








・
【初心者向け】画像生成AIでキャラを固定するコツと3つの基本

- 🎨画像生成AIで「キャラ固定」が重要な理由
- ⚙️画像生成AIでキャラ固定を実現する3つの基本原理
- 🤖 Yoomは画像生成AIの運用を自動化できます
- ✅【検証】ChatGPTでキャラクター固定を成功させる方法
- ✅Gemini(Nano-Banana)でキャラクターを固定する方法【検証】
- 🎉その他のツール(Midjourney・Stable Diffusion)でのキャラ固定方法
- 🔄生成後に顔を修正する「Faceswap(顔入れ替え)」という最終解決策
- 🛠️全ツール共通!画像生成AIでキャラ固定を成功させる「3つのコツ」と「鉄則」
- 🚩まとめ:制作スタイルに合わせた最適なキャラ固定ツールを選ぼう
- ⚙️Yoomでできること
「AIで生成したキャラの顔や髪型が、ポーズを変えるたびに別人になってしまう……」 画像生成AIを利用するクリエイターにとって、最大の悩みはキャラクターの一貫性、いわゆる「キャラ固定」です。
かつては高度な専門知識が必要だったキャラ固定も、現在は正しいロジックを知れば誰でも高い精度で実現できます。
本記事では、ChatGPT(DALL-E 3)の「gen_id」を活用した最新の手法を中心に、MidjourneyやStable Diffusionなど各ツールのキャラ固定術を徹底解説。
この記事を読めば、あなたのキャラクターを自由自在に操り、一貫性のある連作やビジネスコンテンツを制作するスキルが身につきます。
🎨画像生成AIで「キャラ固定」が重要な理由

画像生成AIを活用したクリエイティブにおいて、同じキャラクターを継続して登場させる「キャラ固定」は、単なる技術的な課題ではなく、コンテンツの資産価値を左右する極めて重要な要素です。
なぜ物語やビジネスにおいて一貫性が必要なのか
キャラクターに一貫性がない場合、読者やユーザーは対象を「同一の存在」として認識できなくなり、ストーリーへの没入感が著しく損なわれます。ビジネスシーン、特にSNSマーケティングや企業のPR活動においては、発信のたびにキャラクターの顔立ちや特徴が変化してしまうと、ブランドの信頼性や親近感を醸成することが物理的に不可能になります。
一方で、キャラクターが完全に固定されていれば、特定の外見や個性を「アイコン」としてユーザーの記憶に定着させることが可能です。これにより、「このキャラと言えばあのブランド」という強力なブランド認知を確立し、長期的なファン層の獲得につなげることができます。
キャラクターのブレが信頼性と没入感を損なうリスク
キャラクターの外見が不安定なコンテンツは、読者に「違和感」というストレスを与え続けます。
- 没入感の低下: ストーリーの核心よりも「顔が変わったこと」に意識が向いてしまう。
- 専門性の欠如: AIを使いこなせていないという印象を与え、コンテンツ全体のクオリティを低く見積もられる。
- 商用利用の限界: 広告やグッズ展開において、同一性のないキャラクターは商品価値を持ち得ません。
一貫性を保つことは、「情報の解像度」を高め、コンテンツのプロフェッショナリズムを証明するための最低条件と言えます。
⚙️画像生成AIでキャラ固定を実現する3つの基本原理
AIがキャラクターを「同一人物」として認識し続けるためには、論理的な裏付けに基づいたアプローチが必要です。主に以下の3つの手法を組み合わせることで、再現性を飛躍的に高めることができます。
プロンプトによる厳密な外見定義
最も基本的かつ重要なのが、言語による詳細な定義です。AIに対して「若い女性」といった抽象的な指示を出すのではなく、代替不可能な特徴を具体的に指定します。
- 身体的特徴: 瞳の色、髪型(ポニーテール、ボブなど)、髪の色、特定の位置にあるほくろ。
- 固有の名前: 「ルナ(Luna)」などの名前をプロンプトに含め続けることで、AI内部の関連付けを強固にします。
固有の識別番号や参照画像によるデータの紐付け
AIが内部的に保持している特定の生成情報を「アンカー(錨)」として再利用する方法です。ツールによって名称は異なりますが、論理的な仕組みは共通しています。
- 生成シード値(Seed)や識別IDの活用: 過去の生成時に使用された乱数(シード値)や、AIが内部で割り当てた固有の識別コードを参照させることで、生成の「家系」や一貫性を維持します。
- イメージ参照(Image Reference / i2i): 既存のキャラクター画像をAIに読み込ませ、その視覚情報をベースに、ポーズや表情、背景などの「変数」のみを変更するように指示を出します。
LoRA等の追加学習によるモデル化
特定のキャラクターの特徴をAIに直接学習させ、専用の「型」を作成する最も高度な手法です。
- メリット: プロンプトだけでは表現しきれない複雑な装飾や顔立ちを100%再現可能。
- 利用シーン: 独自のIP(知的財産)を開発し、数千枚単位で高品質な画像を生成する必要がある場合に最適です。
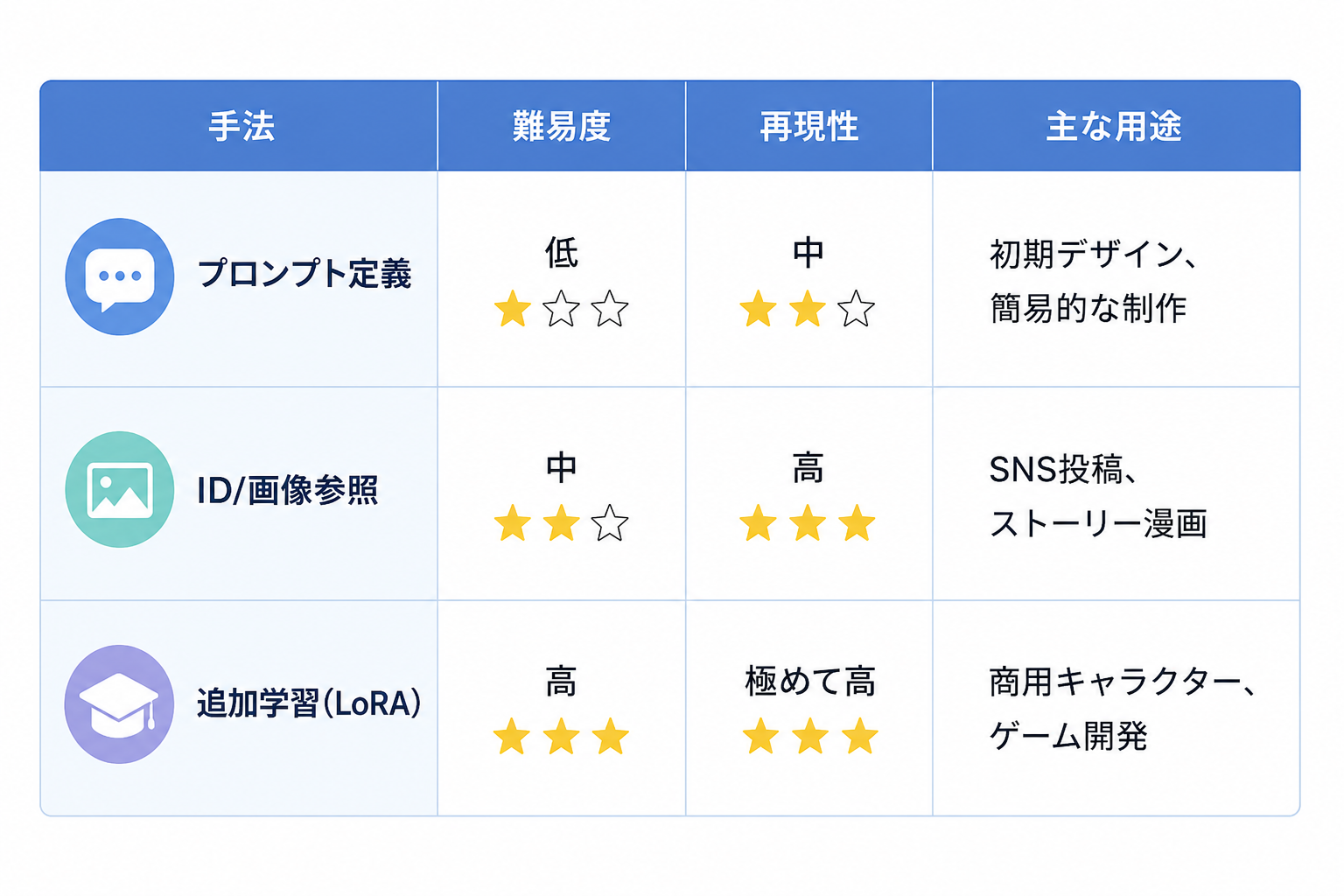
各手法の比較表
🤖 Yoomは画像生成AIの運用を自動化できます
画像生成AIでキャラクターを固定して生成する作業は楽しいものですが、生成した画像の保存やSNSへの投稿、チームへの共有といった後続の作業には意外と手間がかかります。そんな問題もYoomなら解決できます。
[Yoomとは]
Yoomには、画像生成とデータ管理をシームレスにつなぐテンプレートが用意されています。まずは以下の自動化を体験してみましょう。
- AIエージェントを活用して、WebサイトやSNS投稿用の画像生成を効率化したいマーケティング担当者の方
- チームからの画像生成依頼をフォームで受け付け、制作プロセスを自動化したいと考えている方
- 画像生成AIのプロンプト考案や商用利用の確認作業を自動化し、属人化を解消したい方
- フォーム送信を起点に画像生成から商用利用の判定、通知までが自動処理されるため、手作業の時間を短縮できます
- AIエージェント(AIワーカー) がプロンプト作成などを担うため、担当者のスキルに依存しない標準化された画像生成フローが構築できます
- はじめに、OpenAIとDiscordをYoomと連携します
- 次に、トリガーでフォームトリガーを選択し、画像生成のテーマや要望を受け付けるためのフォームを設定します
- 最後に、オペレーションでAIワーカーを設定し、フォームで受け取った内容をもとに画像生成用のプロンプトを作成し、商用利用の可否を判定した上で、生成された画像と判定結果をDiscordに通知するための指示を作成します
■このワークフローのカスタムポイント
- トリガーとして設定するフォームでは、画像生成の依頼で受け付けたい内容に合わせて、質問項目を任意で設定することが可能です
- AIワーカーに与える指示の内容は、生成したい画像のスタイルなどに合わせて変更できます。また、通知先のDiscordアカウントやチャンネルも任意で設定可能です
- OpenAI、DiscordのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- 詳しくはOpenAIの「API料金」ページをご確認ください。
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- Google スプレッドシートで管理している情報をもとに、AI画像の一括生成を行いたい方
- ブログ記事やSNS投稿用の画像を、手作業ではなく効率的に作成したいマーケティング担当者の方
- プロンプト入力や画像生成の繰り返し作業を自動化し、クリエイティブな業務に集中したい方
- Google スプレッドシートへの情報追加を起点にAI画像が自動で生成されるため、手作業でのプロンプト入力や生成作業にかかる時間を短縮できます。
- プロンプトの生成ルールを標準化できるため、担当者による品質のばらつきを防ぎ、AI画像の一括生成プロセスにおける属人化を解消します。
- はじめに、Google スプレッドシートとOpenAIをYoomと連携します。
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、Google スプレッドシートの情報をもとに画像生成プロンプトの最適化と安全性チェック、画像生成、記録を行うためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー設定で、監視対象としたい任意のスプレッドシートIDとシート名を指定してください。
- AIワーカーのオペレーション設定では、利用したい任意のAIモデルを選択し、実行したい内容に合わせた指示を設定してください。
- Google スプレッドシート、OpenAIのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- OpenAIのアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
✅【検証】ChatGPTでキャラクター固定を成功させる方法
ChatGPT(ChatGPT Images)は、対話を通じてキャラクターの解釈を深められるのが強みです。その精度を高める3ステップを検証しながら解説します。
ステップ1|マスタープロンプトで外見を定義する
まずは、キャラクターの設計図となる最初の1枚を生成します。曖昧さを排除するため、以下の要素を具体的に盛り込んだプロンプトを作成しました。
- 特徴の言語化: 「サファイアブルーの大きな瞳、ショートのボブヘア、赤いリボン、白いシャツを着たアニメ調の少女」
- スタイルの指定: 画風(フラットデザイン、3D、油絵調など)を固定します。 検証の結果、ここで「キャラクターの名前(例:Luna)」を決めてAIに覚えさせると、以降の指示が通りやすくなります。
【プロンプト】
今から物語のキャラクターを作成します。彼女の名前はルナ(Luna)です。今後、私がルナと呼ぶ際は、常に以下の視覚的特徴を完全に維持して画像を作ってください。
#ルナの身体的特徴
・髪型: 顎のラインで切り揃えられた、透き通るようなシルバーグレーのショートボブ。左側に大きくて真っ赤なサテン生地のリボンをつけている。
・輝くサファイアブルーの大きな瞳。
・顔立ち: 少し意志の強そうな眉、小さめの鼻。
#服装・スタイル
・服装: 糊のきいた真っ白なボタンダウンシャツ。一番上のボタンまで留めている。
・画風: 鮮やかでクリーンな日本のアニメスタイル。背景はシンプルな白一色。
#指示
まずは、ルナが正面を向いて少し微笑んでいるマスター画像(全身)を1枚生成してください。
【出力結果】

指示通りの特徴を捉えた「ルナ」が生成されました。背景を白一色に限定したことで、AIがキャラクターのデザインのみを純粋に認識できる状態になっています。
この画像が、以降のアクションや衣装変更を行う際の設計図となります。
ステップ2|gen_id(生成ID)を取得し、参照元に指定する

ChatGPTで生成された画像には、個別のgen_idが付与されます。
- 検証内容: チャット内で「今の画像のgen_idを教えて」と入力します。
- 固定のコツ: 次のプロンプトで「gen_id [ID番号] のキャラクターを維持して、別のポーズにして」と指示することで、AIが参照すべき核を認識します。
※gen_idは画像詳細から確認することも可能です。
【プロンプト】
#最優先事項
今後のすべての生成において、キャラクター「ルナ(Luna)」の外見(image_0.pngに描かれているシルバーグレーのボブヘア、赤いサテンリボン、瞳の色、白いシャツ、画風、アスペクト比)を完全に維持してください。
参照元のgen_id:個別のgen_idをここに
#指示
上記のgen_idのルナの外見と服装、画風を最優先でリファレンスとして使用し、ポーズだけを「片手を上げて挨拶している全身像」に変更した画像を1枚生成してください。顔立ちやリボンの位置は絶対に維持すること。
【出力結果】
取得したgen_idを指示に含めることで、キャラクターの造形を維持したままポーズのみを変更することに成功しました。
ポーズを変えても顔の印象が変わらず、同一人物としての整合性が高い結果です。
ステップ3|一貫性を維持したままシーンを展開する
最後に、固定したキャラクターに動きをつけます。
【プロンプト】
#最優先事項
今後のすべての生成において、キャラクター「ルナ(Luna)」の外見(image_0.pngに描かれているシルバーグレーのボブヘア、赤いサテンリボン、瞳の色、白いシャツ、画風、アスペクト比)を完全に維持してください。
参照元のgen_id: 個別のgen_idをここに
#指示
上記のgen_idのルナの外見と服装を最優先でリファレンスとして使用し、ポーズを「新緑が美しい広々とした公園を軽快に走っている」全身像に変更した画像を1枚生成してください。
#詳細設定
・走る動きにあわせて、シャツにシワが寄り、シルバーグレーの髪が少しなびいていること。
・赤いサテンリボンは左側に維持。
・背景(公園、木々、小道)は詳細に描くが、ルナに焦点をあわせる
・日本のアニメスタイル、自然な太陽光。顔立ちやリボンの位置は絶対に維持すること。
【出力結果】
gen_idと詳細プロンプトを組み合わせることで、キャラクターの造形を崩すことなく、新しいシーンへの展開に成功しました。
マスター画像の特徴を継承しつつ、髪のなびきやシャツのシワなど、ディテールを保ちながら別人になる現象を抑えられ、同一人物としての整合性が高い結果となりました。
結果のまとめ
ChatGPTを活用したキャラ固定は、適切な手順を踏むことで高い再現性を発揮することが分かりました。
成功のポイントは、詳細なマスタープロンプトによる外見の定義と、生成された「gen_id」を参照元として活用することにあります。gen_idによるキャラクター固定はユーザー間で広まった実践的なテクニックですが、検証の結果一貫性の向上に有効であることが確認できました。
これにより、ポーズの変更や複雑な背景への展開を行っても、固有の特徴を維持したまま、物語のシーンを描き分けることが可能になりました。
完全な一致には数回の微調整が必要なケースもありますが、対話を通じて即座に修正指示を出せる点は、ChatGPTならではの強みです。
✅Gemini(Nano-Banana)でキャラクターを固定する方法【検証】
GoogleのGemini(Nano Banana)は、高度な言語理解力と画像の細部を読み取るマルチモーダル能力が特徴です。キャラ固定を実現するための、論理的かつ視覚的な2ステップ検証を解説します。
ステップ1|プロンプトを3層構造にして情報の混同を防ぐ
Geminiでキャラクターを一貫させる鍵は、指示を論理的に構造化することにあります。設定を「基本設定」「外見の詳細」「シーン」の3つの階層に分けて記述する3層プロンプト方式を用いることで、AIが変えてはいけない核(キャラクターのアイデンティティ)を理解できるようになります。
【プロンプト】
#Layer 1:基本設定
・名前:ルナ(Luna)。10代後半のアニメスタイルの少女。
・特徴:シルバーグレーのショートボブ。左側に大きな赤いサテンリボン。サファイアブルーの瞳。
#Layer 2:服装とスタイル
・服装:白いボタンダウンシャツ(全留め)、黒いスラックス。
・画風:クリーンな線画、鮮やかな色使いの日本のアニメ調。
#Layer 3:アクションと背景
・状況:白い背景の前で、正面を向いて静止している全身ポーズ。
上記の3層の設定を厳守し、マスター画像となるルナを1枚生成してください。
【出力結果】
各階層の指示が統合された「ルナ」が生成されました。
情報を構造化したことで、シルバーグレーの髪、赤いリボン、瞳の色、服装のディテールが混同されることなく描写されています。
ステップ2|表情シートの生成
次に、1枚の画像だけでなく、複数の角度や表情を同時に学習させ、それをリファレンス(参照)として機能させるステップです。
【プロンプト】
#最優先
添付画像に描かれているキャラクター「ルナ(Luna)」の外見設定を完全に継承してください。
#身体的特徴
・シルバーグレーのショートボブ。
・向かって左側に大きな赤いサテンリボンを装着(リボンの結び方や素材感も維持)。
・サファイアブルーの瞳。意志の強そうな眉。
#服装と画風
・白いボタンダウンシャツ(全留め)、黒いスラックス。
・清潔感のある日本のアニメスタイル。
#指示
・表情シート(キャラクターシート)の生成
・添付画像のルナをベースに、以下の表情と角度を1枚の画像にまとめた表情シートを生成してください。
#収録する表情(計6パターン)
・正面(添付画像と同じ微笑)
・正面(怒り:眉をひそめる)
・正面(泣き:涙を浮かべる)
・正面(驚き:目を丸くする)
・横顔(向かって右向き:真剣な表情。赤いリボンが見えること)
・後ろ姿(背中合わせ:シルバーボブの形と赤いリボンの裏側が見える)
#詳細設定
・6パターンを整然としたグリッド状に配置。背景は純白。
・すべて同じ画風、同じアスペクト比で出力すること。
【出力結果】
計7つの表情シートが生成されました。
一部、「怒り」と「驚き」の解釈が重複する挙動が見られたものの、ルナの核となる特徴は維持されています。
描画が難しい後ろ姿や横顔においても一貫性が保たれており、キャラ固定の資料として実用的な結果となりました。
結果のまとめ
Geminiでの検証は、論理的なプロンプト構成と高い画像参照能力が際立つ結果となりました。
3層プロンプト方式情報の構造化によって、変えてはいけない核をAIが正確に認識し、初回の生成から理想のキャラクターを出力できることが実証されました。
続く表情シートの検証では、バリエーションが増える挙動がありましたが、一度生成した画像をリファレンスとして再入力する手法こそが、Geminiで安定したキャラクター制作を実現する最短ルートといえます。
🎉その他のツール(Midjourney・Stable Diffusion)でのキャラ固定方法

🔵Midjourneyでキャラを自在に操る「リファレンス機能」活用術
Midjourneyはプロ向けの高い画質を誇る一方で、キャラ固定が難しいとされてきました。しかし、現在は「Character Reference(--cref)」や、V7から導入された「Omni Reference(--oref)」により、驚くほど高度な一貫性を保持できます。
リファレンス機能によるキャラクター参照の基本
参照したいキャラクターの画像URLを取得し、プロンプトの末尾にコマンドを付け加えることで、AIはその画像の顔立ちや髪型、体格などを参照しながら、新しいシーンでもキャラクターの一貫性を保ちやすくなります。
最新のV7では、従来のキャラクター参照(--cref)をより進化させた--orefが推奨されており、キャラクターの特徴だけでなく、スタイルや構成までをより包括的に引き継ぐことが可能になりました。
視覚的な情報を直接反映させるため、言葉では表現しきれない絶妙なニュアンスまで固定できるのが最大の特徴です。
キャラクターウェイト(--cw)で固定の強さを調整する
Midjourneyの真骨頂は、--cw(Character Weight)というパラメータにあります。この値は0から100まで指定でき、固定する範囲を細かくコントロールできます。
- --cw 0: 「顔」のみを固定します。服装や髪型を自由に変えたいファッションショーのようなシーンに最適です。
- --cw 100: 顔、髪型、服装のすべてを固定します。キャラクターのトレードマークが完全に決まっている場合に有効です。
実践的な使い分けのポイント
物語の進行に合わせて衣装を着替えさせたい場合は、--cw 0 を活用しましょう。逆に、特定の制服を着たキャラクターを様々な角度から描きたい場合は --cw 100 でガチガチに固めるのが、プロが現場で行っている使い分けのテクニックです。また、V7以降は--orefを使用することで、背景やライティングの一貫性も同時に保ちやすくなっているため、シーン全体の統一感を重視する制作にも適しています。
🔵【上級編】Stable DiffusionやFluxでLoRAを自作・活用する方法
プロレベルの制作現場で最も信頼されているのが、Stable DiffusionやFluxといったローカル環境・自由度の高いモデルで「LoRA(Low-Rank Adaptation)」を使用する手法です。
LoRA(追加学習)が最強のキャラ固定ツールである理由
LoRAとは、特定のキャラクターや絵柄の特徴を抽出して、ベースとなるAIモデルに「後付け」で学習させる技術です。 プロンプトによる指示には常に不確実性が伴いますが、LoRAを使用すれば、プロンプトだけに頼る方法よりも高い再現性で同一キャラクターを生成しやすくなります。複雑な装飾品や独自の髪型も正確に再現できる点が、他の手法との決定的な違いです。
質の高いLoRAを作成するための学習データ準備
LoRAの精度を左右するのは、学習に使用する「教師画像」の質です。 同一キャラクターの画像を15枚〜30枚程度用意し、正面・横・後ろ姿だけでなく、アップ、バストアップ、全身と画角にバリエーションを持たせることが重要です。背景がシンプルな画像を選ぶことで、AIが背景とキャラクターを混同するリスクを最小限に抑えることができます。
🔄生成後に顔を修正する「Faceswap(顔入れ替え)」という最終解決策

「体やポーズは完璧なのに、顔だけが別人に……」という場合に、無理に一発生成で解決しようとする必要はありません。外部ツールを用いた「Faceswap(顔入れ替え)」が、実務における最も現実的な最終手段となります。
ReActorやInsightFaceを用いた顔の強制上書き
Stable Diffusionのエクステンションである「ReActor」や、InsightFace系の顔解析・顔入れ替え技術を活用したツールなどを使えば、生成された画像の顔部分だけを、あらかじめ登録しておいた「正解の顔」に差し替えることができます。プロンプトの微調整に何時間も費やすよりも、この手法で強制的に修正するほうが、制作時間を劇的に短縮できる場合があります。
違和感をなくすためのレタッチのコツ
顔を入れ替えた直後は、肌の色味や解像度にわずかな違和感が生じることがあります。 その際は、同じAI環境で「i2i(Image to Image)」を使い、低い強度(Denoising Strength)で全体を再描画するのがプロの技です。
これにより、入れ替えた顔と体、そして周囲のライティングが馴染み、合成感のない完璧な1枚へと仕上がります。
🛠️全ツール共通!画像生成AIでキャラ固定を成功させる「3つのコツ」と「鉄則」
どのAIツールを使う場合でも、共通して意識すべき「成功の鉄則」があります。これを知っているだけで、キャラ固定の成功率は格段に向上します。
1. 特徴的な「固有名詞」と「身体的特徴」をセットにする
キャラクターに固有の名前をつけ、プロンプト内で強調して記述しましょう。さらに「三つ編みの赤いリボン」や「星型のピアス」といった、AIが認識しやすい具体的なシンボルを付与することで、AI内部での認識が強化され、キャラクターのアイデンティティが定着しやすくなります。
2. 不要な変化を抑える指示を加え、小物を「トリガー」にする
「何を描くか」だけでなく、「何を変えないか(髪型や年齢感など)」を明確に指示します。また、特定の剣やバッグなどの「小物」を常に持たせることで、AIにとって「この小物が写っている=このキャラを描くモード」という強力な視覚的トリガーとなり、顔の安定感も副次的に向上します。
3. プロンプトの「黄金律」と「資産化」を徹底する
AIは先頭の単語を優先するため、「キャラ定義 > ポーズ > 服装 > 背景」の順で記述するのが一貫性を崩さないための黄金律です。また、成功したプロンプトやIDは必ず保存し、独自の「キャラ固定レシピ」を積み上げていくことが、再現性を高めるための最大の鉄則です。
🚩まとめ:制作スタイルに合わせた最適なキャラ固定ツールを選ぼう
画像生成AIでのキャラ固定は、単一の正解があるわけではなく、目的や使用ツールに合わせた最適なアプローチを選ぶことが重要です。
手軽さを重視するならChatGPTのID参照、画質と制御の両立ならMidjourneyの--cref、そして最高峰の精度を求めるならStable DiffusionでのLoRA自作と、それぞれの強みがあります。まずは自分の制作スタイルに合った手法を一つ選び、徹底的に使いこなしてみてください。
キャラクターに一貫性が宿るとき、あなたの作品は単なる「AIイラスト」から、人々の心に残り続ける「物語」へと進化するはずです。
⚙️Yoomでできること
画像生成AIで理想のキャラクターを固定できたら、次はそれを実務に組み込んでいきましょう。Yoomを使えば、AIとのやり取りや生成された画像の管理を自動化し、クリエイティブな時間をさらに増やすことができます。
例えば、Google スプレッドシートに行を追加するだけで、あらかじめ設定した「固定キャラクターのプロンプト」を自動でChatGPTやLeonardo AIに送り、生成された画像をドライブに保存するフローが作成できます。これにより、手動で何度もプロンプトをコピペする手間が完全になくなります。
また、画像生成だけでなく、生成された画像をAIワーカーが解析して、SNS用の投稿文を自律的に作成し、予約投稿まで行うといった高度な自動化も可能です。まずは、以下の便利なテンプレートから活用を始めてみてください。
- ChatGPTで生成した文章の管理やデータベースへの格納を自動化したいと考えている方
- コンテンツ制作やデータ整理の過程で、AIとデータベース間の手作業を減らしたい方
- 日々の定型業務を効率化し、より創造的な業務に時間を充てたいと考えている方
- データベース上の操作を起点にChatGPTでの文章生成から格納までが自動化され、手作業に費やしていた時間を短縮できます。
- 手作業によるコピー&ペーストが減るため、転記ミスや格納漏れといったヒューマンエラーの防止に繋がります。
- はじめに、ChatGPTをYoomと連携します。
- 次に、トリガーでYoomデータベースを選択し、「レコードを選択して起動」するアクションを設定します。
- 次に、オペレーションでChatGPTを選択し、「テキストを生成」アクションを設定します。
- 最後に、オペレーションで再度Yoomデータベースを選択し、「レコードを更新する」アクションで生成した文章を指定のレコードに格納するよう設定します。
■このワークフローのカスタムポイント
- トリガーとして設定するYoomデータベースは、任意のものに変更して設定してください。
- ChatGPTに文章を生成させる際のプロンプト(指示内容)は、業務に合わせて自由に設定することが可能です。
- 生成した文章を格納するデータベースの項目(カラム)も、任意で指定することができます。
- ChatGPTとYoomを連携してください。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- 詳しくはOpenAIの「API料金」ページをご確認ください。
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- Perplexityを活用した画像生成のプロセスを自動化したいコンテンツ制作者の方
- Google スプレッドシートで管理する情報をもとに、効率的に画像を準備したいチームリーダーの方
- 複数のAIツールを連携させ、クリエイティブ制作の定型業務を効率化したいと考えている方
- スプレッドシートの更新だけで画像が自動生成されるため、プロンプトの考案やツールの操作にかかる時間を短縮できます。
- Perplexityによるプロンプト生成を挟むことで、生成される画像の品質が安定し、クリエイティブ業務の属人化を防ぎます。
- はじめに、Google スプレッドシート、OpenAI、PerplexityをYoomと連携します。
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が更新されたら」というアクションを設定します。
- 次に、オペレーションでPerplexityの「情報を検索(AIが情報を要約)」アクションを設定し、 Google スプレッドシートの情報から画像生成用のプロンプトを作成します。
- 続いて、オペレーションでOpenAIの「テキストから画像を生成する」アクションを設定し、作成されたプロンプトをもとに画像を生成します。
- 最後に、オペレーションでYoomの「メールを送る」アクションを設定し、生成された画像を任意の宛先に送付します。
- Google スプレッドシートのトリガー設定では、対象としたい任意のスプレッドシートIDとシートのタブ名を設定してください。
- Perplexityの設定では、生成するプロンプトの質を調整するため、任意のモデル名、システムプロンプト、ユーザープロンプトを設定してください。
- OpenAIの「テキストから画像を生成する」アクションでは、生成枚数や画像サイズを任意の価に設定してください。
- メール機能の設定では、宛先や件名に任意の値を設定し、本文には事前のアクションで取得した値や任意のテキストを活用して設定してください。
- Google スプレッドシート、Perplexity、OpenAIのそれぞれとYoomを連携してください。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
プログラミング知識なしで手軽に構築できます。









