








・
Qwenの画像生成って実際どう?日本語描写の正確さとリアルな質感、部分修正の性能をチェック

画像生成AIの世界において、テキストの正確な描写は長年の課題でした。
特に漢字やひらがなといった複雑な形状を持つ日本語は、多くのモデルが「文字化け」を起こし、実用性に欠ける場面が多々ありました。
こうした中で、Alibaba(アリババ)のAIチームが開発した「Qwen-Image」は、200億という膨大なパラメータ数と独自の設計により、従来の壁を打ち破る可能性を秘めています。
本記事では、このオープンソースモデルが持つ真の実力を、日本語描写と写真のようなリアルな質感、そして一貫性を保った部分編集という3つの視点から詳しく探ります。
単なる画像生成にとどまらない、デザインやビジネスの現場で求められる「制御のしやすさ」と「表現の正確性」に焦点を当てて検証しました。
✍️Qwen-Imageとは?世界が注目する画像生成AI
Qwen-Imageは、Alibaba CloudのAI研究チームによって開発された、オープンソースの強力な画像生成モデルです。
200億ものパラメータを持つこのモデルは、視覚情報とテキスト情報を極めて高い解像度で相互に処理できる点が最大の特徴です。
以下にその核となる技術や特徴を紹介します。
200億パラメータがもたらす圧倒的な描写力
200億パラメータという規模は、オープンソースの画像生成モデルの中でもトップクラスの容量です。
この膨大なデータ量により、AIは単にプロンプトに従って画像を構成するだけでなく、物体の質感や光の反射、影の落ち方といった微細なディテールまでを「理解」して描写します。
例えば、人間の肌の毛穴や産毛、複雑な金属の表面反射など、これまでのモデルでは平坦になりがちだった部分も、Qwen-Imageであれば実写と見紛うほどの密度で表現が可能です。
MMDiT構造によるテキストと画像の高度な融合
Qwen-Imageは、MMDiT(Multimodal Diffusion Transformer)という先進的な構造を採用しています。
これはテキストと画像の情報を別々の経路で処理しつつ、同時並行で協調させる技術です。
これにより、プロンプトに含まれる詳細な条件を画像内の適切な場所に配置する能力が向上しました。特に「どの場所にどの文字を置くか」といったレイアウトの指示にも正確に応答できるため、デザイン案の作成やポストカードのレイアウトなど、配置が重要となるタスクでその真価を発揮します。
元の構図を維持したままのスタイル変更
Qwen-Image-Editは、画像全体の雰囲気を壊さずに特定の要素だけを入れ替える能力に優れています。
従来の編集機能では、一部を書き換えようとすると周囲のピクセルも再計算され、構図が微妙に変わってしまうことがありました。
しかし、Qwen-Imageは「保持すべき情報」を的確に識別するため、背景の夜景や地面の反射パターンを維持したまま、被写体だけをターゲットにして編集できます。
これにより、試行錯誤を繰り返すプロフェッショナルなクリエイティブ現場でも、ストレスなく修正作業が行えます。
複数画像参照による高精度なアイテム合成
編集機能では、最大3枚までの画像を参照して一貫性を保つことが可能です。
例えば、ある画像の背景だけ利用し、そこに別画像の人物などを合成するといった使い方ができます。
また、人物の顔立ちや体型を固定したまま、アイテムだけを差し替えることができるため、ファッション業界での着せ替えシミュレーションや、商品画像のバリエーション展開に非常に有効です。
参照画像の情報を正確に抽出し、ターゲット画像へ自然に馴染ませる合成精度は驚異的です。
✅Qwen-Imageを利用するための具体的な手順
Qwen-Imageは、ユーザーのスキルやPC環境に合わせて、主に3つの方法で利用することができます。
Qwen Chat(公式ウェブサイト)
Qwen-Imageを最も手軽に体験できるのが、公式に提供されている「Qwen Chat」です。
特別なインストール作業は不要で、ブラウザからプロンプトを入力するだけで画像生成やチャット形式での対話が行えます。
画像生成AIに触れるのが初めての方や、モデルの性能をまず試してみたいユーザーに最適です。
無料で公開されている範囲でも、テキスト描画の正確性やリアルな質感を十分に体感できます。
また、画像をアップロードしてその内容について質問したり、指示を出したりすることも可能です。
Hugging Face(オープンモデルの活用)
開発者やより深いカスタマイズを求めるユーザー向けには、AIプラットフォーム「Hugging Face」上でモデルのウェイトが公開されています。
ここからモデルをダウンロードすることで、自社のサーバーやプログラムに組み込むことができます。
Apache 2.0などの自由度の高いライセンスで提供されていることが多いため、商用利用や独自の研究、特定のデータセットを用いた追加学習(ファインチューニング)にも対応可能です。
世界中のコミュニティが開発した派生モデルや、軽量化されたモデルを探すのにも役立ちます。
ローカル実行環境(ComfyUI)

自分のPC上でプライバシーを保ちつつ、詳細なパラメータ調整を行いたい場合は「ComfyUI」などのローカル実行環境がおすすめです。
Qwen-Imageは200億パラメータを持つため、快適な動作にはVRAM 16GB以上の高性能なGPUが必要ですが、量子化と呼ばれる軽量化技術を適用したモデルを使えば、一般的なゲーミングPC(VRAM 8〜12GB)でも動作可能です。
ComfyUIのノードベースの画面で、ノイズの調整やステップ数の設定を追い込むことで、モデルの持つ潜在能力を最大限に引き出した高品質な出力を得られます。
⭐Yoomは画像生成プロンプトの作成を自動化できます
Qwenで生成した画像を、チームメンバーやクライアントに共有する作業を手間に感じることはありませんか。
そうした付随する作業を自動化できるのが、Yoomです。
例えば、Google Driveに保存した画像をSlackで共有したり、OneDriveに保存した画像をOutlookで共有したりしたい場合に、Yoomは強力な味方となります。
■概要OneDriveにアップロードされた請求書や報告書などの重要なファイルの共有が遅れたり、関係者への通知が漏れてしまったりすることはないでしょうか。
手動でのメール作成とファイル添付は手間がかかるだけでなく、ミスの原因にもなります。
このワークフローを活用すれば、OneDriveへのファイル追加をきっかけに、Outlookからメールが自動送信されるため、迅速で確実な情報共有が実現します。
■このテンプレートをおすすめする方- OneDriveでのファイル共有を頻繁に行い、手動での通知に手間を感じている方
- 請求書や報告書などの重要なファイルの共有漏れや遅延を防止したいと考えている方
- Outlookを使った定型的なメール連絡を自動化し、業務効率を向上させたい方
■このテンプレートを使うメリット- OneDriveへのファイル追加からメール送信までが自動化されるため、これまで手作業で行っていたファイル確認やメール作成の時間を削減できます。
- ファイルの添付忘れや宛先の間違いといったヒューマンエラーを防ぎ、確実な情報共有を実現します。
■フローボットの流れ- はじめに、OneDriveとOutlookをYoomと連携します。
- 次に、トリガーでOneDriveの「特定フォルダ内にファイルが作成または更新されたら」というアクションを設定します。
- 続けて、オペレーションでOneDriveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知したファイルを取得します。
- さらに、AI機能「テキストを生成する」や「データを操作・変換する」のアクションを設定し、ファイル名などの情報をもとにテキストを生成および対照データを変換します。
- 最後に、オペレーションでOutlookの「メールを送る」アクションを設定し、ダウンロードしたファイルを添付して指定の宛先にメールを送信します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- AI機能の「テキストを生成する」では、AIへの指示(プロンプト)を任意に設定できます。
- 「データを操作・変換する」を用いることで、ファイル名から日付を抽出するなど、通知内容に合わせて情報を加工できます。
- 「メールを送る」では、前のステップで取得したファイル名などの情報を変数として埋め込むことで、内容に応じた動的な通知の作成が可能です。
■注意事項- OneDriveとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
手動でのメール作成とファイル添付は手間がかかるだけでなく、ミスの原因にもなります。
このワークフローを活用すれば、OneDriveへのファイル追加をきっかけに、Outlookからメールが自動送信されるため、迅速で確実な情報共有が実現します。
■このテンプレートをおすすめする方
- OneDriveでのファイル共有を頻繁に行い、手動での通知に手間を感じている方
- 請求書や報告書などの重要なファイルの共有漏れや遅延を防止したいと考えている方
- Outlookを使った定型的なメール連絡を自動化し、業務効率を向上させたい方
■このテンプレートを使うメリット
- OneDriveへのファイル追加からメール送信までが自動化されるため、これまで手作業で行っていたファイル確認やメール作成の時間を削減できます。
- ファイルの添付忘れや宛先の間違いといったヒューマンエラーを防ぎ、確実な情報共有を実現します。
■フローボットの流れ
- はじめに、OneDriveとOutlookをYoomと連携します。
- 次に、トリガーでOneDriveの「特定フォルダ内にファイルが作成または更新されたら」というアクションを設定します。
- 続けて、オペレーションでOneDriveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知したファイルを取得します。
- さらに、AI機能「テキストを生成する」や「データを操作・変換する」のアクションを設定し、ファイル名などの情報をもとにテキストを生成および対照データを変換します。
- 最後に、オペレーションでOutlookの「メールを送る」アクションを設定し、ダウンロードしたファイルを添付して指定の宛先にメールを送信します。
■このワークフローのカスタムポイント
- AI機能の「テキストを生成する」では、AIへの指示(プロンプト)を任意に設定できます。
- 「データを操作・変換する」を用いることで、ファイル名から日付を抽出するなど、通知内容に合わせて情報を加工できます。
- 「メールを送る」では、前のステップで取得したファイル名などの情報を変数として埋め込むことで、内容に応じた動的な通知の作成が可能です。
■注意事項
- OneDriveとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
🤔【検証1】日本語描写とフォトリアルな質感の両立をテスト
ここでは、Qwen Chatを利用し、日本語テキストの正確性と写真のようなリアルな表現を検証します。
Qwen-Imageを利用し、以下のプロンプトで画像を生成してみました。
【検証プロンプト】
雨上がりの夜の東京の街角。濡れたアスファルトにネオンが反射している。画面中央におしゃれな木製の看板があり、そこには「和食カフェ あかり」という文字が美しい漢字とひらがなで刻まれている。背景にはぼけた街の明かりが映り、全体が一眼レフカメラで撮影したような高品質でリアルな質感の画像
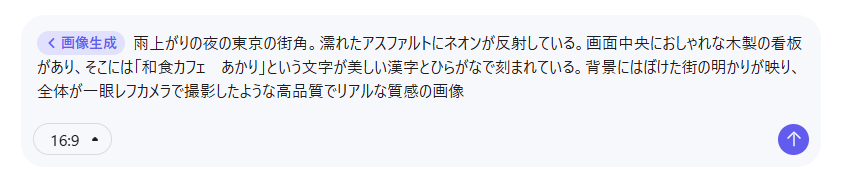
生成結果
上記のプロンプトで、以下の画像が生成されました。

検証結果
実際に画像を生成して、以下のことがわかりました。
- 漢字とひらがなは正確だが、カタカナや長文の再現には課題が残る
- ロゴ作成程度なら実用的だが、長い店名や文章などはまだ難しい
- 雨に濡れた路面や光の反射など、写真レベルの質感が表現できる
日本語テキストの生成において、漢字やひらがなは正確に再現されており、単語レベルのロゴ制作などであれば十分に実用可能なレベルに達しています。
一方で、カタカナの描写精度やスペースが記号に変換されてしまう点、長文の生成にはまだ課題があり、完璧ではありません。
しかし、かつての画像生成AIのような解読不能な文字化けは解消されており、無料ツールとしては驚くべき性能です。
また画質の面では、雨に濡れたアスファルトの質感や、街灯が水たまりに反射する様子など、細部まで写真そのものと言えるクオリティでした。
木目のディテールや光の表現も極めて自然で、テキスト描写の進化と相まって、高い実用性を感じさせる結果となりました。
🤔【検証2】Qwen-Image-Editによる一貫性を保った部分編集
次に、生成した画像の一部を変更する編集機能「Qwen-Image-Edit」の実力を検証します。
検証1で生成した画像の看板の材質だけを変更してみます。
【検証プロンプト】
添付した画像の木の看板をコルクボード風に変更してください。背景の街並みや雨上がりの質感、文字、全体の構図は一切変えずに、看板の材質のみを自然に変更してください
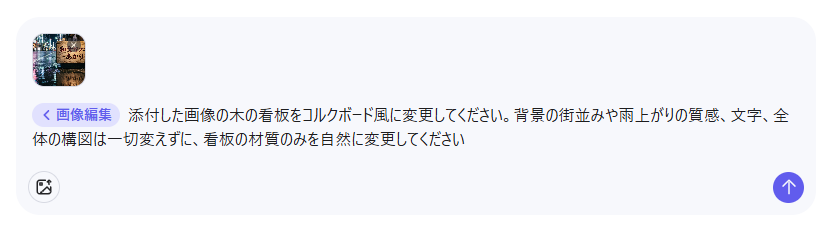
生成結果
上記のプロンプトで生成された画像は、以下になります。

【検証1の生成画像】

検証結果
画像を編集して、以下のことがわかりました。
- 看板の材質のみを変更し、背景や雨粒などの細部は完全に維持
- 他モデルで起きがちな、周辺箇所の意図しない変化が発生しなかった
- 部分編集における情報維持能力と精度が極めて高い
特筆すべきは、画像の編集精度です。
今回の検証では看板の材質変更のみを指示しましたが、背景の街並みや複雑な雨粒の描写といった「変更すべきでない箇所」が完全に維持されました。
通常、DALL-E 3などの主要モデルであっても、部分的な修正を行う際に周囲の構図や細部が再計算され、微妙に変化してしまうことがあります。
しかし、Qwen-Imageは元画像の情報を完璧に保持したまま、ターゲットとした看板部分だけを自然に編集しました。
無料で利用できるモデルでありながら、雨粒一つ変えずに編集できるこの制御能力は驚異的であり、デザインの微調整が必要なクリエイティブな現場において、極めて優秀なモデルであると断言できます。
🖊️まとめ:Qwen-Imageは表現の幅をどう広げるのか
Qwen-Imageの登場は、画像生成AIが「ただ絵を描く」段階から「正確な意図を視覚化する」段階へと進化したことを象徴しています。
まだ日本語テキストの描写には課題が残りますが、実写のようなリアルな質感と、一貫性を保ったまま細部を調整できる編集機能を兼ね備えています。
単なる趣味の範疇を超え、プロトタイピングやコンテンツ制作の現場で即戦力となるはずです。
オープンソースとして公開されているため、今後も世界中の開発者によってさらなる高速化や機能拡張が進んでいくことが予想されます。
自身の創造力を具現化するための強力なパートナーとして、このAIを使いこなしていくことが、これからのデジタルクリエイティブにおける1つのスタンダードになるかもしれません。
💡Yoomでできること
Yoomを活用すれば、Qwenで画像を生成した後の工程を自動化できます。
- 生成画像のチェック:生成した画像が仕様通りか自動で確認して通知する
- ファイルの圧縮保存:生成した画像を自動で圧縮してフォルダに保存する
■概要Google Driveにアップロードされる画像を都度確認し、その内容をチームに共有する作業に手間を感じていませんか。このワークフローを活用することで、Google Driveに新しい画像が追加されると、Geminiが自動で画像内容を解析し、その結果をChatworkへ即座に通知する一連の流れを自動化でき、手作業による画像確認や報告の手間を省くことが可能です。■このテンプレートをおすすめする方- Google Driveにアップされる画像の内容を定期的に確認・共有しているご担当者の方
- AIを活用して、画像に写っているオブジェクトの特定や説明文の生成を自動化したい方
- 日々の定型業務を効率化し、より創造的な業務に時間を割きたいと考えているすべての方
■このテンプレートを使うメリット- Google Driveへの画像アップロードを起点に、Geminiでの解析とChatworkへの通知が自動で実行されるため、これまで手作業に費やしていた時間を短縮できます。
- 手作業による画像の見落としや、報告内容の転記ミスといったヒューマンエラーの発生を防ぎ、業務の正確性を高めます。
■フローボットの流れ- はじめに、Google Drive、Gemini、ChatworkをYoomと連携します。
- 次に、トリガーでGoogle Driveを選択し、「新しくファイル・フォルダが作成されたら」というアクションを設定し、監視したいフォルダを指定します。
- 続いて、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知した画像ファイルを取得します。
- 次に、オペレーションでGeminiの「ファイルをアップロード」アクションと「コンテンツを生成(ファイルを利用)」アクションを設定し、画像の内容を解析させます。
- 最後に、オペレーションでChatworkの「メッセージを送る」アクションを設定し、Geminiが生成した内容を指定したチャットルームに通知します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション■このワークフローのカスタムポイント- Geminiの「コンテンツを生成(ファイルを利用)」アクションでは、どのような情報を画像から抽出したいか、プロンプトを自由にカスタマイズして設定することが可能です。
- Chatworkの「メッセージを送る」アクションでは、通知先のルームIDを任意で設定できるほか、メッセージ内容に固定のテキストを追加したり、Geminiの解析結果などの動的な値を埋め込んだりすることができます。
■注意事項- Google Drive、Gemini、SlackのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
■概要
フォームで受け取った画像ファイルの管理、特に圧縮してから特定の場所に保存する作業に手間を感じていませんか。一つ一つ手作業で対応していると時間がかかるだけでなく、圧縮漏れや保存先の間違いといったミスも起こりやすくなります。このワークフローは、フォームに投稿された画像をRPA機能が自動で圧縮し、Dropboxの指定フォルダに保存するため、こうした一連の作業を自動化し、ファイル管理業務を効率化します。
■このテンプレートをおすすめする方
- フォームで収集した画像の圧縮やファイル管理に手間を感じているご担当者の方
- RPAとDropboxを連携させ、手作業によるファイル保存業務を自動化したい方
- オンラインストレージの容量を節約するため、画像を圧縮して保存したい方
■このテンプレートを使うメリット
- フォーム投稿を起点に画像の圧縮から保存までが自動化され、手作業に費やしていた時間を短縮することができます。
- 手作業によるファイルの圧縮漏れや、指定フォルダへの保存ミスといったヒューマンエラーを防ぎ、業務の正確性を高めます。
■フローボットの流れ
- はじめに、DropboxをYoomと連携します。
- 次に、トリガーでフォームトリガーを選択し、「フォームが送信されたら」というアクションを設定し、ファイルアップロード項目を設けます。
- 次に、オペレーションでRPA機能の「ブラウザを操作する」アクションを設定し、フォームから受け取った画像をオンライン圧縮サイトなどで圧縮する一連のブラウザ操作を記録します。
- 最後に、オペレーションでDropboxの「ファイルをアップロードする」アクションを設定し、RPAによって圧縮、保存されたファイルを指定のフォルダにアップロードします。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガーで設定するフォームは、画像ファイル以外にもテキスト入力欄など、業務に必要な項目を自由に追加・編集できます。
- RPA機能の「ブラウザを操作する」アクションでは、利用したい画像圧縮サイトのURLや、操作対象のボタンなどを任意で設定してください。
- Dropboxにファイルをアップロードする際、保存先のフォルダやファイル名を任意で設定できます。
■注意事項
- DropboxとYoomを連携してください。
- ブラウザを操作するオペレーションはサクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプラン・チームプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやブラウザを操作するオペレーションを使用することができます。
- ブラウザを操作するオペレーションの設定方法は下記をご参照ください。
https://intercom.help/yoom/ja/articles/9099691
- Google Driveにアップされる画像の内容を定期的に確認・共有しているご担当者の方
- AIを活用して、画像に写っているオブジェクトの特定や説明文の生成を自動化したい方
- 日々の定型業務を効率化し、より創造的な業務に時間を割きたいと考えているすべての方
- Google Driveへの画像アップロードを起点に、Geminiでの解析とChatworkへの通知が自動で実行されるため、これまで手作業に費やしていた時間を短縮できます。
- 手作業による画像の見落としや、報告内容の転記ミスといったヒューマンエラーの発生を防ぎ、業務の正確性を高めます。
- はじめに、Google Drive、Gemini、ChatworkをYoomと連携します。
- 次に、トリガーでGoogle Driveを選択し、「新しくファイル・フォルダが作成されたら」というアクションを設定し、監視したいフォルダを指定します。
- 続いて、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知した画像ファイルを取得します。
- 次に、オペレーションでGeminiの「ファイルをアップロード」アクションと「コンテンツを生成(ファイルを利用)」アクションを設定し、画像の内容を解析させます。
- 最後に、オペレーションでChatworkの「メッセージを送る」アクションを設定し、Geminiが生成した内容を指定したチャットルームに通知します。
- Geminiの「コンテンツを生成(ファイルを利用)」アクションでは、どのような情報を画像から抽出したいか、プロンプトを自由にカスタマイズして設定することが可能です。
- Chatworkの「メッセージを送る」アクションでは、通知先のルームIDを任意で設定できるほか、メッセージ内容に固定のテキストを追加したり、Geminiの解析結果などの動的な値を埋め込んだりすることができます。
- Google Drive、Gemini、SlackのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
■概要
フォームで受け取った画像ファイルの管理、特に圧縮してから特定の場所に保存する作業に手間を感じていませんか。一つ一つ手作業で対応していると時間がかかるだけでなく、圧縮漏れや保存先の間違いといったミスも起こりやすくなります。このワークフローは、フォームに投稿された画像をRPA機能が自動で圧縮し、Dropboxの指定フォルダに保存するため、こうした一連の作業を自動化し、ファイル管理業務を効率化します。
■このテンプレートをおすすめする方
- フォームで収集した画像の圧縮やファイル管理に手間を感じているご担当者の方
- RPAとDropboxを連携させ、手作業によるファイル保存業務を自動化したい方
- オンラインストレージの容量を節約するため、画像を圧縮して保存したい方
■このテンプレートを使うメリット
- フォーム投稿を起点に画像の圧縮から保存までが自動化され、手作業に費やしていた時間を短縮することができます。
- 手作業によるファイルの圧縮漏れや、指定フォルダへの保存ミスといったヒューマンエラーを防ぎ、業務の正確性を高めます。
■フローボットの流れ
- はじめに、DropboxをYoomと連携します。
- 次に、トリガーでフォームトリガーを選択し、「フォームが送信されたら」というアクションを設定し、ファイルアップロード項目を設けます。
- 次に、オペレーションでRPA機能の「ブラウザを操作する」アクションを設定し、フォームから受け取った画像をオンライン圧縮サイトなどで圧縮する一連のブラウザ操作を記録します。
- 最後に、オペレーションでDropboxの「ファイルをアップロードする」アクションを設定し、RPAによって圧縮、保存されたファイルを指定のフォルダにアップロードします。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガーで設定するフォームは、画像ファイル以外にもテキスト入力欄など、業務に必要な項目を自由に追加・編集できます。
- RPA機能の「ブラウザを操作する」アクションでは、利用したい画像圧縮サイトのURLや、操作対象のボタンなどを任意で設定してください。
- Dropboxにファイルをアップロードする際、保存先のフォルダやファイル名を任意で設定できます。
■注意事項
- DropboxとYoomを連携してください。
- ブラウザを操作するオペレーションはサクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプラン・チームプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやブラウザを操作するオペレーションを使用することができます。
- ブラウザを操作するオペレーションの設定方法は下記をご参照ください。
https://intercom.help/yoom/ja/articles/9099691
画像生成に付随する作業を手作業で行っている方は、ノーコードで業務フローを自動化できるYoomをぜひ検討してみてください。
【出典】
Qwen-Image: Crafting with Native Text Rendering/Qwen Chat/Qwen/Qwen-Image · Hugging Face/GitHub - QwenLM/Qwen-Image: Qwen-Image is a powerful image generation foundation model capable of complex text rendering and precise image editing./ComfyUI
プログラミング知識なしで手軽に構築できます。







