定:❌
解釈ミス(ハルシネーション)が発生していました。Perplexityの回答では「優秀人材の流出も少ない」と断言されていますが、元の論文では「離職意思はむしろ高い(条件の良いオファーがあれば即転職する)」という、真逆の結果が「孤独のパラドックス」として警告されています。
AIが「生産性が高い=うまくいっている=離職も少ないはずだ」という単純なロジックで勝手に補完してしまい、論文で最も重要な「生産性は上がったが、組織への愛着は下がった」という複雑な警鐘を無視してしまいました。要約を鵜呑みにして経営判断をするのは非常に危険です。
ポイント
今回の検証を通して、Perplexityで要約を依頼する際に意識しておきたいポイントが2つ見つかりました。
- 「わかりやすさ」を求めすぎると、嘘をつく
「忙しい人向けに簡単に」と指示しすぎると、AIは事実よりもわかりやすいストーリーを優先してしまいます。
今回の論文には「生産性は上がったが、離職リスクも上がった」という矛盾が含まれていましたが 、AIはこれを「生産性が高い=離職も少ないはず」という一般的なロジックで勝手に書き換えてしまいました。
複雑な結果が含まれる論文の場合、過度な要約指示は事実をねじ曲げる原因になります。
-
「読まなくていい場所」をはっきり伝える
今回、形式面が完璧だった理由は、プロンプトで「研究の背景や細かい手法は省く」と禁止事項を明示したからです。
単に「要約して」と頼むと、AIは1ページ目から律儀に読んでしまいますが、「手法は無視して結論だけ見て」と指示することで、必要な情報だけに集中させることができます。
利用シナリオ案2:論文内のデータと「現在のWeb情報」の照合
Perplexityの設定
論文やレポートを読むとき、一番気になるのが「この予測、本当に当たったの?」という点ですよね。
特に今回のような数年前の資料だと、「未来予測」が現在の事実と合っているかで、その資料の信頼性が大きく変わります。
そこで、論文内に書かれた「2025年の市場予測」を、2025年12月の情報と照らし合わせて、自動でファクトチェックをさせてみましょう。
実際に使ったプロンプトはこちら
今回は、論文(PDF)とWeb(検索結果)を明確に区別させるため、手順を分けて指示を出します。また、単なる数字合わせで終わらないよう、「なぜ外れたのか」の考察まで求めます。
あなたは市場リサーチの専門家です。 以下の手順で、添付論文の予測精度を検証してください。
- PDFの確認: 添付ファイル第1章にある、経済産業省による「2025年の国内リモートワーク関連市場規模(金額と拡大率)」の予測数値を抽出してください。
- Web検索(ファクトチェック): ブラウジング機能を使い、2025年12月時点での「実際の国内リモートワーク市場規模」に関する最新の統計データや調査レポートを探してください。 可能な限り、信頼できる調査機関や官公庁のデータを引用してください。
- 比較と考察: 「論文内の予測値」と「検索で見つけた実績値」を表で比較し、両者に乖離がある場合は、2024年から2025年に起きた社会情勢や経済ニュースに基づいて「なぜ予測が外れたのか(あるいは当たったのか)」の要因を分析してください。
このように「PDFから抽出」→「Webで検索」→「比較して考察」というステップを明示しています。
また、今回読み込ませる論文はあくまで「架空」のものです。
Perplexityが、「検索した現実の数値と全然違うぞ?」と矛盾に気づけるかどうかも、見どころの一つです。
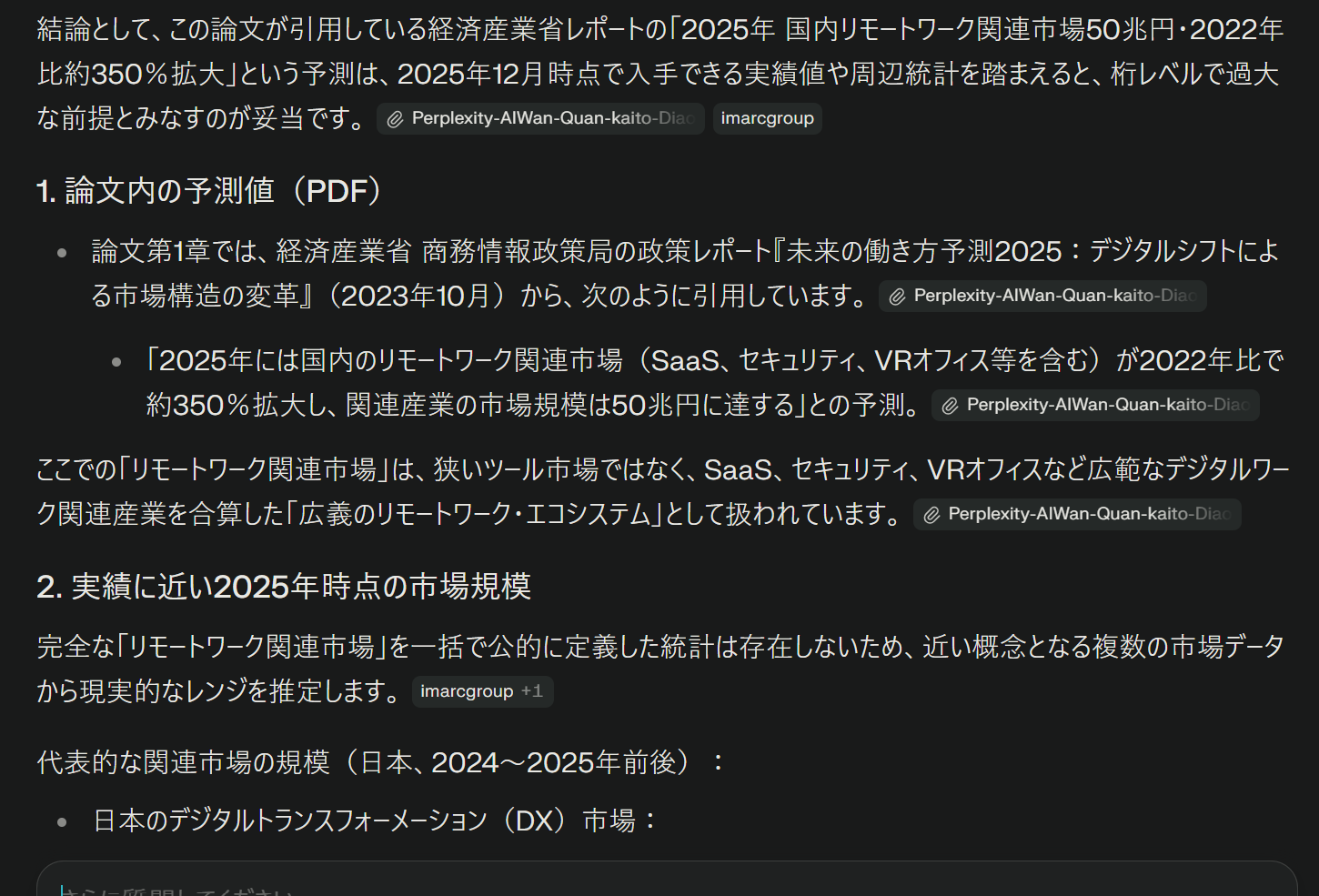
すると、以下のように出力してくれました。
✅検証結果
①PDFの「過去の予測」と、Webの「現在の事実」を区別できているか
判定:⭕️
ここに関しては合格点です。「1. 論文内の予測値(PDF)」と「2. 実績に近い2025年時点の市場規模」という見出しで、情報の出所を明確に分けています。
生成AIによくある「PDFの内容をネットの事実と勘違いして語る」というミスは回避できており、比較の土台は作れています。
②比較対象のデータは信頼できるか
判定:🔺
ここは注意が必要です。日本ネットワークセキュリティ協会(JNSA)のような信頼できる団体のレポートを引いている一方で、比較データの根拠として「LinkedInの個人投稿(Pulse)」や、「Imarc Group」「Mordor Intelligence」といった有償レポート販売サイトのSEO記事を多用しています。
「官公庁のデータを引用して」と指示したにもかかわらず、検索上位に出てくるアクセス稼ぎのページを「統計データ」として拾ってしまっており、リサーチャーとしての質は低いです。
③予測が外れた「要因」まで分析できているか
判定:❌
Perplexityは「数字が大きすぎる」ことには気づきましたが、「そもそもPDFが引用している『経産省の2023年レポート』自体が実在しない(架空の文献である)」ことには気づけませんでした。
架空の出典を「実在する過去の予測」だと信じ込んだ上で、「なぜ外れたのか(オフィス回帰が進んだから等)」というもっともらしい理由を後付けで創作しています。
数字のファクトチェックはできても、「文献の存在確認」という根本的な裏取りが抜けており、精巧なフェイク論文には騙されてしまうリスクが浮き彫りになりました。
ポイント
今回の検証で、Perplexityは「数字の比較」は得意でも、「情報の質の判断」にはまだ課題があることが明確になりました。特に注意すべきは以下の2点です。
-
「検索上位のサイト」=「信頼できる情報」とは限らない
プロンプトで「官公庁のデータを」と指定したにもかかわらず、実際には有償レポートの販売サイト(SEO記事)や個人のSNS投稿をソースとして拾ってしまいました。Perplexityは「Google検索で上位に来るページ」を優先的に参照する傾向があるため、提示されたURLが本当に信頼できる一次情報なのか、リンクを開いて確認する工程は必須といえます。 -
「架空の文献」までは見抜けない
今回最大の失敗は、論文内に仕込んだ「架空の経産省レポート」を、AIが実在するものとして処理してしまった点です。「50兆円という数字の異常さ」は指摘できましたが、「そもそもそんなレポートは存在しないのでは?」という根本的な疑いを持つことはできませんでした。
前提が嘘であっても、それに基づいたもっともらしい解説を作ってしまうため、ファクトチェック用途で使う場合は「元の資料自体が本物か」を人間が判断する必要があります。
🖊️まとめ
これまでの検証を通して言えるのは、Perplexityは「人間の代わりに読んでくれる魔法のツール」ではなく、「人間の読解をサポートする超高速な助手」として優秀だということです。
「3行で要約して」と頼めば、確かにそれっぽい答えはすぐに返ってきます。
しかし、今回の検証で明らかになったように、わかりやすさを優先するあまり重要な矛盾を無視したり、架空の文献を事実として扱ってしまう危うさも持っています。
AIはあくまで計算で答えを出しているだけで、意味を理解しているわけではないということを痛感させられました。
Perplexityを使う最大のメリットは、「正解を教えてもらう」ことではなく、「あたりをつける時間を短縮する」ことにあります。
「この論文はおおまかにどういった内容なのか?」という最初のフィルタリングを任せる分には、十分に役立つと思います。
AIを適材適所で使いこなして、空いた時間をより創造的な業務に使っていきましょう!
💡Yoomでできること
AIツールを使いこなして得られた「深い洞察」を、いかに組織全体のスピードに繋げるかがビジネスの成果を左右します。Yoomは、AIが得意とする「分析」「要約」「整理」といった機能を、社内で利用している700種類以上のアプリと自由に組み合わせることができるプラットフォームです。
単なる「リサーチの効率化」にとどまらず、会議の議事録から自動でToDoリストを作成してタスク管理ツールへ登録したり、蓄積されたナレッジをAIに整理させて定期的にチームへ配信したりと、組織全体のスピード感を高めるワークフローをノーコードで実現します。
まずは豊富なテンプレートからあなたの業務に最適な自動化を体験してみてください。
👉今すぐYoomに登録する
■このテンプレートをおすすめする方
- Notionに蓄積された議事録やドキュメントの要点を素早く把握したいと考えている方
- Perplexityを活用して、手作業による情報要約の手間を削減したいと考えている方
- チーム内での情報共有を円滑にし、ドキュメントの閲覧効率を高めたいマネージャーの方
■このテンプレートを使うメリット
- Notionデータベースのページが作成・更新されるたびにPerplexityが自動で要約を生成するため、手作業での要約作成にかかる時間を短縮できます。
- AIによる自動要約で、人による要約の質のばらつきや作成漏れを防ぎ、ドキュメント管理の品質を均一に保つことができます。
■フローボットの流れ
- はじめに、NotionとPerplexityをYoomと連携します。
- 次に、トリガーでNotionを選択し、「特定のデータソースのページが作成・更新されたら」というアクションを設定します。
- 続けて、オペレーションでNotionの「レコードを取得する(ID検索)」アクションを設定し、トリガーとなったページの情報を取得します。
- 次に、オペレーションでPerplexityの「テキストを生成」アクションを設定し、前のステップで取得したページの内容を要約するように指示します。
- 最後に、オペレーションでNotionの「レコードを更新する」アクションを設定し、生成された要約を元のページに書き込みます。
■このワークフローのカスタムポイント
- Perplexityで情報を要約するアクションでは、プロンプトを編集することで、「箇条書きで要約して」や「300字以内でまとめて」など、生成する要約の形式や内容を自由に設定できます。
- Notionのレコードを更新するアクションでは、要約を書き込むプロパティを任意で指定したり、前段で取得したデータと固定のテキストを組み合わせて出力内容を調整したりすることが可能です。
■注意事項
- Notion、PerplexityのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
■このテンプレートをおすすめする方
- 日々多くのメールを処理しており、情報収集を効率化したいと考えている方
- Perplexityを活用し、長文メールの内容把握と共有を自動化したいチームリーダーの方
- Google Chatを情報共有のハブとしており、通知業務を効率化したい方
■このテンプレートを使うメリット
- メールの受信から内容の要約、チャットへの通知までを自動化できるため、情報収集や共有にかかる時間を短縮できます。
- 手作業による情報の転記や要約作業が不要になるため、伝達ミスや通知漏れといったヒューマンエラーの防止に繋がります。
■フローボットの流れ
- はじめに、PerplexityとGoogle ChatをYoomと連携します。
- 次に、トリガーでメールトリガー機能を選択し、このワークフローを起動するための専用メールアドレスを生成します。
- 次に、オペレーションでPerplexityの「テキストの生成」アクションを設定し、トリガーで受信したメール本文を要約するようにプロンプトを設定します。
- 最後に、オペレーションでGoogle Chatの「メッセージを送信」アクションを設定し、Perplexityが生成した要約文を指定のスペースに通知します。
■このワークフローのカスタムポイント
- メールトリガー機能では、生成するメールアドレスの一部を任意で指定できるほか、特定の件名や本文を含むメールのみを処理の対象とするよう条件を設定することが可能です。
- Perplexityのオペレーションでは、要約のスタイルなどを指示するプロンプトを自由に設定でき、受信したメールの件名などの情報を変数としてプロンプト内に埋め込めます。
- Google Chatへの通知では、メッセージを送信するスペースを任意に指定したり、要約結果の前後に定型文を追加したりするなど、通知内容を柔軟にカスタマイズできます。
■注意事項
- Perplexity、Google ChatのそれぞれとYoomを連携してください。
- Google Chatとの連携はGoogle Workspaceの場合のみ可能です。詳細は「Google Chatでスペースにメッセージを送る方法」を参照ください。
プログラミング知識なしで手軽に構築できます。







