








・
【PerplexityのRAG活用ガイド】Spacesを使った情報検索の実践レビュー

RAG(Retrieval-Augmented Generation:検索拡張生成)は、生成AIが持つ知識データベースだけでなく、外部の情報源を検索し、その結果をもとに回答を生成する技術です。Perplexityはこの技術を活用し、Web上の最新情報を検索しながら回答を生成する代表的なAI検索サービスです。
本記事では、PerplexityのRAGの基礎的な仕組みから、APIやSpaces機能を使った環境構築の方法、そして導入時の注意点まで詳しく解説します。技術的な理解を深め、業務プロセスへの組み込みや情報検索の高度化に役立てるための参考にしてください!
🔍PerplexityのRAG(検索拡張生成)の仕組み

Perplexityは、入力された質問に対して単に学習済みのデータから予測して答えるだけでなく、外部の情報を検索してから回答を生成するRAGの仕組みを採用しています。これにより、事実に基づいた情報を提供できる傾向があります。
ここでは、RAGの基本概念や、回答の精度をどのように担保しているのかについて詳しく解説します。
▼LLMの課題とRAGの基本概念
従来の大規模言語モデルは、学習した時点でのデータに基づいて回答を生成するため、未知の情報や専門的な独自データに対応しきれないという課題を持っています。この課題を解決する仕組みがRAGです。
RAGは、ユーザーの質問に対してまず外部のデータベースやウェブから関連する情報を「検索」し、取得した情報をもとに言語モデルが回答を「生成」します。これにより、AIは自身の事前学習データに依存せず、外部のソースを参照しながら回答を作成します。常に外部から情報を取得する特性上、未学習の領域に対しても適切な回答を導き出すアプローチとなります。
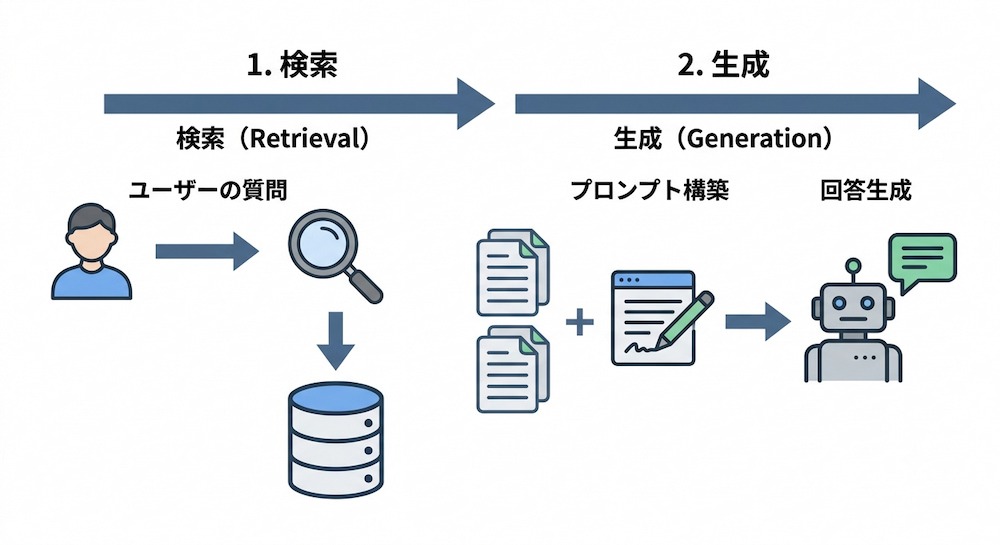
▼RAGによるハルシネーション防止と出典提示
生成AIが事実とは異なるもっともらしい嘘を出力してしまう現象を『ハルシネーション』と呼びます。Perplexityは、回答を生成するプロセスにおいて、検索によって得られたソース(情報源)や参照情報をもとに回答を組み立てる仕組みです。回答の文章中には引用元のリンクが番号付きで明示されるため、ユーザー自身が一次情報にアクセスして事実確認を行いやすい設計になっています。
単に推測で文章を生成するのではなく、実在するWebページや文献のテキストを根拠にして回答を組み立てるため、一般的な対話型AIと比較してハルシネーションの発生を抑え、事実に基づいた出力を提供できる傾向があります。
⭐YoomはPerplexityを用いたリサーチや情報処理を自動化できます
AIを単体で利用するだけでもリサーチや情報収集の効率は向上します。しかし、AIに入力するデータの準備や、出力された結果を別のアプリへ転記する作業には手動のプロセスが残ります。
Yoomを活用すれば、この「入力と出力の橋渡し」を完全に自動化できます。
[Yoomとは]
たとえば、定期的にAIワーカーがPerplexityで調査し、テクノロジースタックレポートを自動作成してGmailで送信するといったことも可能です。気になる方はぜひチェックしてみてくださいね👀
■概要最新の技術動向を把握するために、定期的な情報収集やレポート作成に手間を感じていませんか。手作業でのリサーチは時間がかかる上に、重要な情報を見逃してしまう可能性もあります。このワークフローを活用すれば、スケジュールに合わせてAIエージェント(AIワーカー)がPerplexityで調査を行い、最新の技術スタックレポートを自動生成し、Gmailで関係者に共有するまでの一連の流れを自動化できます。これにより、情報収集と共有のプロセスを効率化します。■このテンプレートをおすすめする方- 定期的に技術スタックレポートを作成・共有しており、業務を効率化したい開発担当者の方
- 競合の技術動向や市場トレンドの調査を手作業で行っており、負担を感じているリサーチャーの方
- チーム内の情報共有プロセスを自動化し、生産性を高めたいと考えているプロジェクトマネージャーの方
■このテンプレートを使うメリット- スケジュール起動で調査からレポート作成、共有までを自動化するため、手作業での情報収集や資料作成に費やしていた時間を短縮できます
- 定期的な情報共有が自動で行われるため、共有漏れや遅延といったヒューマンエラーを防ぎ、安定した情報連携を実現します
■フローボットの流れ- はじめに、 Perplexity、Google スプレッドシート、Gmail をYoomと連携します
- 次に、トリガーで「スケジュールトリガー」を選択し、レポートを作成したい日時や頻度を設定します
- 最後に、オペレーションでAIワーカーを設定し、Perplexityで最新の技術スタックに関する調査を行ってレポートを生成し、Google スプレッドシートに記録、Gmailで送信するためのマニュアル(指示)」を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- スケジュールトリガーの設定では、レポートを作成したい曜日や時刻など、フローが起動するタイミングを任意で設定してください
- AIワーカーへの指示内容は、「特定のプログラミング言語に関するレポート」や「SaaS業界の最新技術スタック」など、取得したい情報に応じて自由にカスタマイズしてください
■注意事項- Perplexity、Google スプレッドシート、GmailのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
■概要ブランドのオンライン上での可視性を分析する業務は、複数のツールを横断して情報を収集する必要があり、手間のかかる作業ではないでしょうか。このワークフローを活用することで、Google スプレッドシートに行を追加するだけで、AIワーカーが自動でOpenAIやPerplexityによるブランド可視性の分析を行い、その結果をシートに反映させることが可能になり、こうした定型的な分析業務を効率化できます。■このテンプレートをおすすめする方- Google スプレッドシートでキーワードを管理し、手作業でブランドの可視性を分析しているマーケティング担当者の方
- OpenAIやPerplexityなどの生成AIを活用した情報収集や分析業務を効率化したいと考えている方
- AIワーカーを利用して、分析結果をGoogle スプレッドシートに自動で反映し、データ管理を円滑にしたい方
■このテンプレートを使うメリット- Google スプレッドシートへの行追加を起点に、一連の分析から結果の反映までを自動化するため、手作業での情報収集や転記にかかる時間を短縮できます
- 手動での分析やコピー&ペーストによる入力ミス、確認漏れといったヒューマンエラーを防ぎ、常に一定の品質で分析業務を実行することが可能です
■フローボットの流れ- はじめに、Google スプレッドシート、OpenAI、PerplexityをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、OpenAIやPerplexityを利用してブランドの可視性を分析し、改善案を生成して記録するためのマニュアル(指示)を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Google スプレッドシートのトリガー設定では、分析対象の情報を管理している任意のスプレッドシートIDと、対象のシート名(タブ名)を指定してください
- AIワーカーのオペレーションでは、分析に利用したい任意のAIモデルを選択し、ブランド可視性を分析・評価するための具体的な指示内容を業務に合わせて設定してください
■注意事項- Google スプレッドシート、OpenAI、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 定期的に技術スタックレポートを作成・共有しており、業務を効率化したい開発担当者の方
- 競合の技術動向や市場トレンドの調査を手作業で行っており、負担を感じているリサーチャーの方
- チーム内の情報共有プロセスを自動化し、生産性を高めたいと考えているプロジェクトマネージャーの方
- スケジュール起動で調査からレポート作成、共有までを自動化するため、手作業での情報収集や資料作成に費やしていた時間を短縮できます
- 定期的な情報共有が自動で行われるため、共有漏れや遅延といったヒューマンエラーを防ぎ、安定した情報連携を実現します
- はじめに、 Perplexity、Google スプレッドシート、Gmail をYoomと連携します
- 次に、トリガーで「スケジュールトリガー」を選択し、レポートを作成したい日時や頻度を設定します
- 最後に、オペレーションでAIワーカーを設定し、Perplexityで最新の技術スタックに関する調査を行ってレポートを生成し、Google スプレッドシートに記録、Gmailで送信するためのマニュアル(指示)」を作成します
■このワークフローのカスタムポイント
- スケジュールトリガーの設定では、レポートを作成したい曜日や時刻など、フローが起動するタイミングを任意で設定してください
- AIワーカーへの指示内容は、「特定のプログラミング言語に関するレポート」や「SaaS業界の最新技術スタック」など、取得したい情報に応じて自由にカスタマイズしてください
- Perplexity、Google スプレッドシート、GmailのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- Google スプレッドシートでキーワードを管理し、手作業でブランドの可視性を分析しているマーケティング担当者の方
- OpenAIやPerplexityなどの生成AIを活用した情報収集や分析業務を効率化したいと考えている方
- AIワーカーを利用して、分析結果をGoogle スプレッドシートに自動で反映し、データ管理を円滑にしたい方
- Google スプレッドシートへの行追加を起点に、一連の分析から結果の反映までを自動化するため、手作業での情報収集や転記にかかる時間を短縮できます
- 手動での分析やコピー&ペーストによる入力ミス、確認漏れといったヒューマンエラーを防ぎ、常に一定の品質で分析業務を実行することが可能です
- はじめに、Google スプレッドシート、OpenAI、PerplexityをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、OpenAIやPerplexityを利用してブランドの可視性を分析し、改善案を生成して記録するためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー設定では、分析対象の情報を管理している任意のスプレッドシートIDと、対象のシート名(タブ名)を指定してください
- AIワーカーのオペレーションでは、分析に利用したい任意のAIモデルを選択し、ブランド可視性を分析・評価するための具体的な指示内容を業務に合わせて設定してください
- Google スプレッドシート、OpenAI、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
🤖Perplexityで独自のRAG環境を構築する方法

Perplexityで自社のデータや特定の情報源を基にしたRAG環境を構築するためには、主に2つのアプローチがあります。
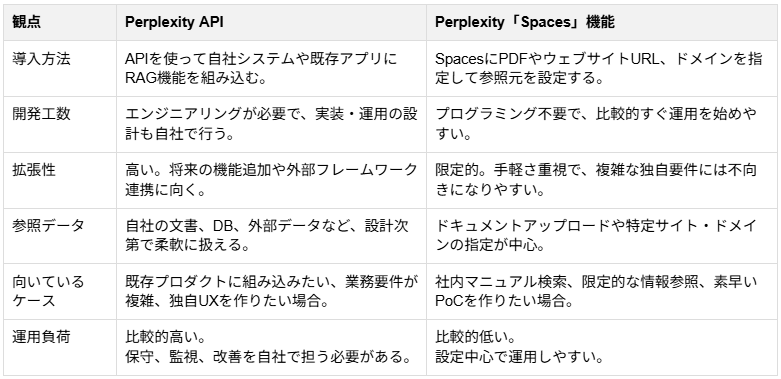
方法1:Perplexity APIを活用したRAGシステム構築
自社のシステムや既存のアプリケーションにRAG機能を組み込みたい場合は、開発者向けのAPIを利用したアプローチが推奨されます。提供されるAPIを活用することで、強力な検索モデルを外部から呼び出します。
また、LangChainやLlamaIndexといった外部のアプリケーション開発フレームワークと連携させることで、複雑なデータのチャンク化やベクトルデータベースの構築など、自社の要件に合わせた高度なパイプラインを構築できます。エンジニアのリソースは必要になりますが、機能の追加や変更が容易であり、最も自由度が高く将来の拡張性にも優れたアプローチとなります。
方法2:Spacesを使ったノーコードRAG構築
APIを利用した開発が難しい場合や、手軽に独自のRAG環境を構築したい場合に適しているのが、「Spaces」機能を活用する方法です。
Spacesは、ユーザーが任意のドキュメント(PDFファイルなど)をアップロードしたり、特定のウェブサイトのURLやドメインを指定したりすることで、それらの情報源を中心に参照しながら回答を生成できる機能です。社内マニュアルのPDFや特定の業界サイトを情報源として指定し、参照範囲を適切に調整することで、余計なノイズを抑えた回答を得る環境をノーコードで実現します。
プログラミングの知識がない担当者でも容易に運用を開始できます。
🧩Perplexity APIによるRAGパイプラインの実装例

APIを活用してRAGパイプラインを構築する場合、システム全体がどのような構成になるのかを把握することは非常に重要です。ここではAPIの役割と具体的な実装のイメージについて解説します。
▶Embeddings APIとAgent APIの役割
RAGを構築する上で欠かせないのが、テキストデータをAIが理解できるベクトルデータに変換するEmbeddings APIと、取得した情報をもとに回答生成を担うAgent APIの役割です。社内のドキュメントやマニュアルをベクトル化してデータベースに保存し、ユーザーからの質問も同様にベクトル化して関連データを検索します。
これらのAPIと外部のベクトルデータベースを組み合わせることで、ウェブ情報と社内の独自データの両方を参照し、精度の高い回答を生成するシステムを構築します。テキストの文脈や意味を数学的なベクトルとして扱うことで、単純なキーワード一致にとどまらない高度な情報検索と推論のプロセスを実現します。
▶社内ナレッジベースにRAGを組み込む構成例
具体的な構成例として、社内ポータルやチャットツールにRAGボットを組み込むケースが挙げられます。社員がチャット上で質問を投げかけると、システムが自社のナレッジベース(社内Wikiや共有ドライブ内のドキュメント)を検索し、同時にAPIを通じてウェブ上の関連情報も検索します。この両方の情報を統合し、文脈に沿った回答を社内ツールに直接返します。
このようなシステムを構築することで、社員が情報を探すために複数のツールを横断する手間を省き、日々の業務における情報アクセスの効率を飛躍的に高めることが期待されます。
社内の知見と外部のデータの融合がスムーズに行われます。
💻Perplexity SpacesでRAGを検証してみた

開発不要で利用できる「Spaces」機能がどれほどの精度を持っているのか、実際に特定のドキュメントとウェブサイト情報に限定したRAG環境を設定して検証を行いました。
▶検証の手順
特定の製品マニュアルのPDFファイルと、関連する公式ヘルプページのURLをSpacesに登録していきます。
まずはPerplexityの公式サイトにアクセスし、左のメニューから「スペース」を選択します。
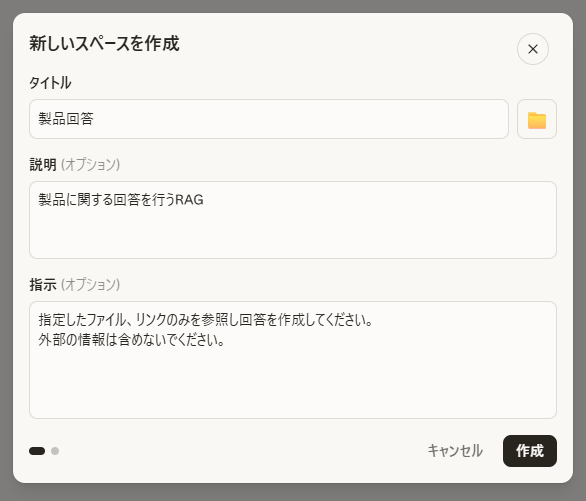
画面右上の「+新しいスペース」を選択します。
作成するスペースの詳細設定欄が表示されるので、
- タイトル
- 説明(スペースの目的)
- 指示 (カスタム指示)
を入力します。最後に「作成」をクリックしましょう。
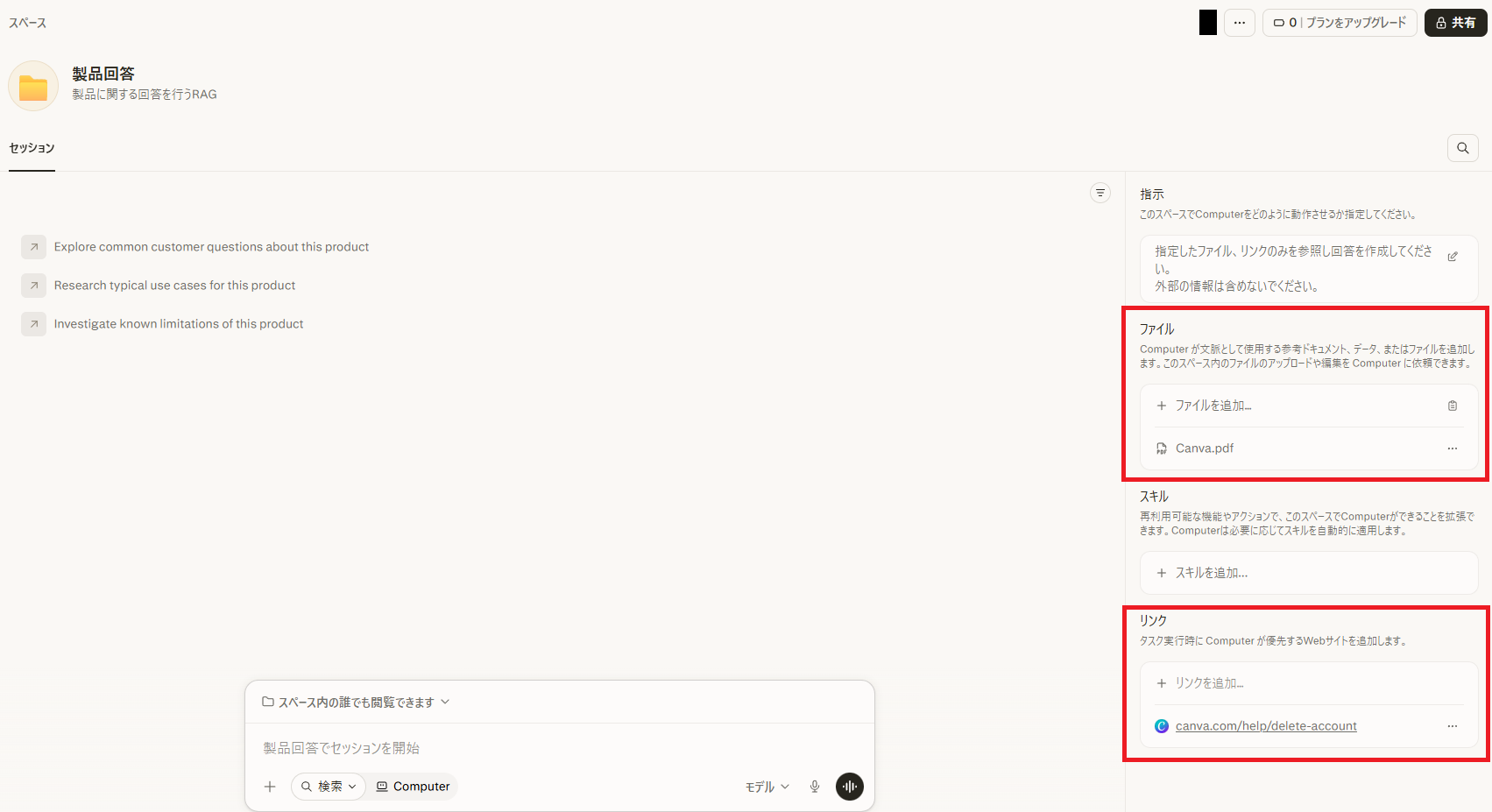
作成が完了したらファイルとURLを設定します。
今回の検証では、ビジュアルデザインツール「Canva」に関するPDFファイルと公式ヘルプページを設定していきます。
- ファイル:「+ファイルを追加」から該当ファイルを選択しアップロード
- リンク:「+リンクを追加」に該当URLをコピペし、「リンクを追加」をクリック
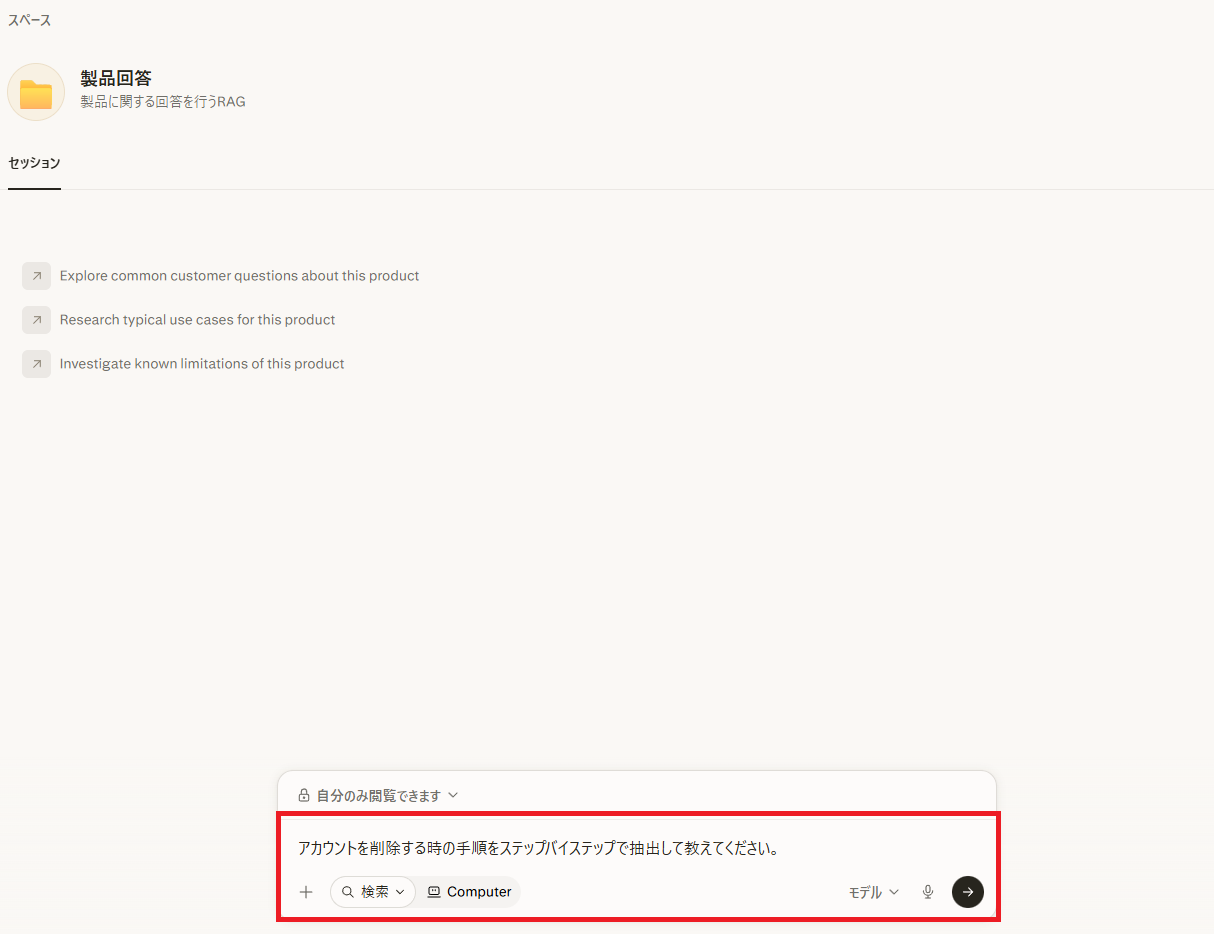
全ての設定が完了したら、セクション内で質問を行います。
【質問】
アカウントを削除する時の手順をステップバイステップで抽出して教えてください。
▶検証結果
最初はPDFファイルのみを参照した回答が出力されました。
PDFファイルにはアカウント削除の方法だけでなく、登録方法や作り方についても記載されていましたが、PDF内の情報が的確に抽出されていました。
また、回答文の末尾には参照した該当箇所へのリンクが提示されており、回答の根拠を容易に確認できます。特定の社内規定の参照や専門的なサポート向けAIツールとして、ノーコードでも十分に実用可能であると評価できます。

次に、PDFファイルを削除し、公式ヘルプページのリンクのみの状態で同じ質問を行ったところ、URL内のテキストから情報を的確に抽出し、整理された手順が生成されました。
画面下には「21件のソース」が表示されているものの、実際の回答文末に提示されたソースは指定したURLのみでした。内容を確認しても、回答は指定したURLの情報に基づいて生成されていることが確認できました。
結論として、手軽に精度の高いRAG環境を構築する手段として有効であると実感しました。

⚠️PerplexityでRAGを導入する際の注意点

独自のRAG環境を構築することは業務効率化に直結しますが、ビジネスの現場で実際に運用するにあたってはいくつか気をつけるべきポイントが存在します。
1.セキュリティ・情報漏洩リスクへの対策
社内の機密情報や顧客データを含むドキュメントをアップロードしてRAG環境を構築する場合、セキュリティと情報漏洩のリスクへの対策が強く求められます。Freeプランや標準的なProプランでは、入力したデータがAIの学習モデルの改善に利用される可能性があるため、機密性の高いデータを扱う際は格別の注意が必要です。
企業で本格的に導入する際は、学習データとしての利用を除外するオプションやSAMLによるシングルサインオン、高度なデータ保護機能が備わったEnterpriseプランの利用を検討し、自社の情報セキュリティポリシーに準拠した厳格な運用ルールを策定することが重要です。
【Perplexityの料金プラン】
- Free:無料/基本的な検索機能を制限付きで利用できます。
- Pro(個人向け):$20/月/より高度なAIモデルが利用可能
- Max(個人向け):$200/月/最新・最上位のAIモデルに加え、より多い利用上限や優先的な処理、高度な機能が利用可能
- Enterprise Pro(法人向け):$40/月/席/チーム管理やセキュリティ機能が追加
- Enterprise Max (法人向け):$325/月/席/Enterprise Proの機能に加え、最上位モデルの利用や大幅に拡張された利用上限
2.人によるファクトチェックの重要性
RAG技術によってハルシネーションのリスクは大きく低減し、回答には明確な出典が明記されるようになります。しかし、AIが文脈を誤解して情報を要約したり、元の情報源自体に誤りがあったりする可能性は依然としてゼロではありません。
生成された回答をそのまま無条件に採用するのではなく、特に業務上の重要な意思決定や、顧客への外部発信に使用する文章を作成する際には、AIが提示した出典元のリンクを必ず確認する手順が必要です。人間による最終的なファクトチェックを行うプロセスを業務フローに組み込むことが不可欠であり、AIはあくまで調査を補助するツールであるという前提のもとで運用を行います。
【確認ポイント】
- AIが提示した出典元を実際に開き、回答内容と一致しているか確認する
- 参照している情報が最新の内容であり、更新日が古くないか確認する
- 複数の情報源と照らし合わせ、内容に矛盾や誤りがないか確認する
- 顧客向け資料や重要な意思決定に利用する場合は、担当者や専門家による最終確認を実施する
🖊️まとめ
PerplexityのRAGは、AI特有の情報の不確実性を抑え、ビジネスの現場でも活用しやすくする有力な仕組みと言えます。自社の開発要件に応じたAPI連携や、手軽に導入できるSpaces機能を活用することで、どのような規模の企業でも高精度な独自のナレッジエンジンを構築できる点が最大の魅力です。
AIツールの本格的な導入にハードルを感じている方も、まずは少量のドキュメントを用いたノーコードでの検証など、小さな範囲から実際に触れてみてはいかがでしょうか。日々の情報収集や意思決定の質が大きく変わる体験を通じて、自社の業務プロセスをさらに洗練されたものへと引き上げるための第一歩を、ぜひこの機会に踏み出してみてください!
💡Yoomでできること
Yoomは、業務を自動化するハイパーオートメーションプラットフォームです。
これまで手動で利用していた各ツールをメインとした自動化フローが、直感的な操作で実現可能です。もし自動化に少しでも興味を持っていただけたなら、ぜひ登録フォームから無料登録して、Yoomによる業務効率化を体験してみてください。
■概要日々の業務における情報収集では、関連情報をリサーチし、その中から有益な情報を見極めて要約するといった手間のかかる作業が発生します。 このワークフローを活用すれば、Telegramでキーワードを受け取ったらAIワーカーが Perplexityでリサーチを行い、さらに 情報の有益性を自律的に判定して要約・通知するまでの一連のプロセスを自動化し、情報収集業務の効率化を実現します。■このテンプレートをおすすめする方- PerplexityとTelegramを活用した情報収集プロセスを自動化したい方
- AIワーカーにリサーチ情報の有益性を自律的に判定させ、業務を効率化したい方
- 手作業での情報収集と要約作成に時間がかかり、本来の業務に集中できない方
■このテンプレートを使うメリット- Telegramへのキーワード投稿を起点にリサーチから要約、通知までが自動処理されるため、情報収集にかかる作業時間を短縮できます。
- AIワーカーが設定された基準で情報を処理するため、人による判断のばらつきや見落としを防ぎ、リサーチ品質の均一化が図れます。
■フローボットの流れ- はじめに、PerplexityとTelegramをYoomと連携します。
- 次に、トリガーでTelegramの「ボットがメッセージを受け取ったら」を選択し、リサーチしたいキーワードの受信を検知できるように設定します。
- 最後に、オペレーションでAIワーカーを設定し、Perplexityでのリサーチから有益性などの判定、要約、通知を行うためのマニュアル(指示)を作成します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- AIワーカーでは、情報の有益性判定や要約に使用するAIモデルを選択し、どのような基準で判定・要約を行うか、具体的な指示を任意で設定してください。
- Perplexityの情報検索のモデルやプロンプト、Telegramの送信先チャットなども自由にカスタマイズできます。
■注意事項- Telegram、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
■概要Telegramで受け取ったメッセージから有望なリード情報を探し出し、リスト化する作業に手間を感じていませんか?関連情報を手作業で検索し、転記するプロセスは時間がかかるだけでなく、入力ミスなどのリスクも伴います。このワークフローを活用すれば、Telegramのメッセージ受信をきっかけに、AIがPerplexityを用いてWeb上の情報を検索し、有望な企業のリード情報を自動で生成します。生成された情報はGoogle スプレッドシートへ自動的に追加されるため、リード生成に関わる一連の業務を効率化できます。■このテンプレートをおすすめする方- Telegramを活用し、より効率的なリード生成の仕組みを構築したいと考えている方
- PerplexityなどのAIを使い、Webからの情報収集やリスト作成を自動化したい方
- Google スプレッドシートへの手入力をなくし、リード管理を効率化したい担当者の方
■このテンプレートを使うメリット- Telegramのメッセージ受信を起点にリード生成からリスト追加までを自動化し、情報収集や入力作業にかかる時間を短縮します
- 手作業での情報検索や転記が不要になるため、入力ミスや抜け漏れといったヒューマンエラーを防ぎ、データの正確性を保ちます
■フローボットの流れ- はじめに、Telegram、Perplexity、Google スプレッドシートをYoomと連携します
- 次に、トリガーでTelegramを選択し、「ボットがメッセージを受け取ったら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを設定し、受け取ったメッセージ内容を基に、Perplexityでリード企業情報の検索や親和性の判定を行いGoogle スプレッドシートに記録するためのマニュアル(指示)を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション■このワークフローのカスタムポイント- AIワーカーへの指示内容は、目的に応じて自由にカスタマイズが可能です。例えば、Perplexityで検索する情報の種類(企業概要、ニュース記事など)や、リードとしての親和性を判断する基準を任意で設定できます
- Google スプレッドシートに出力する項目(企業名、WebサイトURL、判定理由など)も、AIワーカーへの指示内容によって柔軟に変更できます
■注意事項- Telegram、Perplexity、Google スプレッドシートのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- PerplexityとTelegramを活用した情報収集プロセスを自動化したい方
- AIワーカーにリサーチ情報の有益性を自律的に判定させ、業務を効率化したい方
- 手作業での情報収集と要約作成に時間がかかり、本来の業務に集中できない方
- Telegramへのキーワード投稿を起点にリサーチから要約、通知までが自動処理されるため、情報収集にかかる作業時間を短縮できます。
- AIワーカーが設定された基準で情報を処理するため、人による判断のばらつきや見落としを防ぎ、リサーチ品質の均一化が図れます。
- はじめに、PerplexityとTelegramをYoomと連携します。
- 次に、トリガーでTelegramの「ボットがメッセージを受け取ったら」を選択し、リサーチしたいキーワードの受信を検知できるように設定します。
- 最後に、オペレーションでAIワーカーを設定し、Perplexityでのリサーチから有益性などの判定、要約、通知を行うためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- AIワーカーでは、情報の有益性判定や要約に使用するAIモデルを選択し、どのような基準で判定・要約を行うか、具体的な指示を任意で設定してください。
- Perplexityの情報検索のモデルやプロンプト、Telegramの送信先チャットなども自由にカスタマイズできます。
- Telegram、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
- Telegramを活用し、より効率的なリード生成の仕組みを構築したいと考えている方
- PerplexityなどのAIを使い、Webからの情報収集やリスト作成を自動化したい方
- Google スプレッドシートへの手入力をなくし、リード管理を効率化したい担当者の方
- Telegramのメッセージ受信を起点にリード生成からリスト追加までを自動化し、情報収集や入力作業にかかる時間を短縮します
- 手作業での情報検索や転記が不要になるため、入力ミスや抜け漏れといったヒューマンエラーを防ぎ、データの正確性を保ちます
- はじめに、Telegram、Perplexity、Google スプレッドシートをYoomと連携します
- 次に、トリガーでTelegramを選択し、「ボットがメッセージを受け取ったら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを設定し、受け取ったメッセージ内容を基に、Perplexityでリード企業情報の検索や親和性の判定を行いGoogle スプレッドシートに記録するためのマニュアル(指示)を作成します
- AIワーカーへの指示内容は、目的に応じて自由にカスタマイズが可能です。例えば、Perplexityで検索する情報の種類(企業概要、ニュース記事など)や、リードとしての親和性を判断する基準を任意で設定できます
- Google スプレッドシートに出力する項目(企業名、WebサイトURL、判定理由など)も、AIワーカーへの指示内容によって柔軟に変更できます
- Telegram、Perplexity、Google スプレッドシートのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
プログラミング知識なしで手軽に構築できます。







