








・
Claude Sonnet 4.5とGPT-5.2を業務で使い分ける方法を実践で比較

AI技術は短期間で急速に進化しており、なかでもAnthropicのClaude Sonnet 4.5とOpenAIのGPT-5.2は、ビジネスや開発の現場で注目を集めています。
どちらも高性能なAIモデルですが、文章表現のニュアンスや論理的な推論プロセスなど、実務で使ったときの「得意・不得意」には違いがあります。
本記事では、ビジネス謝罪メールの作成と複雑な条件分岐を含むロジックパズルという2つの具体的な検証を通して、両モデルの特徴を比較します。その結果をもとに、どのような業務にどちらのAIが向いているのかを分かりやすく整理します。
✍️前提情報

以下に、それぞれのモデルについての情報をまとめました。ぜひ、参考にしてみてくださいね!
※本記事に掲載している情報は、2026年2月時点のリサーチおよび実機検証に基づいています。AIモデルのアップデートは早いため、導入の際は各公式サイトの新しい情報も併せてご確認ください。
本記事の想定読者
- Claude Sonnet 4.5とGPT-5.2の具体的な違いを知りたい方
- プログラミングや文章作成などの実務でどちらを使うべきか迷っている方
- 最新AIを活用して業務の生産性を向上させたいビジネスパーソンやエンジニア
Claude Sonnet 4.5とは?
〈概要・説明〉
Claude Sonnet 4.5は、Anthropic社が開発した実用性とコストパフォーマンスを兼ね備えた主力モデルです。特筆すべきは、エンジニアから絶大な支持を得ているコーディング能力と、100万トークン(ベータ版(特定のプラットフォーム経由など)としての提供)という驚異的なコンテキストウィンドウです。
これにより、リポジトリ全体を一度に読み込ませて修正を依頼するといった、大規模なタスクを難なくこなします。また、人間味のある自然な日本語表現も大きな魅力の一つです。
〈料金プラン〉
- Claude Free:
無料(利用制限あり) - Claude Pro:
月額20ドル(無料版の5倍のメッセージ上限、新機能への優先アクセス) - Claude Team:
1ユーザーあたり月額25ドル(最小5ユーザーから) - API:
従量課金制(従来のSonnetクラスの低価格帯を維持)
〈おすすめの人〉
- 複雑なシステムの開発やリファクタリングを行うエンジニア
- 大量の資料や長大なドキュメントを一括で解析したいリサーチャー
- 自然で温かみのあるビジネス文書やクリエイティブな文章を作成したい方
GPT-5.2とは?
〈概要・説明〉
GPT-5.2は、OpenAI社が提供するGPT-5のアップデート版です。最大の特徴は、推論に特化した「Thinkingモード」と、スピードを重視した「Instantモード」を切り替えられる柔軟性にあります。(無料版での利用には制限があります)
論理的な整合性が極めて高く、複雑なパズルや数学的推論、高度な戦略構築において無類の強さを発揮します。また、画像生成やWeb検索、データ分析といったエコシステムとの連携も強力です。
〈料金プラン〉
- ChatGPT Free:
無料(利用制限あり)
- ChatGPT Go:
月額8ドル(GPT-5.2 Instantへの拡張アクセスなど利用可能。利用中に広告が表示される場合がある)
- ChatGPT Plus:
月額20ドル(新しいモデルの優先利用、DALL-Eなどの付帯機能など)
- ChatGPT Pro:
月額200ドル(GPT-5.2 Thinking/ProによるProレベルの推論、Sora動画生成への拡張アクセスなど)
- ChatGPT Team/Enterprise:
法人向けプラン(管理機能や高度なセキュリティ)
- API:
従量課金制(モードやモデルサイズにより変動)
〈おすすめの人〉
- 多角的な視点での壁打ちや、高度な論理的推論を求めるビジネスリーダー
- 数学、物理、データ分析など、正確な数値計算やロジックを必要とする方
- 一つのツールで画像生成から検索まで完結させたい効率重視の方
📣AIモデルの使い分けも、Yoomなら自動化できます
Yoomを利用すれば、Claude Sonnet 4.5とGPT-5.2を業務フローの中に組み込み、用途に応じて自動的に使い分けることが可能です。
例えば、「プログラミング関連の依頼はClaudeに、論理的なデータ分析や戦略立案はGPTに」といった複雑な条件分岐も、ノーコードで簡単に実現できます。
AIのポテンシャルを最大限に引き出し、日々のルーティンワークを自動化したい方は、ぜひ以下のテンプレートをチェックしてみてください。
■概要
GitLabでのイシュー管理において、新しいイシューが作成されるたびに内容を確認し、要点を把握する作業に手間を感じていませんか。
特に多くのイシューが起票されるプロジェクトでは、内容のスムーズな理解と適切な担当者への割り振りが遅れがちになることもあります。
このワークフローを活用すれば、GitLabにイシューが作成されると自動でAnthropic(Claude)が内容を解析し、結果をイシューに追記するため、こうした課題を円滑に解消し、Anthropic(Claude)とGitLabを連携させた効率的なプロジェクト管理を実現できます。
■このテンプレートをおすすめする方
- GitLabでのイシュー確認やトリアージ作業の効率化を図りたい開発チームのリーダーの方
- 手作業でのイシュー管理に限界を感じ、ClaudeとGitLabを連携させた自動化を検討している方
- AIを活用してプロジェクトの課題管理を高度化し、スムーズな対応を実現したいマネージャーの方
■このテンプレートを使うメリット
- GitLabのイシュー作成をトリガーにAnthropic(Claude)が自動で内容を解析するため、担当者が内容を読み解き要約する時間を短縮できます。
- AIが一貫した基準でイシューを解析することで、担当者ごとの解釈のばらつきを防ぎ、対応の効率化や業務の標準化に繋がります。
■フローボットの流れ
- はじめに、GitLabとAnthropic(Claude)をYoomと連携します。
- 次に、トリガーでGitLabを選択し、「イシューが作成されたら」というアクションでフローが起動するように設定します。
- オペレーションでは、まず分岐機能を設定し、作成されたイシューの情報をもとに後続の処理を分岐させることが可能です。
- 次に、Anthropic(Claude)の「テキストを生成」アクションを設定し、トリガーで取得したイシューの内容を解析させます。
- 最後に、GitLabの「イシューを更新」アクションを設定し、Anthropic(Claude)が生成したテキストをイシューにコメントとして追加します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- GitLabのトリガー設定では、自動化の対象としたいプロジェクトIDを任意で設定してください。
- 分岐機能では、イシューのラベルやタイトルに含まれるキーワードなど、前段で取得した情報を利用して処理を分岐させる条件を自由に設定できます。
- Anthropic(Claude)にテキスト生成を依頼する際のプロンプトは自由にカスタマイズでき、「このイシューを日本語で要約して」など、イシューの本文を変数として活用しながら具体的な指示が可能です。
- GitLabのイシューを更新するアクションでは、Anthropic(Claude)の解析結果をコメントとして追記するだけでなく、特定のラベルを付与するなど、更新する項目や内容を任意で設定できます。
■ 注意事項
- GitLab、Anthropic(Claude)のそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 分岐はミニプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- ミニプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。
■概要お客様からのお問い合わせなど、日々受信する大量のメールの内容を一つひとつ確認し、その感情を分析するのは手間がかかる作業ではないでしょうか。また、分析結果をMicrosoft Excelなどに手作業でまとめる場合、入力ミスや転記漏れのリスクも伴います。このワークフローを活用すれば、Gmailで受信したメールの内容をChatGPTが自動で感情分析し、その結果をMicrosoft Excelに自動で追加することが可能です。顧客からのフィードバックの可視化や対応の優先順位付けを効率化します。
■このテンプレートをおすすめする方- Gmailで受信する顧客からの問い合わせメールの管理を効率化したい方
- ChatGPTを活用してメールの内容を分析し、業務に活かしたいと考えている方
- Microsoft Excelへのデータ手入力を自動化し、作業工数を削減したい方
■このテンプレートを使うメリット- メールの内容をChatGPTが自動で感情分析しExcelへ追加するため、これまで手作業で行っていた分析や入力作業の時間を短縮できます。
- 手作業によるデータの転記が不要になるため、入力間違いや転記漏れといったヒューマンエラーの防止に繋がります。
■フローボットの流れ- はじめに、Gmail、ChatGPT、Microsoft ExcelをYoomと連携します。
- 次に、トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します。
- 続けて、オペレーションでChatGPTを選択し、「テキストを生成」アクションで受信メールの本文を感情分析するように設定します。
- 最後に、オペレーションでMicrosoft Excelを選択し、「レコードを追加する」アクションで分析結果を指定のファイルに追加するように設定します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Gmailのトリガー設定では、自動化の対象としたいメールを特定するためのキーワードを任意で設定してください。
- ChatGPTのオペレーションでは、感情分析の精度などを調整するために、プロンプトや使用するモデルを任意で設定できます。
- Microsoft Excelへの追加設定では、対象となるアイテムIDやシート名を指定し、前段のGmailやChatGPTで取得した情報をどのセルに追加するかを自由に設定可能です。
■注意事項- Gmail、ChatGPT、Microsoft ExcelとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- Microsoft Excelのデータベースを操作するオペレーションの設定に関しては「【Excel】データベースを操作するオペレーションの設定に関して」をご参照ください。
■概要
GitLabでのイシュー管理において、新しいイシューが作成されるたびに内容を確認し、要点を把握する作業に手間を感じていませんか。
特に多くのイシューが起票されるプロジェクトでは、内容のスムーズな理解と適切な担当者への割り振りが遅れがちになることもあります。
このワークフローを活用すれば、GitLabにイシューが作成されると自動でAnthropic(Claude)が内容を解析し、結果をイシューに追記するため、こうした課題を円滑に解消し、Anthropic(Claude)とGitLabを連携させた効率的なプロジェクト管理を実現できます。
■このテンプレートをおすすめする方
- GitLabでのイシュー確認やトリアージ作業の効率化を図りたい開発チームのリーダーの方
- 手作業でのイシュー管理に限界を感じ、ClaudeとGitLabを連携させた自動化を検討している方
- AIを活用してプロジェクトの課題管理を高度化し、スムーズな対応を実現したいマネージャーの方
■このテンプレートを使うメリット
- GitLabのイシュー作成をトリガーにAnthropic(Claude)が自動で内容を解析するため、担当者が内容を読み解き要約する時間を短縮できます。
- AIが一貫した基準でイシューを解析することで、担当者ごとの解釈のばらつきを防ぎ、対応の効率化や業務の標準化に繋がります。
■フローボットの流れ
- はじめに、GitLabとAnthropic(Claude)をYoomと連携します。
- 次に、トリガーでGitLabを選択し、「イシューが作成されたら」というアクションでフローが起動するように設定します。
- オペレーションでは、まず分岐機能を設定し、作成されたイシューの情報をもとに後続の処理を分岐させることが可能です。
- 次に、Anthropic(Claude)の「テキストを生成」アクションを設定し、トリガーで取得したイシューの内容を解析させます。
- 最後に、GitLabの「イシューを更新」アクションを設定し、Anthropic(Claude)が生成したテキストをイシューにコメントとして追加します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- GitLabのトリガー設定では、自動化の対象としたいプロジェクトIDを任意で設定してください。
- 分岐機能では、イシューのラベルやタイトルに含まれるキーワードなど、前段で取得した情報を利用して処理を分岐させる条件を自由に設定できます。
- Anthropic(Claude)にテキスト生成を依頼する際のプロンプトは自由にカスタマイズでき、「このイシューを日本語で要約して」など、イシューの本文を変数として活用しながら具体的な指示が可能です。
- GitLabのイシューを更新するアクションでは、Anthropic(Claude)の解析結果をコメントとして追記するだけでなく、特定のラベルを付与するなど、更新する項目や内容を任意で設定できます。
■ 注意事項
- GitLab、Anthropic(Claude)のそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 分岐はミニプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- ミニプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。
- Gmailで受信する顧客からの問い合わせメールの管理を効率化したい方
- ChatGPTを活用してメールの内容を分析し、業務に活かしたいと考えている方
- Microsoft Excelへのデータ手入力を自動化し、作業工数を削減したい方
- メールの内容をChatGPTが自動で感情分析しExcelへ追加するため、これまで手作業で行っていた分析や入力作業の時間を短縮できます。
- 手作業によるデータの転記が不要になるため、入力間違いや転記漏れといったヒューマンエラーの防止に繋がります。
- はじめに、Gmail、ChatGPT、Microsoft ExcelをYoomと連携します。
- 次に、トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します。
- 続けて、オペレーションでChatGPTを選択し、「テキストを生成」アクションで受信メールの本文を感情分析するように設定します。
- 最後に、オペレーションでMicrosoft Excelを選択し、「レコードを追加する」アクションで分析結果を指定のファイルに追加するように設定します。
■このワークフローのカスタムポイント
- Gmailのトリガー設定では、自動化の対象としたいメールを特定するためのキーワードを任意で設定してください。
- ChatGPTのオペレーションでは、感情分析の精度などを調整するために、プロンプトや使用するモデルを任意で設定できます。
- Microsoft Excelへの追加設定では、対象となるアイテムIDやシート名を指定し、前段のGmailやChatGPTで取得した情報をどのセルに追加するかを自由に設定可能です。
- Gmail、ChatGPT、Microsoft ExcelとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- Microsoft Excelのデータベースを操作するオペレーションの設定に関しては「【Excel】データベースを操作するオペレーションの設定に関して」をご参照ください。
🤔Claude Sonnet 4.5とGPT-5.2を試してみた!
どちらのモデルが実際の業務で使い勝手が良いのか、誰でも試せる2つの比較検証を行ってみました。
検証内容
今回は、以下のような検証をしてみました!
検証①:ビジネス謝罪メールの作成
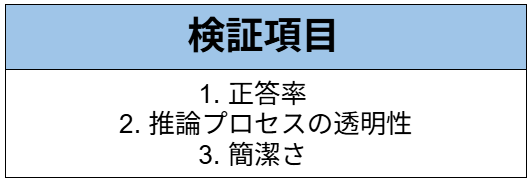
【検証項目】
以下の項目で、検証していきます!

【検証目的】
各AIモデルにおける「相反するトーンの両立」と「文脈に応じたユーモアの生成能力」を検証します。
ビジネス上の深刻な場面(謝罪)において、誠実さを損なわずに、指定された「くすっと笑えるユーモア」を適切に織り交ぜた高度なライティングが可能か、その実用性を評価していきます。
検証②:複雑な条件分岐のロジックパズル
【検証項目】
以下の項目で、検証していきます!
【検証目的】
複数の条件が複雑に絡み合う論理パズルを用い、AIのステップバイステップな推論(Chain-of-Thought)能力を検証する。 「真実を語る者が1名のみ」という制約条件下で、各発言の矛盾を網羅的に洗い出し、論理破綻なく正解を導き出せるかを評価する。
使用モデル
Claude Sonnet 4.5,GPT-5.2
🔍検証①ひねりのあるビジネス謝罪メールの作成(誠実さとユーモアの両立)
ここからは、実際に検証した内容とその手順を解説します。
まずは実際の検証手順のあとに、それぞれの検証項目について紹介していきます!
検証方法
本検証では、Claude Sonnet 4.5とGPT-5.2を使用し、ビジネス謝罪メールの作成を行います。
プロンプト:
プロジェクトの納期が1日遅れることをクライアントに謝罪するメールを作成してください。ただし、相手を不快にさせない程度の、くすっと笑えるようなユーモアを1つ交えて、非常に誠実かつ親しみやすいトーンで書いてください。
想定シーン
長年付き合いのあるクライアントに対し、不測の事態で納期の1日遅延が発生したが、誠意を見せつつも過度な緊張感を和らげて信頼を維持したい場面。
〈Claude Sonnet 4.5〉
まずは、Claude Sonnet 4.5から試してみます。
検証手順
ログイン後、こちらの画面が表示されるので、プロンプトを入力したら送信します。
1分以内で完了しました!
結果は以下のものとなりました。

リアルな使用感
ビジネスの礼節を堅持しながら、指定された「くすっと笑えるユーモア」を自然な形で文脈に溶け込ませる高い構成力を見せました。
特筆すべきは、言語の機微を捉えた表現の巧みさです。単にジョークを添えるのではなく、「急がば回れ」という慣用句を「急いだら転んだ」と大胆に言い換えることで、状況の深刻さを否定せずに自虐的なユーモアへと昇華させています。このアプローチは、謝罪の誠実さを損なうどころか、かえって人間味を感じさせ、クライアントの心理的な硬直を解く効果が期待できます。出力されたメールは、件名から署名欄のプレースホルダーまで過不足なく整理されており、そのまま実務のテンプレートとして活用できるレベルの完成度です。
単なるテキスト生成に留まらず、相手との関係性を維持・向上させるための「感情的なインテリジェンス(EQ)」を感じさせる内容であり、「事務的な報告を、信頼構築のための温かみのあるコミュニケーションへ変換できる」実用的なツールであると確信しました。
〈GPT-5.2〉
次に、GPT-5.2を試してみます。
検証手順
ログイン後、こちらの画面が表示されるので、プロンプトを入力したら送信します。
1分以内で完了しました!(Claude Sonnet 4.5より若干、早く結果が出力されました)
結果は以下のものとなりました。

リアルな使用感
謝罪というデリケートな文脈において、「誠実な謝罪」と「場を和らげるユーモア」という相反するニュアンスを高度に制御する能力を示しました。
特筆すべきは、「完成度が素晴らしすぎて手直ししている」というポジティブな冗談を添えて、相手との距離感に応じた絶妙な匙加減がなされています。いずれも、納期遅延というマイナスの報告を単なる事務連絡で終わらせず、人間味を感じさせるポジティブなコミュニケーションへと転換させる工夫が見て取れます。
単なる定型文の生成に留まらず、文末に「構成の意図」を解説する配慮までなされており、実務における下書き作成ツールとして即戦力で活用できる完成度です。クリエイティブな表現を維持しつつも、ビジネスの礼節を逸脱しないこのバランス感覚は、「心理的な摩擦を軽減し、信頼関係を維持・強化するライティング・パートナー」として有用であると確信しました。
🔍検証②複雑な条件分岐を含むロジックパズルの解答
ここからは、実際に検証した内容とその手順を解説します。
まずは実際の検証手順のあとに、それぞれの検証項目について紹介していきます!
検証方法
本検証では、Claude Sonnet 4.5とGPT-5.2を使用し、複雑な条件分岐のロジックパズルの回答結果を比較していきます。
プロンプト:
5人の容疑者がいます。Aは『Bが犯人だ』と言い、Bは『Dが犯人だ』と言い、Cは『私は犯人ではない』と言い、Dは『Bは嘘をついている』と言い、Eは『Aは犯人ではない』と言っています。犯人が1人で、かつ1人だけが嘘を言っている場合、犯人は誰ですか?ステップバイステップで考えてください。
想定シーン
複数の証言が食い違う複雑なトラブルの根本原因を特定する際、矛盾する情報の中から論理的整合性のみを頼りに唯一の真実を導き出す、高度な分析思考が必要な場面。
〈Claude Sonnet 4.5〉
まずは、Claude Sonnet 4.5から試してみます。
検証手順
ログイン後、表示される画面で、プロンプトを入力したら送信します。
2分で完了しました!
結果は以下のものとなりました。(一部、抜粋しています)


リアルな使用感
複数の条件が複雑に絡み合う論理パズルにおいて、一切の妥協がない緻密な推論プロセスと正確な結論導出能力を見せました。
特筆すべきは、推論の透明性と構造化の美しさです。単に「犯人はBです」と回答するだけでなく、与えられた情報を整理した上で、犯人がAだった場合、Bだった場合…と全ケースを網羅的に検証(Case Study)しており、読み手が論理の正当性を一目で確信できる構成になっています。特に「1人だけが嘘をついている(他の4人は真実)」という制約条件を全ての変数に適用し、矛盾が発生する箇所を記号(√やX)を用いて視覚的に整理する手法は、人間による論理チェックのプロセスを忠実に再現しています。
単なる正解の提示に留まらず、なぜその結論に至ったのかを「思考の足跡」として完璧に可視化できている点は実務的にも価値が高く、「複雑な不整合を含む情報群から、論理的な矛盾を排除して真実を抽出する」意思決定支援ツールとして信頼できる精度であると確信しました。
〈GPT-5.2〉
次に、GPT-5.2を試してみます。
検証手順
ログイン後、表示される画面で、プロンプトを入力したら送信します。
1分で完了しました!(Claude Sonnet 4.5より早く結果が出力されました)
結果は以下のものとなりました。

リアルな使用感
複数の証言が対立する高度な論理パズルにおいて、思考の各ステップを詳細に言語化し、結論を導き出すプロセスを明確に提示しました。
特筆すべきは、推論の「構造化」と「徹底した仮説検証」の姿勢です。回答では、まず情報をステップごとに整理し、各容疑者が「嘘をついている場合」の帰結を一つずつ論理的にシミュレーションしています。特に、複雑な条件分岐を単なる脳内処理で終わらせず、箇条書きを用いて可視化することで、読み手がAIの思考ロジックを追体験できるほどの透明性を実現しています。結論に至るまでの「論理の絞り込み」の精度は高く、人間が陥りがちな直感的なミスを排除した、AIならではの堅実な分析力が発揮されています。
単に『Aが犯人』を導き出すだけでなく、その証明プロセス自体が論理的思考の優れたサンプルとなっており、「不透明な状況下で、各情報の整合性を検証し、事実を論理的に確定させる」強力な意思決定エンジンとしてのポテンシャルを確信しました。
🖊️検証結果
検証1、検証2を通じて得られた結果は以下の通りです。
検証①
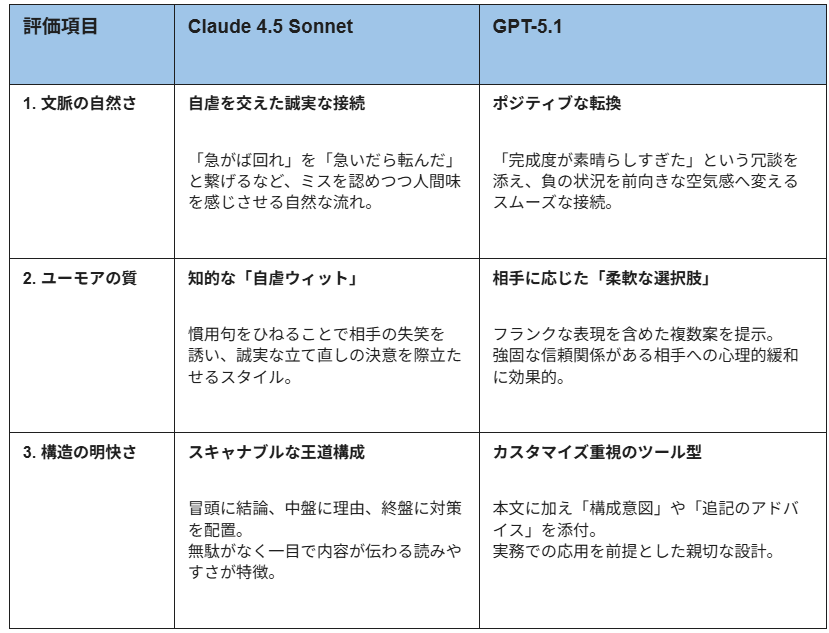
1.文脈の自然さ
両モデルとも、ビジネスメールとしての礼節を保ちつつユーモアを織り交ぜるという難易度の高い要求に対し、自然なアウトプットを示しました。
- Claude Sonnet 4.5
「急がば回れ」という慣用句をベースに「急いだら転んだ」と繋げることで、自身のミスを率直に認めつつ、誠実さと人間味を両立させています。 - GPT-5.2
「完成度が素晴らしすぎた」というポジティブな表現をあえて冗談として添えることで、遅延という負の状況を前向きな空気感へ変える工夫が見られます。
いずれも、唐突にジョークが挿入される違和感はなく、前後の謝罪文との接続もスムーズであり、実務でそのまま送信しても失礼にあたらない高度な文脈制御能力が確認できました。
2.ユーモアの質
ユーモアの方向性において、両者には興味深い違いが見られます。
- Claude Sonnet 4.5
「自虐的なウィット」を重視しており、慣用句のひねりによって、相手の失笑を誘いつつも「誠実に立て直す」という決意を際立たせる知的な構成です。 - GPT-5.2
複数の選択肢を提示することで、相手との距離感に応じたユーモアの使い分けを可能にしています。特に「あながち嘘でもないんです!(笑)」といった、ややフランクで自信を感じさせる表現は、強固な信頼関係がある相手に対して、重苦しい雰囲気を払拭するのに効果的です。
両モデルとも、相手を不快にさせるような「責任転嫁」や「不謹慎な冗談」を避け、コミュニケーションを円滑にするための「スパイス」として機能させています。
3.構造の明快さ
メールの構造化においては、いずれもビジネス文書の基本(結論、理由、謝罪、代替案、今後の対策)を完璧に網羅しています。
- Claude Sonnet 4.5
本文の冒頭で納期の1日延長を端的に伝え、中盤で理由とユーモアを添え、終盤で再発防止策を述べるという、スキャナブルで読みやすい構成です。 - GPT-5.2
メール本文に加えて「このメールの構成意図」や「具体的な理由の追記」といった補足解説を付随させており、ユーザーが状況に合わせてカスタマイズすることを前提としたツール的な親切さが際立ちます。
両者とも、件名から署名欄のプレースホルダーまで過不足なく整えられており、情報収集から資料化までの工数を大幅に削減できる完成度を有しています。
検証②
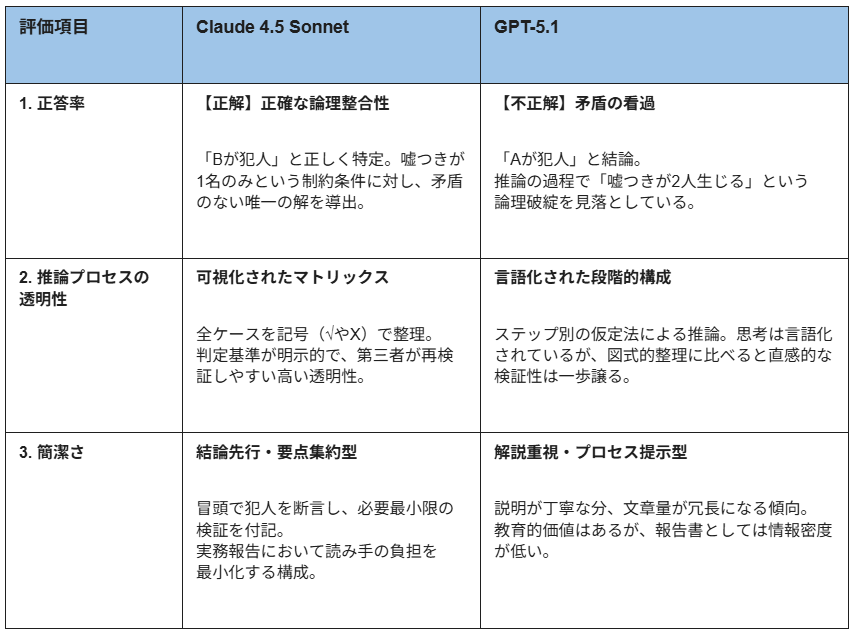
1.正答率
本パズルは「1人だけが嘘をついている」という条件に基づき、各容疑者の発言を検証する必要があります。
- Claude Sonnet 4.5
「Bが犯人」と仮定した場合にBのみが嘘(Dが犯人だという発言)をついている状態になり、他の4名が真実となる整合性を見事に指摘して正解を導き出しました。 - GPT-5.2
「Aが犯人」と結論付けています。GPTの推論では「Aが犯人ならAの発言(Bが犯人)は嘘になる」という点は正しいものの、その場合にBの発言(Dが犯人)も自動的に嘘となり「嘘つきが2人」生じる矛盾を見落としています。
結果として、複雑な条件分岐の最終的な正確性においては、Claude Sonnet 4.5がより高い信頼性を示しました。
2.推論プロセスの透明性
両モデルとも、結論に至るまでの「思考の足跡」を可視化する能力には長けています。
- Claude Sonnet 4.5
「全ケースの検証」という項目を立て、犯人がA〜Eだった場合の真偽値を記号(√やX)を用いてマトリックス状に整理しており、どの仮説で矛盾が生じたかが一目瞭然です。 - GPT-5.2
ステップ1からステップ4までの段階的な構成を採用し、「もし◯◯が嘘をついていたら」という仮定法を用いて思考を言語化しています。
情報の整理状況は両者とも高いレベルにありますが、特にClaude Sonnet 4.5は「条件に合う・合わない」の判定基準が明示的であり、第三者がその論理を再検証しやすいという点で、透明性がより優れていました。
3.簡潔さ
簡潔さの面では、回答の目的によって評価が分かれます。
- Claude Sonnet 4.5
まず冒頭で「犯人はBです」と断言し、その後に簡潔な検証を添える構成をとっており、結論をすぐに知りたいユーザーにとって効率的な回答となっています。必要な情報がコンパクトにまとまっており、無駄な重複もありません。 - GPT-5.2
推論の過程を丁寧に説明するため、文章量がやや多くなる傾向にあります。
論理のトレーニングや教育的な観点ではGPT-5.2の冗長な説明も価値がありますが、ビジネス実務における「分析結果の報告」という観点では、結論先行で要点を整理したClaude Sonnet 4.5の構成の方が、読み手の負担を抑えたスマートな回答と言えます。
結論
今回の検証の結果、実務における即戦力としての完成度や、論理的な正確性が求められるタスクにおいては、Claude Sonnet 4.5が高い信頼性を見せました。特に謝罪メールでの「人間味のある絶妙なバランス感覚」や、パズルにおける「全ケースを網羅する緻密な検証力」は、修正の手間を最小限に抑えたいビジネスシーンにおいて大きな安心感を与えてくれます。
一方で、GPT-5.2は、ユーザーに対して複数の選択肢を提示し、プロセスを言語化して並走してくれる「対話型の思考パートナー」としての強みが光りました。論理パズルではケアレスミスが見られたものの、メール作成で見せた柔軟な提案力や丁寧な解説は、正解が一つではない創造的なタスクや、AIと一緒に思考を深めていくプロセスにおいて、自分一人では到達できなかった新たな気づきを与えてくれます。
✅まとめ
AIは「どれか一つ」を選ぶフェーズから「用途に応じて組み合わせる」フェーズへと移行しています。
- Claude Sonnet 4.5:開発、長文処理、情緒的な文章作成におすすめ。
- GPT-5.2:高度な推論、論理構築、マルチモーダルな活用におすすめ。
それぞれの個性を理解し、状況に合わせて最適なパートナーを選ぶことが、これからの時代の生産性向上の鍵となります。
💡Yoomでできること
AIの真価は、手動でのチャットだけでなく、既存の業務フローと密接に連携したときに発揮されます。Yoomを使えば、今回比較したClaudeやChatGPTを、Slack、Notion、Googleドライブといった多くのアプリと繋ぎ、情報の要約、回答の自動生成、データの同期などをすべて自動で行うことができます。
「AIを使いこなしたいけれど、毎回プロンプトを入力するのが面倒…」と感じている方は、ぜひ以下のテンプレートから自動化の第一歩を踏み出してみてください。
■概要
Google Driveにアップロードされた請求書や議事録などを、都度ダウンロードして内容を確認し、要約を作成してメールで共有する作業は手間がかかるのではないでしょうか。このワークフローを活用すれば、Google Driveへのファイルアップロードをきっかけに、OCRによる文字情報の抽出からAnthropic(Claude)による要約、そしてGmailでのメール送信までの一連の業務を自動化し、これらの課題を解消します。
■このテンプレートをおすすめする方
- Google Driveに保存したPDFなどのファイル内容の確認や共有に手間を感じている方
- OCRで読み取ったテキストを手作業で要約し、メールに転記している方
- 複数のツールをまたぐ定型業務を自動化し、生産性を向上させたいと考えている方
■このテンプレートを使うメリット
- ファイルアップロードから情報抽出、要約、メール共有までが自動で実行されるため、手作業に費やしていた時間を他の業務に充てることができます。
- 手作業によるテキストの転記ミスや要約の抜け漏れ、メールの送信間違いといったヒューマンエラーのリスクを軽減します。
■フローボットの流れ
- はじめに、Google Drive、Anthropic(Claude)、GmailをYoomと連携します。
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します。
- 続いて、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知したファイルを指定します。
- 次に、オペレーションでOCRの「画像・PDFから文字を読み取る」アクションを設定し、ダウンロードしたファイルから文字情報を抽出します。
- 続いて、オペレーションでAnthropic(Claude)の「テキストを生成」アクションを設定し、OCRで抽出したテキストを要約します。
- 最後に、オペレーションでGmailの「メールを送る」アクションを設定し、生成された要約を本文に含めて指定の宛先に送信します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- Google Driveのトリガー設定では、自動化の起点としたい監視対象のフォルダを任意で指定してください。
- OCR機能では、画像やPDFファイルから抽出したい項目を、帳票の種類などに合わせて任意で設定することが可能です。
- Anthropic(Claude)の設定では、OCRで抽出したテキストを変数として用い、要約や翻訳など、任意のプロンプト(指示)を実行できます。
- Gmailでメールを送信するアクションでは、宛先(To, Cc, Bcc)や件名、本文を自由に設定でき、前工程で生成した要約などを変数として利用できます。
■注意事項
- Google DriveとAnthropic(Claude)とGmailのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。
■概要
GitHubで新しいIssueが作成されるたびに、内容を把握し、優先順位を判断するのは手間がかかる作業です。特に多くのIssueが同時に発生すると、重要な情報を見落としたり、対応が遅れてしまうこともあります。このワークフローを活用すれば、新しいIssueの作成をトリガーに、ChatGPTがその内容を自動で分析しコメントを追加するため、Issueの内容把握を迅速化し、開発プロセスの効率化に繋がります。
■このテンプレートをおすすめする方
- GitHubでのIssue管理に多くの時間を費やしているプロジェクトマネージャーの方
- ChatGPTを活用して、開発プロセスの初期対応を効率化したいと考えている方
- 手作業によるIssueの確認漏れや、対応の遅延を防ぎたい開発チームの方
■このテンプレートを使うメリット
- GitHubでIssueが作成されるとChatGPTが内容を分析・要約するため、手動での確認作業にかかる時間を短縮できます。
- Issueの内容把握が迅速かつ均一化され、担当者の割り振りや対応の優先順位付けがスムーズになり、開発プロセスの属人化を防ぎます。
■フローボットの流れ
- はじめに、GitHubとChatGPTをYoomと連携します。
- 次に、トリガーでGitHubを選択し、「Issueが新しく作成されたら」というアクションを設定し、フローが起動するきっかけを作ります。
- 続いて、オペレーションでChatGPTの「テキストを生成(高度な設定)」アクションを設定し、トリガーで取得したIssueのタイトルや本文を元に、内容の分析や要約を指示します。
- 最後に、オペレーションでGitHubの「Issue・Pull Requestにコメントを追加」アクションを設定し、ChatGPTが生成したテキストを該当のIssueにコメントとして投稿します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- ChatGPTの「テキストを生成」アクションを実行するには、OpenAIのAPI有料プランの契約が必要であり、APIが使用された際に支払いができる状態にしておく必要があります。
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
■注意事項
- GitHubとChatGPTのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
https://openai.com/ja-JP/api/pricing/ - ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
■概要
Google Driveにアップロードされた請求書や議事録などを、都度ダウンロードして内容を確認し、要約を作成してメールで共有する作業は手間がかかるのではないでしょうか。このワークフローを活用すれば、Google Driveへのファイルアップロードをきっかけに、OCRによる文字情報の抽出からAnthropic(Claude)による要約、そしてGmailでのメール送信までの一連の業務を自動化し、これらの課題を解消します。
■このテンプレートをおすすめする方
- Google Driveに保存したPDFなどのファイル内容の確認や共有に手間を感じている方
- OCRで読み取ったテキストを手作業で要約し、メールに転記している方
- 複数のツールをまたぐ定型業務を自動化し、生産性を向上させたいと考えている方
■このテンプレートを使うメリット
- ファイルアップロードから情報抽出、要約、メール共有までが自動で実行されるため、手作業に費やしていた時間を他の業務に充てることができます。
- 手作業によるテキストの転記ミスや要約の抜け漏れ、メールの送信間違いといったヒューマンエラーのリスクを軽減します。
■フローボットの流れ
- はじめに、Google Drive、Anthropic(Claude)、GmailをYoomと連携します。
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します。
- 続いて、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知したファイルを指定します。
- 次に、オペレーションでOCRの「画像・PDFから文字を読み取る」アクションを設定し、ダウンロードしたファイルから文字情報を抽出します。
- 続いて、オペレーションでAnthropic(Claude)の「テキストを生成」アクションを設定し、OCRで抽出したテキストを要約します。
- 最後に、オペレーションでGmailの「メールを送る」アクションを設定し、生成された要約を本文に含めて指定の宛先に送信します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- Google Driveのトリガー設定では、自動化の起点としたい監視対象のフォルダを任意で指定してください。
- OCR機能では、画像やPDFファイルから抽出したい項目を、帳票の種類などに合わせて任意で設定することが可能です。
- Anthropic(Claude)の設定では、OCRで抽出したテキストを変数として用い、要約や翻訳など、任意のプロンプト(指示)を実行できます。
- Gmailでメールを送信するアクションでは、宛先(To, Cc, Bcc)や件名、本文を自由に設定でき、前工程で生成した要約などを変数として利用できます。
■注意事項
- Google DriveとAnthropic(Claude)とGmailのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。
■概要
GitHubで新しいIssueが作成されるたびに、内容を把握し、優先順位を判断するのは手間がかかる作業です。特に多くのIssueが同時に発生すると、重要な情報を見落としたり、対応が遅れてしまうこともあります。このワークフローを活用すれば、新しいIssueの作成をトリガーに、ChatGPTがその内容を自動で分析しコメントを追加するため、Issueの内容把握を迅速化し、開発プロセスの効率化に繋がります。
■このテンプレートをおすすめする方
- GitHubでのIssue管理に多くの時間を費やしているプロジェクトマネージャーの方
- ChatGPTを活用して、開発プロセスの初期対応を効率化したいと考えている方
- 手作業によるIssueの確認漏れや、対応の遅延を防ぎたい開発チームの方
■このテンプレートを使うメリット
- GitHubでIssueが作成されるとChatGPTが内容を分析・要約するため、手動での確認作業にかかる時間を短縮できます。
- Issueの内容把握が迅速かつ均一化され、担当者の割り振りや対応の優先順位付けがスムーズになり、開発プロセスの属人化を防ぎます。
■フローボットの流れ
- はじめに、GitHubとChatGPTをYoomと連携します。
- 次に、トリガーでGitHubを選択し、「Issueが新しく作成されたら」というアクションを設定し、フローが起動するきっかけを作ります。
- 続いて、オペレーションでChatGPTの「テキストを生成(高度な設定)」アクションを設定し、トリガーで取得したIssueのタイトルや本文を元に、内容の分析や要約を指示します。
- 最後に、オペレーションでGitHubの「Issue・Pull Requestにコメントを追加」アクションを設定し、ChatGPTが生成したテキストを該当のIssueにコメントとして投稿します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- ChatGPTの「テキストを生成」アクションを実行するには、OpenAIのAPI有料プランの契約が必要であり、APIが使用された際に支払いができる状態にしておく必要があります。
- ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
■注意事項
- GitHubとChatGPTのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
https://openai.com/ja-JP/api/pricing/ - ChatGPTのAPI利用はOpenAI社が有料で提供しており、API疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
プログラミング知識なしで手軽に構築できます。








