とにかく早く試したい方へ
Yoomにはアラビア語のファイルをOCRで読み取りテキスト化する業務フロー自動化のテンプレート が用意されています。
Gmailでアラビア語のファイルを受信したら、OCRで読み取りNotionにレコードを追加する
試してみる
■概要
アラビア語で書かれた請求書や書類がメールで届くたびに、内容を確認して手作業で転記する業務に手間を感じていませんか?
■このテンプレートをおすすめする方
アラビア語の請求書や書類をメールで受け取る機会が多い経理や営業事務の方 OCRの技術を活用し、手作業でのデータ入力業務を自動化したいと考えている方 GmailとNotionを日常的に利用し、情報管理の効率化を目指している業務担当者の方 ■このテンプレートを使うメリット
Gmailでファイルを受信するだけで、Arabic OCRによる読み取りからNotionへの転記までが自動化されるため、手作業の時間を削減できます。 言語の専門性が求められる読み取りや転記作業がなくなることで、入力ミスや確認漏れといったヒューマンエラーの防止に繋がります。 ■フローボットの流れ
はじめに、GmailとNotionをYoomと連携します。 次に、トリガーでGmailを選択し、「特定のラベルのメールを受信したら」というアクションを設定します。 次に、オペレーションでOCR機能を選択し、「画像・PDFから文字を読み取る」アクションで添付ファイルからアラビア語のテキストを抽出します。 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、抽出したテキストデータを指定のデータベースに自動で追加します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Gmailのトリガー設定では、自動化の対象としたいメールに付与するラベルを任意で設定してください。 OCRのオペレーションでは、ファイルから読み取りたい項目を任意で設定することで、必要な情報だけを抽出できます。 Notionでレコードを追加するアクションを設定する際に、情報を保存したいデータベースのIDを任意で設定してください。 ■注意事項
Gmail、NotionのそれぞれとYoomを連携してください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。
アラビア語で書かれた請求書や書類が届くたび、その内容を手作業で入力する業務に追われていませんか?
もし、メールで受信したアラビア語のファイルやストレージに保存された書類を自動で読み取り、テキストデータを抽出できる仕組み があれば、こうした面倒な手作業から解放され、より生産性の高いコア業務に集中する時間を生み出すことができます!
今回ご紹介する自動化の設定は、ノーコードで簡単に設定できて、手間や時間もかかりません。
アラビア語OCRとは?基本的な知識
アラビア語OCR(光学文字認識)は、アラビア語の紙文書をデジタル化して編集可能なテキストに変換する便利な技術ですが、いくつかの問題点もあります。アラビア語は右から左に書かれ、文字が接続するため、OCRエンジンがその特徴にうまく対応できないことがあります。ノーコードでツールを連携させて自動化するのが効果的です。 Yoomを使えば、OCRで得たデータをGoogle SheetsやCRMに自動入力し、業務をスムーズに進めることができます。
アラビア語ファイルとOCRを組み合わせた自動化例
アラビア語で書かれた書類や画像ファイルから、手作業で文字を抜き出すのは大変な作業ですよね。そこでOCR機能を活用して自動化すれば、この手間を削減し、ヒューマンエラーを防ぐことができます!
ここでは、様々なツールを起点にアラビア語のファイルをOCRで読み取り、テキストデータを活用する自動化の具体例をテンプレートでご紹介します。
メールの受信をトリガーに、アラビア語ファイルをOCRで読み取る
Gmailなどのメールツールで受信したアラビア語のファイルをトリガーにして、自動でOCR処理を実行しテキストを抽出する ことができるので、メールで届く請求書や書類のデータ化を効率化できます。
Gmailでアラビア語のファイルを受信したら、OCRで読み取りNotionにレコードを追加する
試してみる
■概要
アラビア語で書かれた請求書や書類がメールで届くたびに、内容を確認して手作業で転記する業務に手間を感じていませんか?
■このテンプレートをおすすめする方
アラビア語の請求書や書類をメールで受け取る機会が多い経理や営業事務の方 OCRの技術を活用し、手作業でのデータ入力業務を自動化したいと考えている方 GmailとNotionを日常的に利用し、情報管理の効率化を目指している業務担当者の方 ■このテンプレートを使うメリット
Gmailでファイルを受信するだけで、Arabic OCRによる読み取りからNotionへの転記までが自動化されるため、手作業の時間を削減できます。 言語の専門性が求められる読み取りや転記作業がなくなることで、入力ミスや確認漏れといったヒューマンエラーの防止に繋がります。 ■フローボットの流れ
はじめに、GmailとNotionをYoomと連携します。 次に、トリガーでGmailを選択し、「特定のラベルのメールを受信したら」というアクションを設定します。 次に、オペレーションでOCR機能を選択し、「画像・PDFから文字を読み取る」アクションで添付ファイルからアラビア語のテキストを抽出します。 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、抽出したテキストデータを指定のデータベースに自動で追加します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Gmailのトリガー設定では、自動化の対象としたいメールに付与するラベルを任意で設定してください。 OCRのオペレーションでは、ファイルから読み取りたい項目を任意で設定することで、必要な情報だけを抽出できます。 Notionでレコードを追加するアクションを設定する際に、情報を保存したいデータベースのIDを任意で設定してください。 ■注意事項
Gmail、NotionのそれぞれとYoomを連携してください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。
フォーム受信をトリガーに、アラビア語ファイルをOCRで読み取る
Googleフォームなどのフォームツールで受け付けたアラビア語のファイルを起点として、自動的にOCRでテキストを読み取る ことで、申請書やアンケートなどのファイル提出があった際のデータ処理を迅速に行えます。
Googleフォームでアラビア語のファイルが送付されたら、OCRで読み取りGoogle スプレッドシートに登録する
試してみる
■概要
海外とのやり取りで受け取るアラビア語の書類や画像ファイルについて、内容の確認やシステムへの手入力に手間を感じていませんか?手作業での転記は時間がかかるだけでなく、入力ミスの原因にもなり得ます。このワークフローを活用すれば、Googleフォームで受け取ったファイルを自動でOCR処理し、抽出したテキストをGoogle スプレッドシートへ登録するため、こうした課題を円滑に解消し、データ入力業務を効率化できます。
■このテンプレートをおすすめする方
アラビア語で記載された画像やPDFファイルの内容を手作業で転記している方 OCRの技術を活用して、データ入力業務の自動化を検討している方 GoogleフォームとGoogle スプレッドシート間の手作業での連携に課題を感じている方 ■このテンプレートを使うメリット
Googleフォームへのファイル提出を起点に、OCRでの文字抽出からGoogle スプレッドシートへの登録までが自動化されるため、これまで手作業に費やしていた時間を削減できます。 人の手による転記作業が不要になるため、読み間違いや入力ミスといったヒューマンエラーを防ぎ、データの正確性を高めることに繋がります。 ■フローボットの流れ
はじめに、Google スプレッドシート、GoogleフォームをYoomと連携します。 次に、トリガーでGoogleフォームを選択し、「フォームに回答が送信されたら」というアクションを設定します。 次に、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、フォームに添付されたファイルをダウンロードします。 続けて、OCR機能の「画像・PDFから文字を読み取る」アクションを設定し、ダウンロードしたファイルからアラビア語のテキストを抽出します。 最後に、Google スプレッドシートの「レコードを追加する」アクションを設定し、抽出したテキストデータを指定のシートに登録します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Googleフォームのトリガー設定では、自動化の対象としたいフォームのIDを任意で設定してください。 OCRのオペレーションでは、読み取りたいファイルの中から、どの部分のテキストを抽出するか、抽出項目を任意で設定してください。 Google スプレッドシートのオペレーションでは、抽出したデータを登録するスプレッドシートのIDとシート名を任意で設定してください。 ■注意事項
Googleフォーム、Google スプレッドシートのそれぞれとYoomを連携してください。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。 ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。 トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は下記をご参照ください。https://intercom.help/yoom/ja/articles/9413924 Googleフォームをトリガーとして使用した際の回答内容を取得する方法は下記を参照ください。https://intercom.help/yoom/ja/articles/6807133
ストレージサービスへのファイル追加をトリガーに、アラビア語ファイルをOCRで読み取る
Dropboxなどのオンラインストレージサービスにアラビア語のファイルがアップロードされたことをきっかけに、自動でOCR処理を起動し内容をテキスト化する ことも可能で、大量の書類を保管しながら効率的にデータ化を進められます。
Dropboxにアラビア語のファイルがアップロードされたら、OCRで読み取りAirtableに追加する
試してみる
■概要
アラビア語で記載された請求書や申込書などの書類を扱う際、手作業でのデータ入力や転記に手間を感じていませんか。専門的なOCRツールを導入せずとも、日々の業務を効率化したいと考える方もいるはずです。このワークフローを活用すれば、Dropboxにファイルをアップロードするだけで、OCR機能がアラビア語の文字情報を自動で読み取り、Airtableのデータベースへ格納するため、面倒なデータ入力作業から解放されます。
■このテンプレートをおすすめする方
アラビア語の書類を扱っており、OCRによるデータ化を検討している方 DropboxとAirtableで情報管理をしており、手作業でのデータ転記をなくしたい方 海外拠点や取引先との書類のやり取りを、言語の壁を越えて効率化したいと考えている方 ■このテンプレートを使うメリット
Dropboxへのファイルアップロードを起点に、OCRでの文字抽出からAirtableへの登録までが自動化され、手作業の時間を削減できます。 手動でのデータ転記が不要になるため、入力ミスや読み間違いといったヒューマンエラーを防ぎ、データの正確性を保つことに繋がります。 ■フローボットの流れ
はじめに、AirtableとDropboxをYoomと連携します。 次に、トリガーでDropboxを選択し、「特定のフォルダ内でファイルが作成または更新されたら」というアクションを設定します。 次に、オペレーションで、Dropboxの「ファイルをダウンロード」アクションを設定します。 続いて、オペレーションでOCRの「画像・PDFから文字を読み取る」アクションを設定し、ダウンロードしたファイルからアラビア語のテキストを抽出します。 最後に、オペレーションでAirtableの「レコードを作成」アクションを設定し、抽出した情報を任意のテーブルに追加します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Dropboxのトリガー設定では、監視対象としたいフォルダのパスやファイル名を任意で設定してください。 OCRのオペレーションでは、書類の中から読み取りたい項目(例:請求日、金額など)を任意で設定します。 Airtableにレコードを作成する際に、データの追加先となるベースID、テーブルIDまたは名前、および各フィールド情報を任意で設定してください。 ■注意事項
Dropbox、AirtableのそれぞれとYoomを連携してください。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。 ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。 トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は下記をご参照ください。https://intercom.help/yoom/ja/articles/9413924
Gmailで受信したアラビア語ファイルをOCRで読み取るフローを作ってみよう
それではここから代表的な自動化例として、Gmailで特定のアラビア語ファイルが添付されたメールを受信した際に、OCR機能でファイルの内容を自動で読み取り、Notionのデータベースに記録するフローを解説 していきます!
ここではYoomを使用してノーコードで設定をしていきます。こちら の登録フォーム からアカウントを発行しておきましょう。
※今回連携するアプリの公式サイト:Gmail Notion
[Yoomとは]
フローの作成方法
今回は大きく分けて以下のプロセスで作成します。
GmailとNotionのマイアプリ連携
テンプレートをコピー
Gmailのトリガー設定とOCR、Notionのアクション設定
トリガーをONにし、フローが起動するかを確認
ステップ1: GmailとNotionをマイアプリ連携
ここでは、Yoomとそれぞれのアプリを連携して、操作が行えるようにしていきます。
それではここから今回のフローで使用するアプリのマイアプリ登録方法を解説します。
Gmailの場合
新規接続をクリックしたあと、アプリのメニュー一覧が表示されるのでGmailと検索し対象アプリをクリックしてください。
Googleアカウントの選択画面が表示されるので、連携したいアカウントをクリックしてください。
選択したGoogleアカウントでログイン確認画面が表示されるので、「次へ」をクリックします。
アクセス権限の確認画面が表示されるので、「続行」をクリックして連携を完了させましょう。
Notionの場合
まず、事前準備として Notion上にデータベースを作成しておきましょう。データベースはこのタイミングで作成しておかないと、後述するアクセス許可画面に表示されないため注意が必要です。
新規接続をクリックしたあと、アプリのメニュー一覧が表示されるのでNotionと検索し対象アプリをクリックしてください。
下記の画面が表示されるので、任意の方法でログインします。
パスワードを入力し、「ログイン」をクリックします。
YoomからNotionへのアクセス権限を確認し、「ページを選択する」をクリックします。
Yoomがアクセスできるページを選択し、「アクセスを許可する」をクリックします。
ステップ2: 該当のテンプレートをコピー
ここからいよいよフローの作成に入ります。
Gmailでアラビア語のファイルを受信したら、OCRで読み取りNotionにレコードを追加する
試してみる
■概要
アラビア語で書かれた請求書や書類がメールで届くたびに、内容を確認して手作業で転記する業務に手間を感じていませんか?
■このテンプレートをおすすめする方
アラビア語の請求書や書類をメールで受け取る機会が多い経理や営業事務の方 OCRの技術を活用し、手作業でのデータ入力業務を自動化したいと考えている方 GmailとNotionを日常的に利用し、情報管理の効率化を目指している業務担当者の方 ■このテンプレートを使うメリット
Gmailでファイルを受信するだけで、Arabic OCRによる読み取りからNotionへの転記までが自動化されるため、手作業の時間を削減できます。 言語の専門性が求められる読み取りや転記作業がなくなることで、入力ミスや確認漏れといったヒューマンエラーの防止に繋がります。 ■フローボットの流れ
はじめに、GmailとNotionをYoomと連携します。 次に、トリガーでGmailを選択し、「特定のラベルのメールを受信したら」というアクションを設定します。 次に、オペレーションでOCR機能を選択し、「画像・PDFから文字を読み取る」アクションで添付ファイルからアラビア語のテキストを抽出します。 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、抽出したテキストデータを指定のデータベースに自動で追加します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Gmailのトリガー設定では、自動化の対象としたいメールに付与するラベルを任意で設定してください。 OCRのオペレーションでは、ファイルから読み取りたい項目を任意で設定することで、必要な情報だけを抽出できます。 Notionでレコードを追加するアクションを設定する際に、情報を保存したいデータベースのIDを任意で設定してください。 ■注意事項
Gmail、NotionのそれぞれとYoomを連携してください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。
テンプレートがコピーされると、以下のような画面が表示されますので、「OK」をクリックして設定を進めましょう。
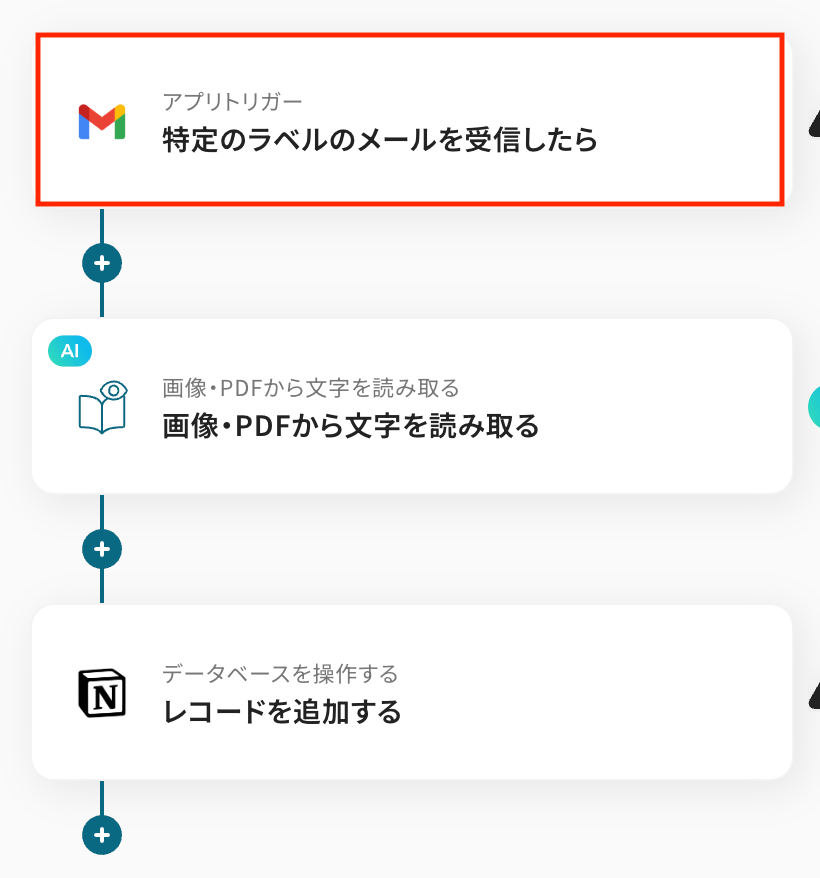
ステップ3: Gmailのトリガー設定
「特定のラベルのメールを受信したら」をクリックします。
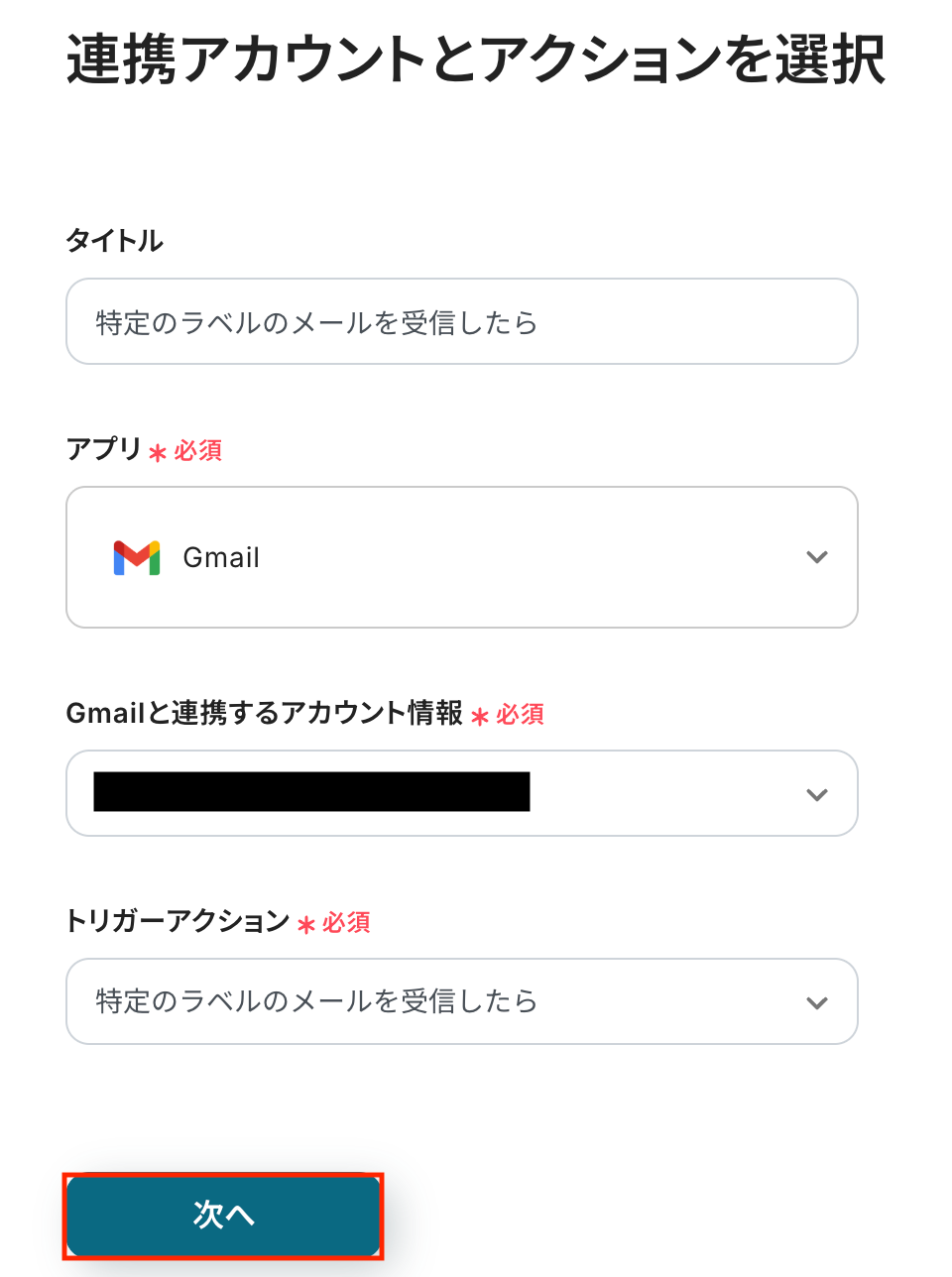
タイトルは任意で変更できます。
Gmailと連携するアカウント情報に問題がなければ、「次へ」をクリックします。
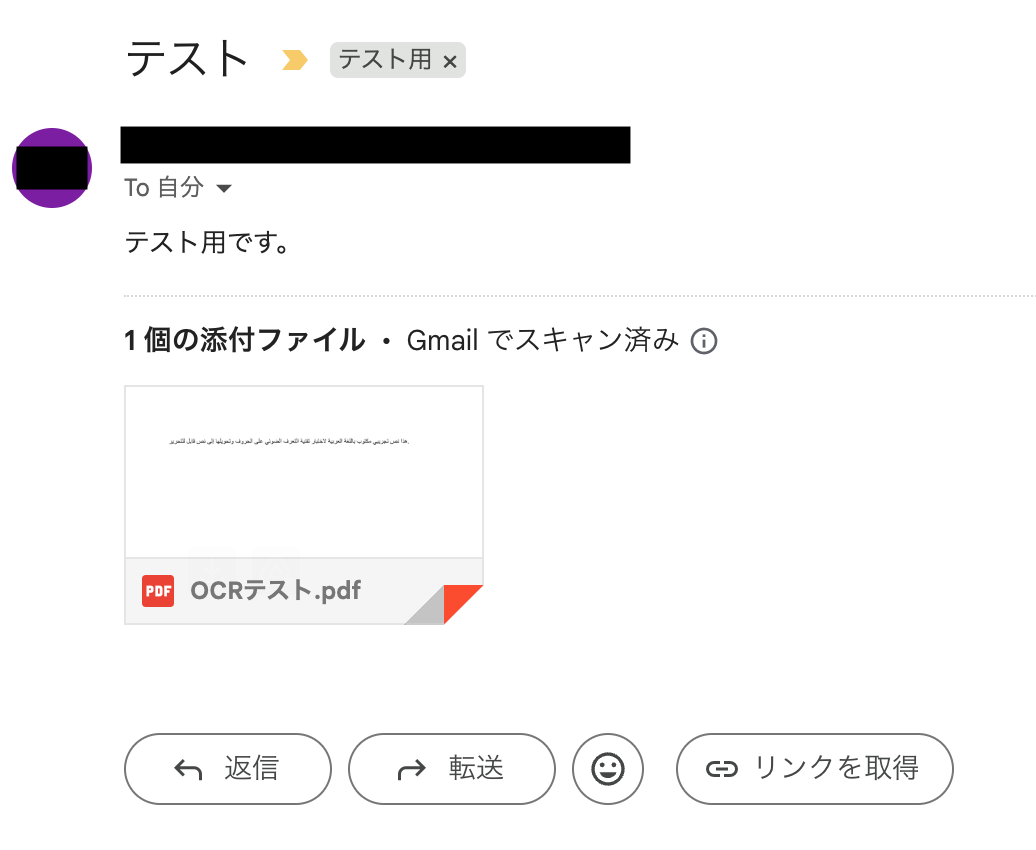
事前準備として、Gmailで「特定ラベルのメール」を受信しておきましょう。
また、後続のステップでOCR機能を使用して文字を読み取るため、アラビア語のファイルを添付しています。
Yoomの操作画面に戻り、トリガーの設定を行います。
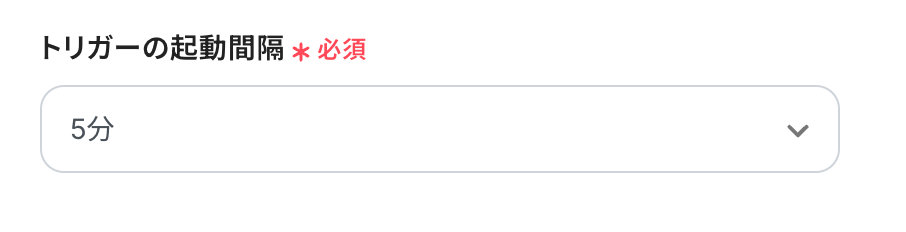
トリガーの起動タイミングは、5分、10分、15分、30分、60分のいずれかで設定できます。ご利用プラン
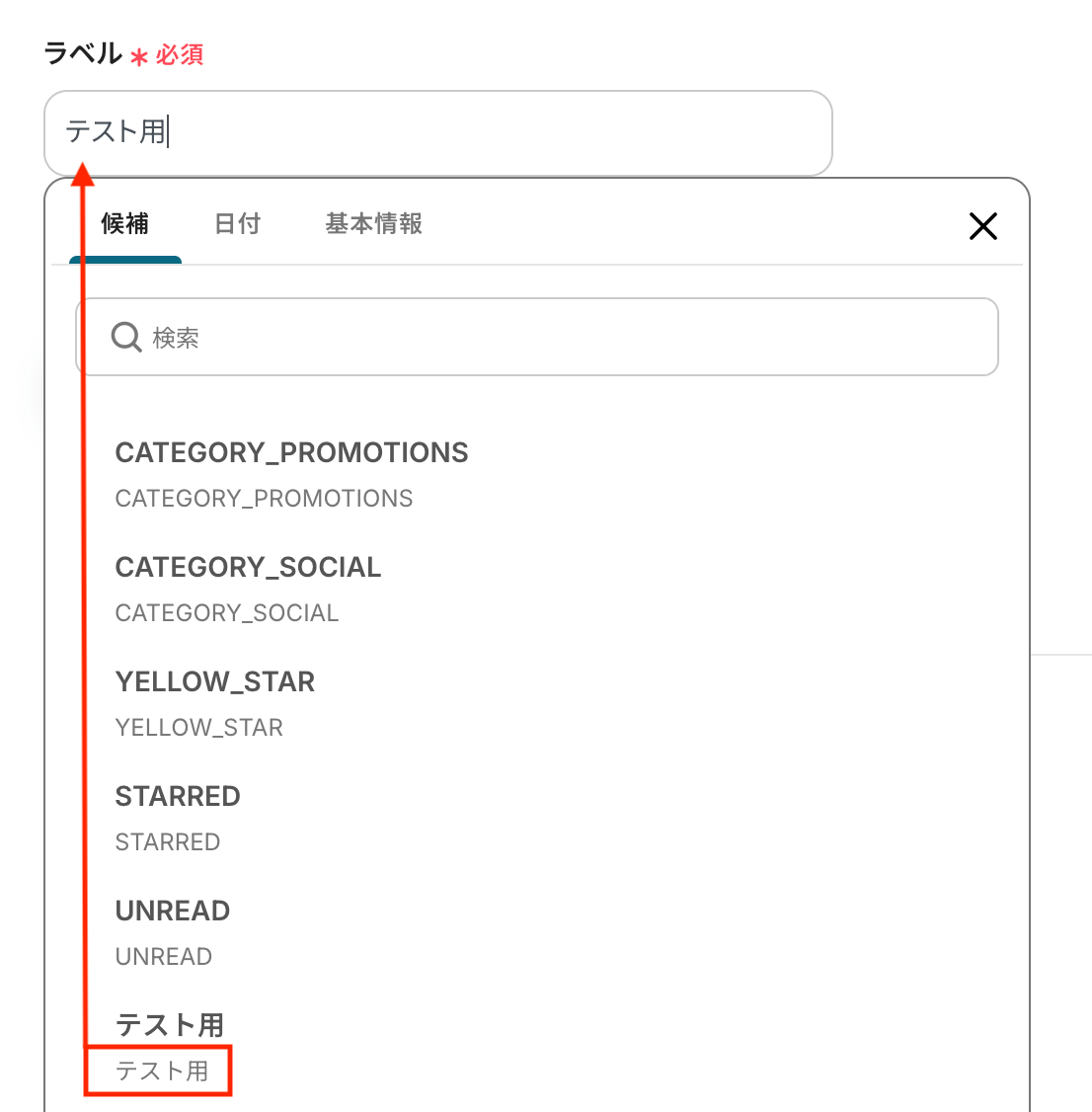
ラベル
入力が完了したら、設定内容とトリガーの動作を確認するため「テスト」をクリックします。
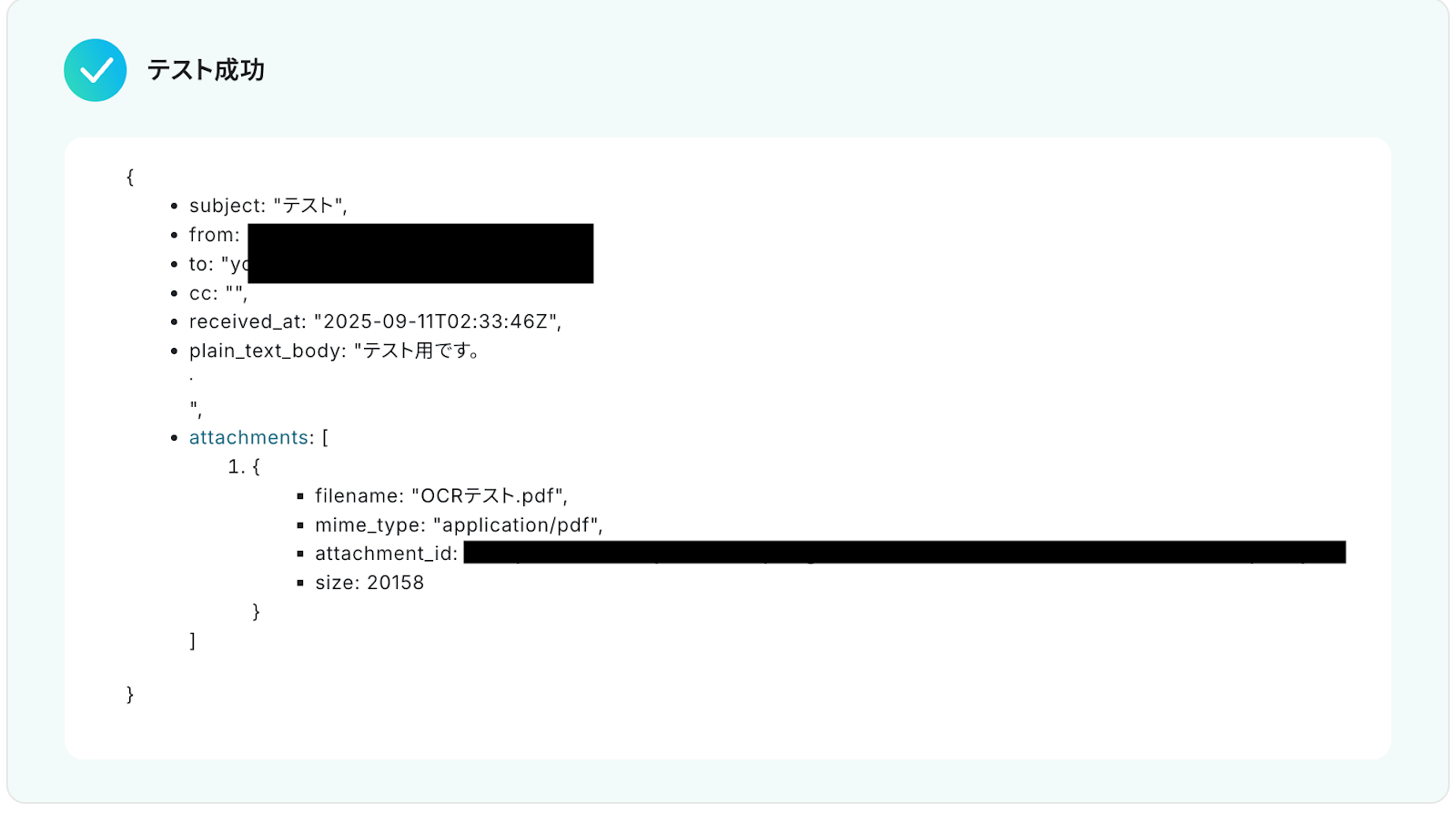
テストに成功すると、Gmailで受信した特定ラベルのメールに関する情報が一覧で表示されます。
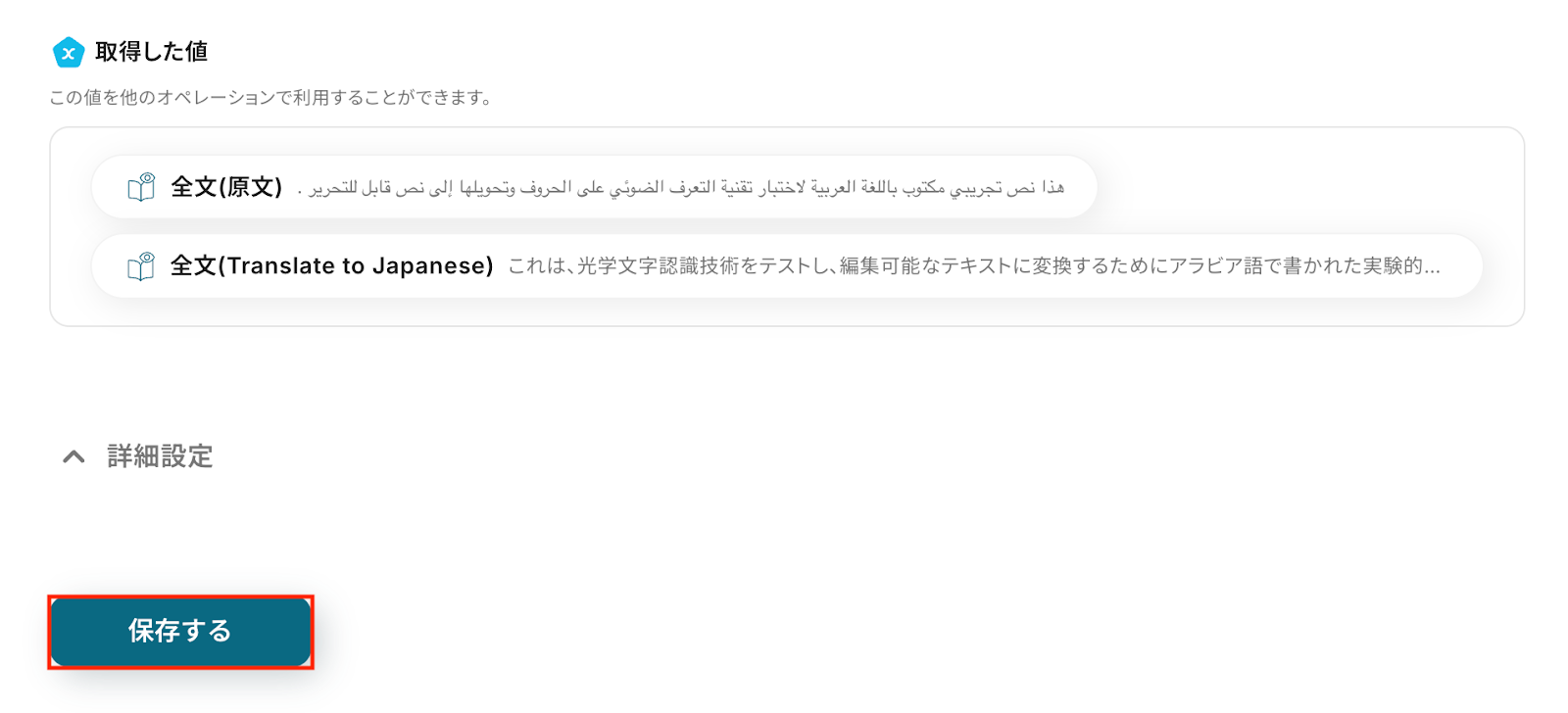
以下の画像の取得した値
内容を確認し、「保存する」をクリックします。
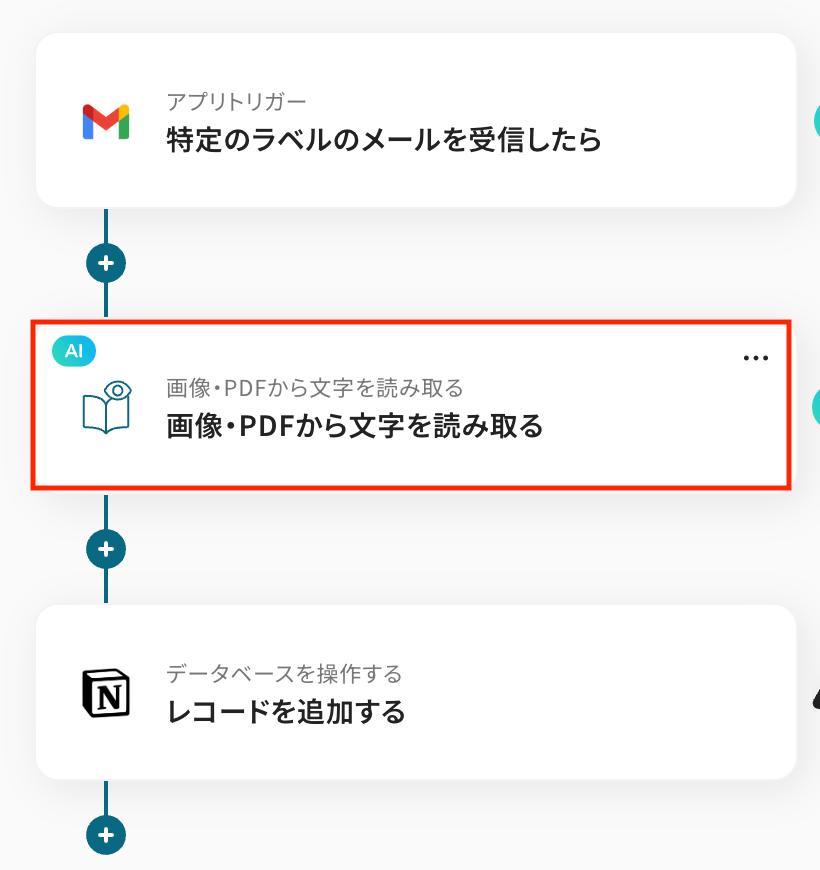
ステップ4: OCR機能で文字の読み取り
「画像・PDFから文字を読み取る」をクリックします。
画像やPDFファイルから文字を読み取るアクションを設定します。
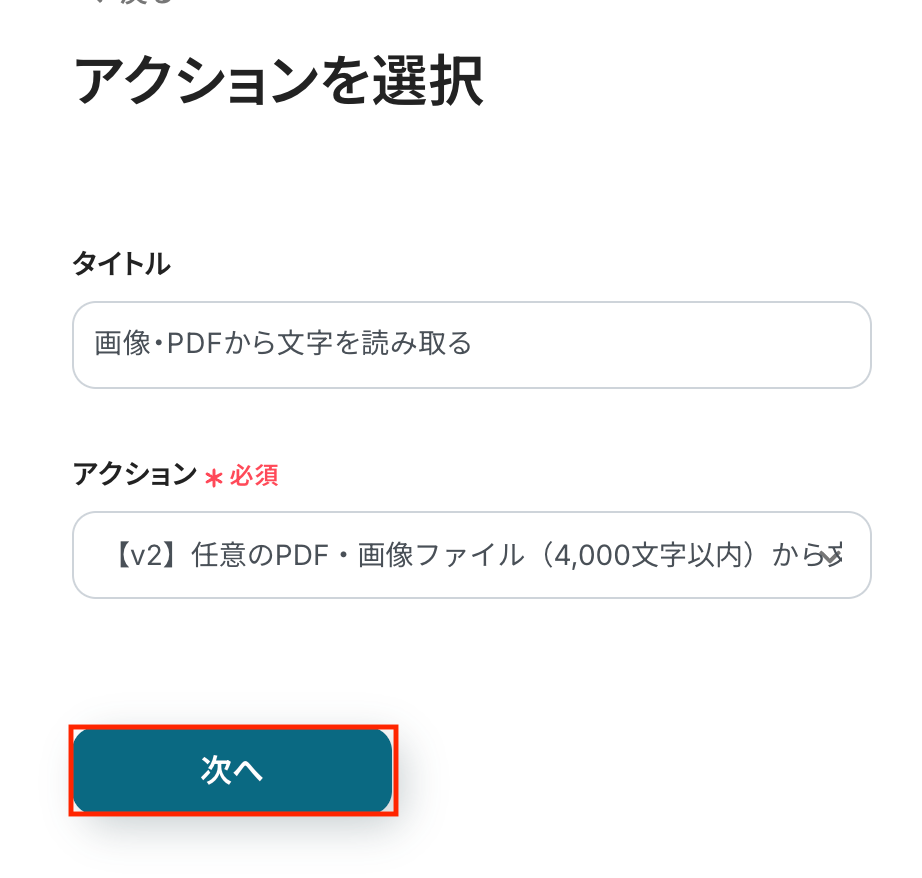
確認後、「次へ」をクリックします。
書類から文字情報を読み取る(OCR機能)では、AIモデルによってできること、できないことが異なります。
【注意事項】
OCRや音声を文字起こしするAIオペレーションは、チームプラン・サクセスプラン限定の機能です。
チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルが可能です。
YoomのOCR機能では、アクション記載の規定の文字数を超えるデータや、文字が小さすぎる場合に正しく読み取れないことがあります。
ファイルの添付方法
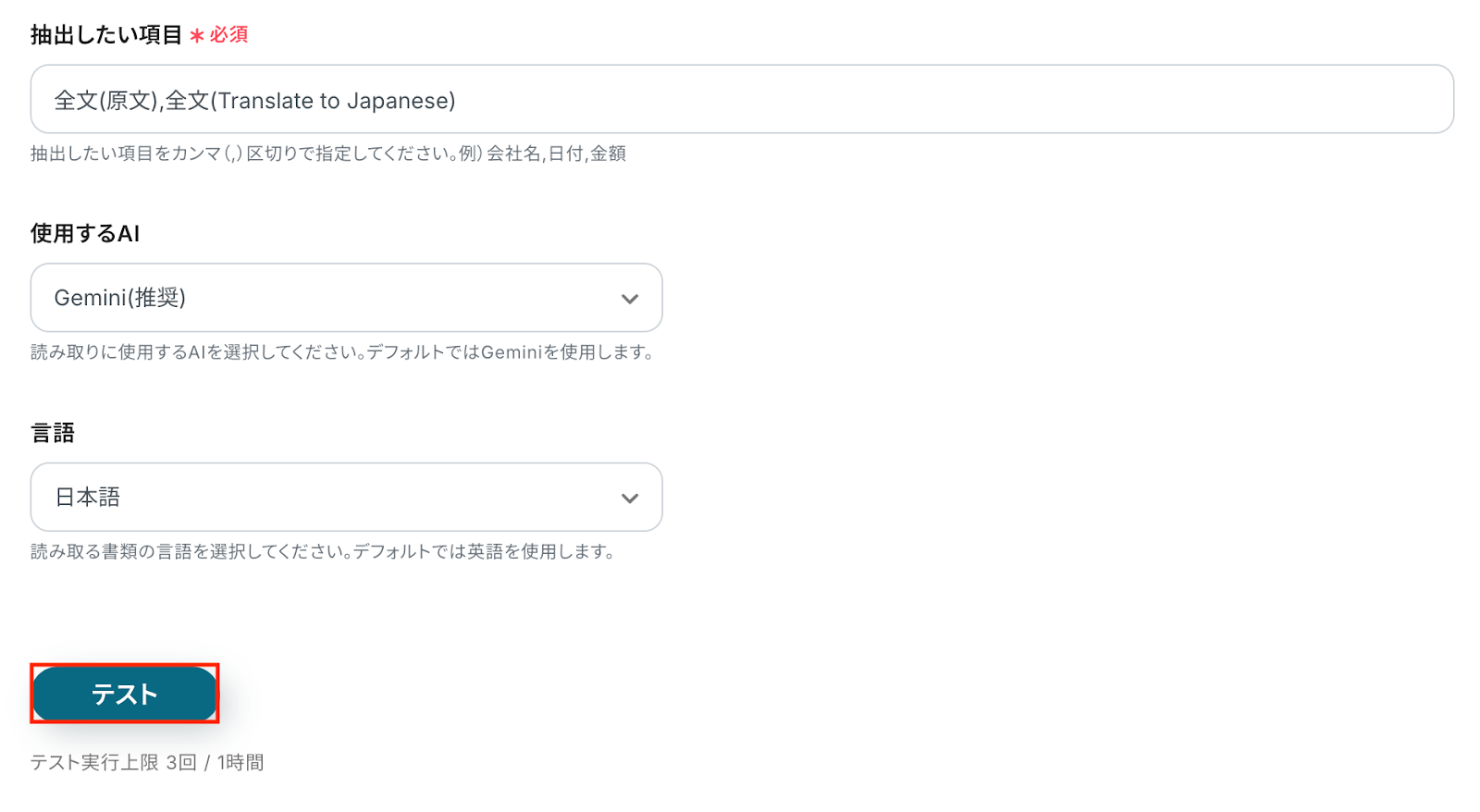
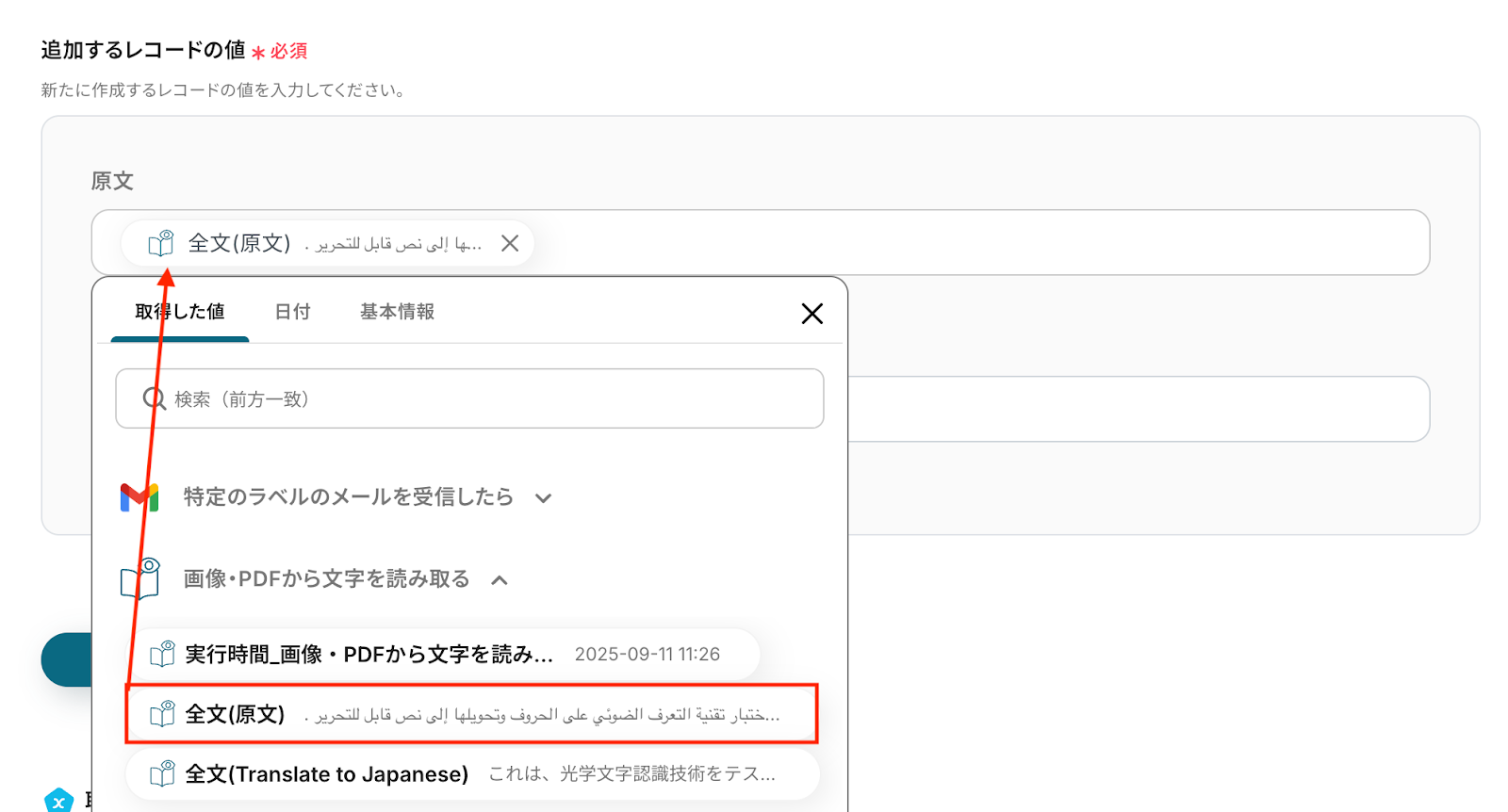
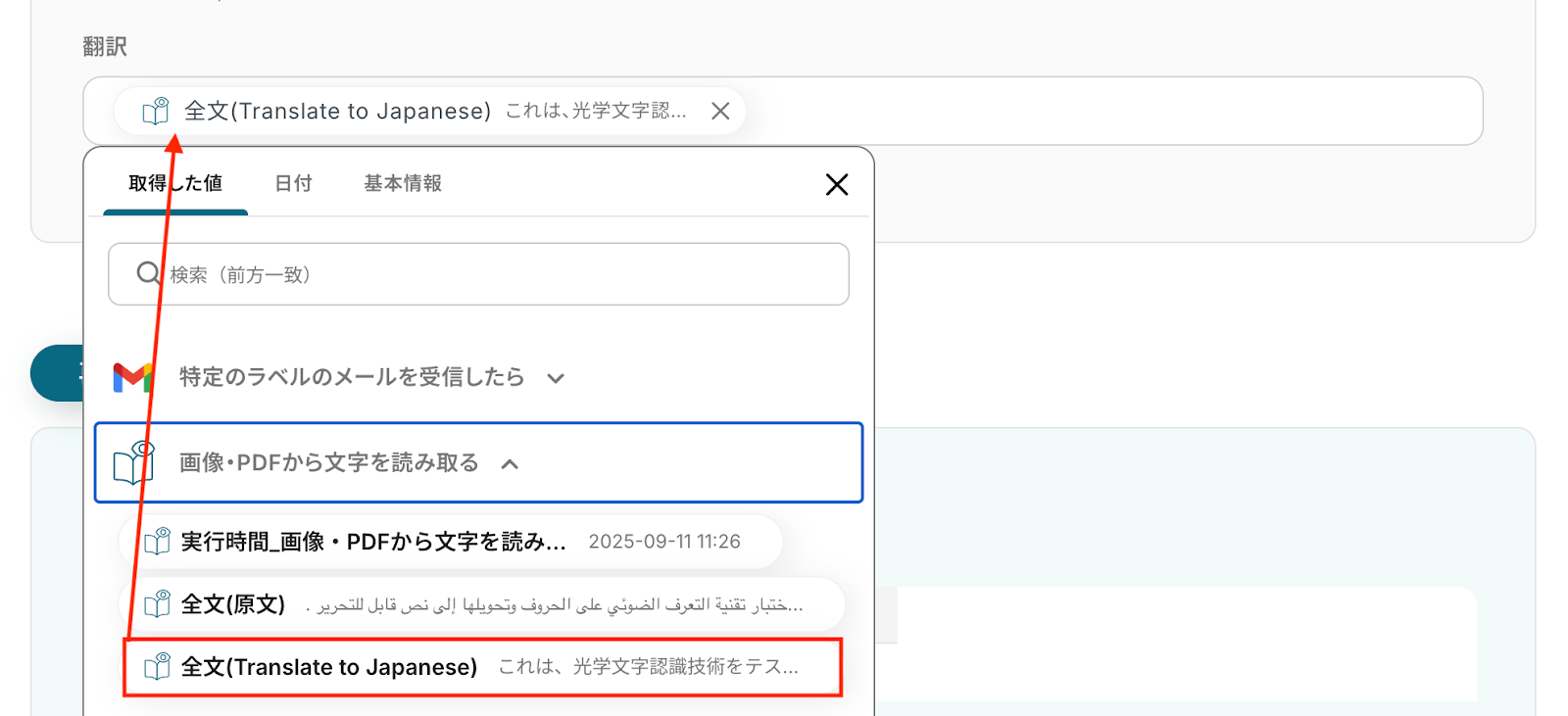
抽出したい項目 今回はメールの添付ファイルからアラビア語の原文とその翻訳結果(日本語)を抽出し、Notionにレコードとして追加します。
使用するAI、使用する言語
OCRの設定について、詳しくは以下のヘルプページもご参照ください。
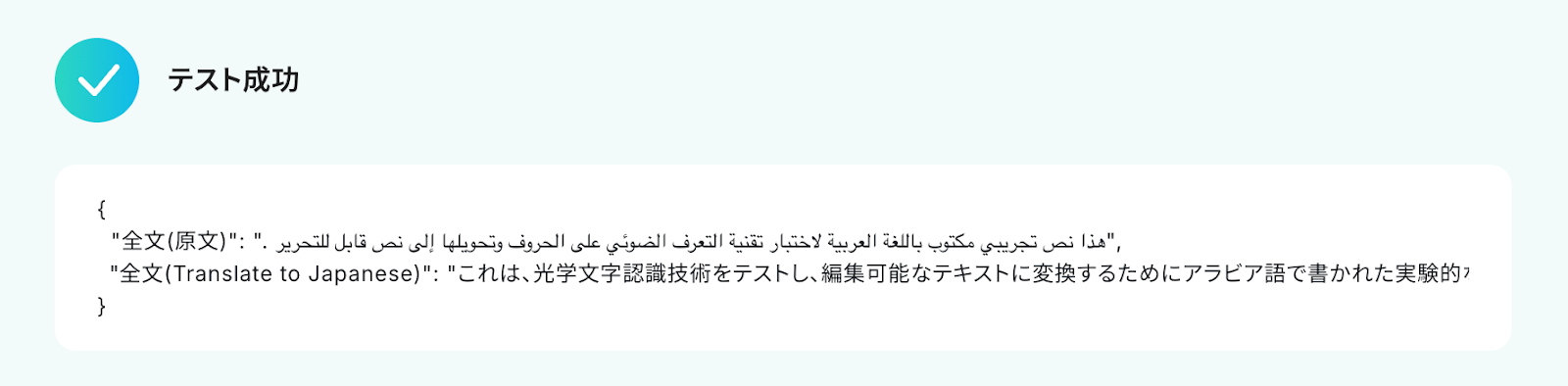
テストに成功すると、AIによって添付ファイルから読み取り・翻訳された情報が一覧で表示されます。
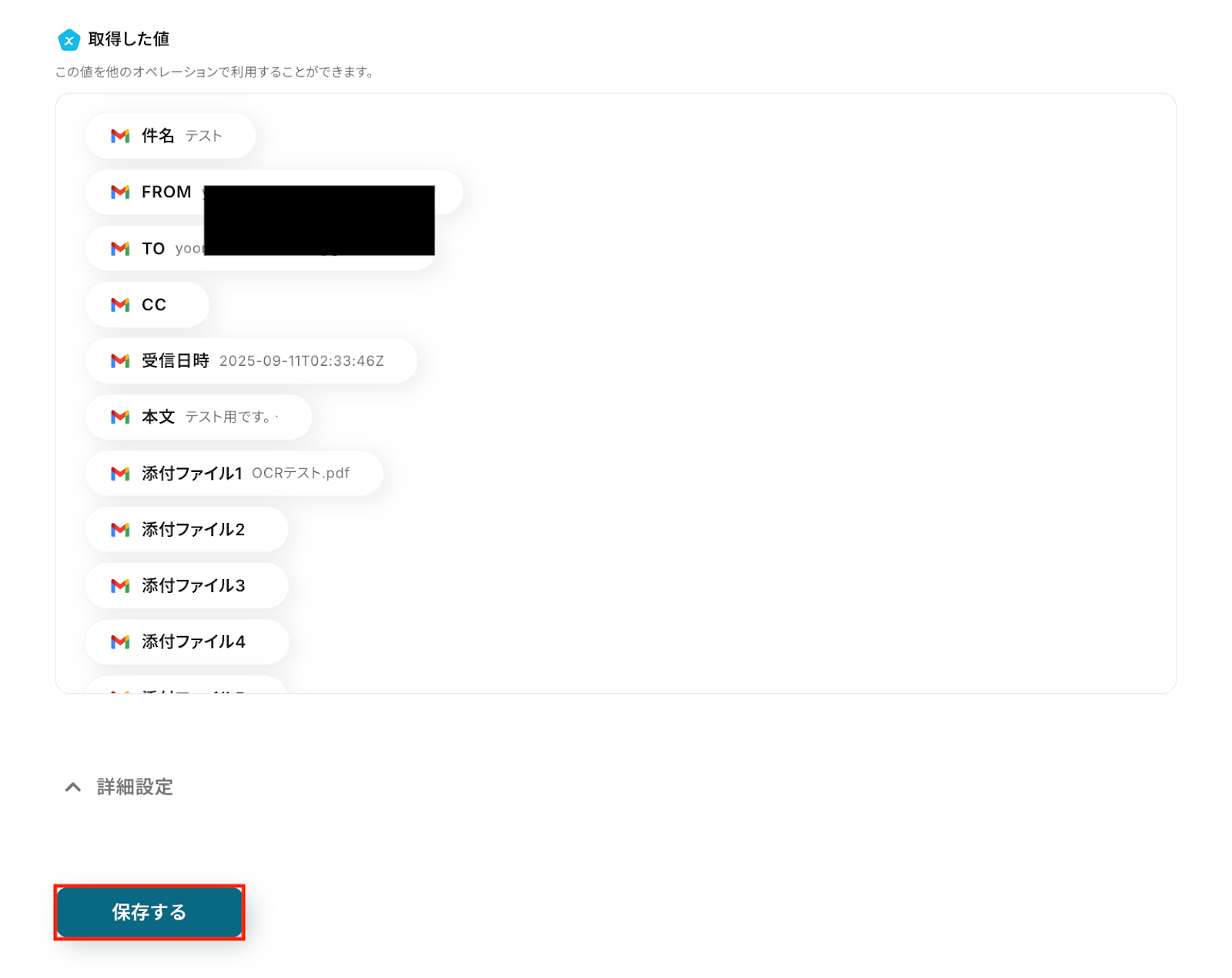
以下の画像の取得した値を使用して、Notionへレコードの追加が可能です。
内容を確認し、「保存する」をクリックします。
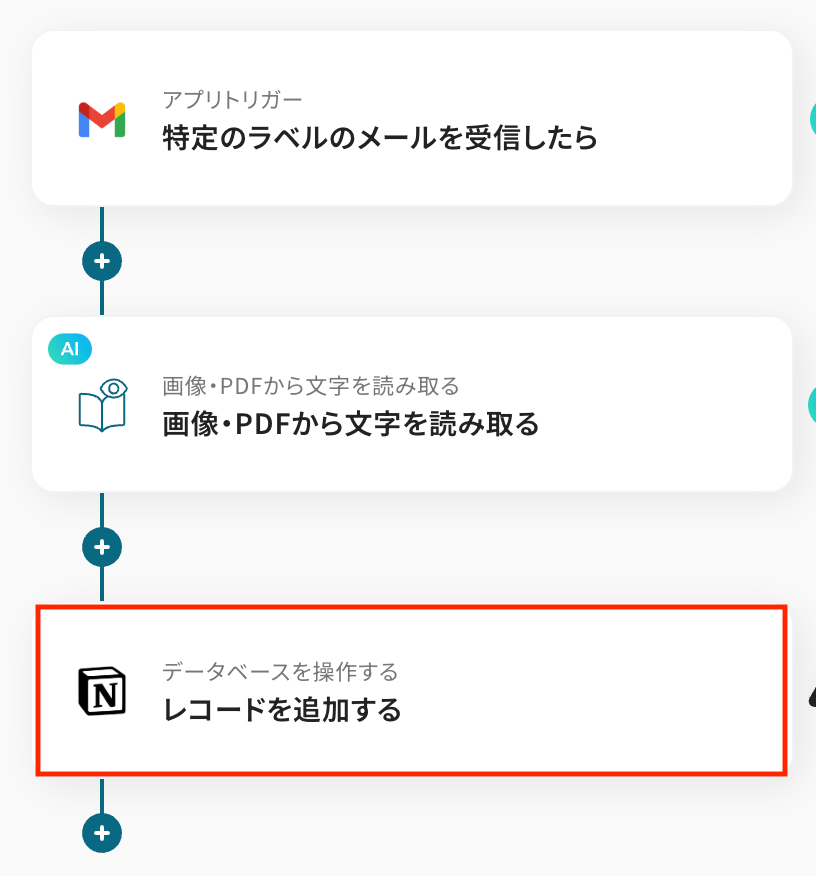
ステップ5: Notionのアクション設定
「レコードを追加する」をクリックします。
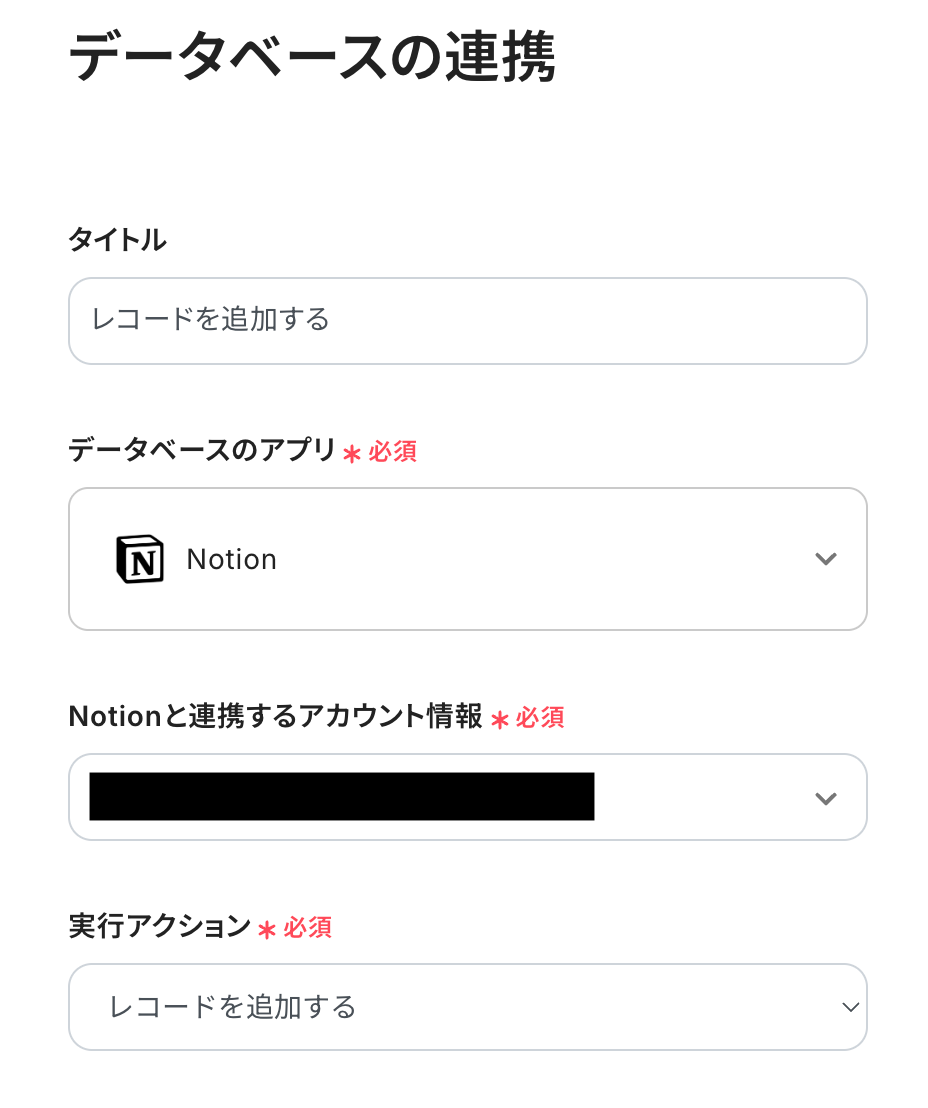
タイトルは任意で変更できます。
Notionと連携するアカウント情報に問題がないか確認しましょう。
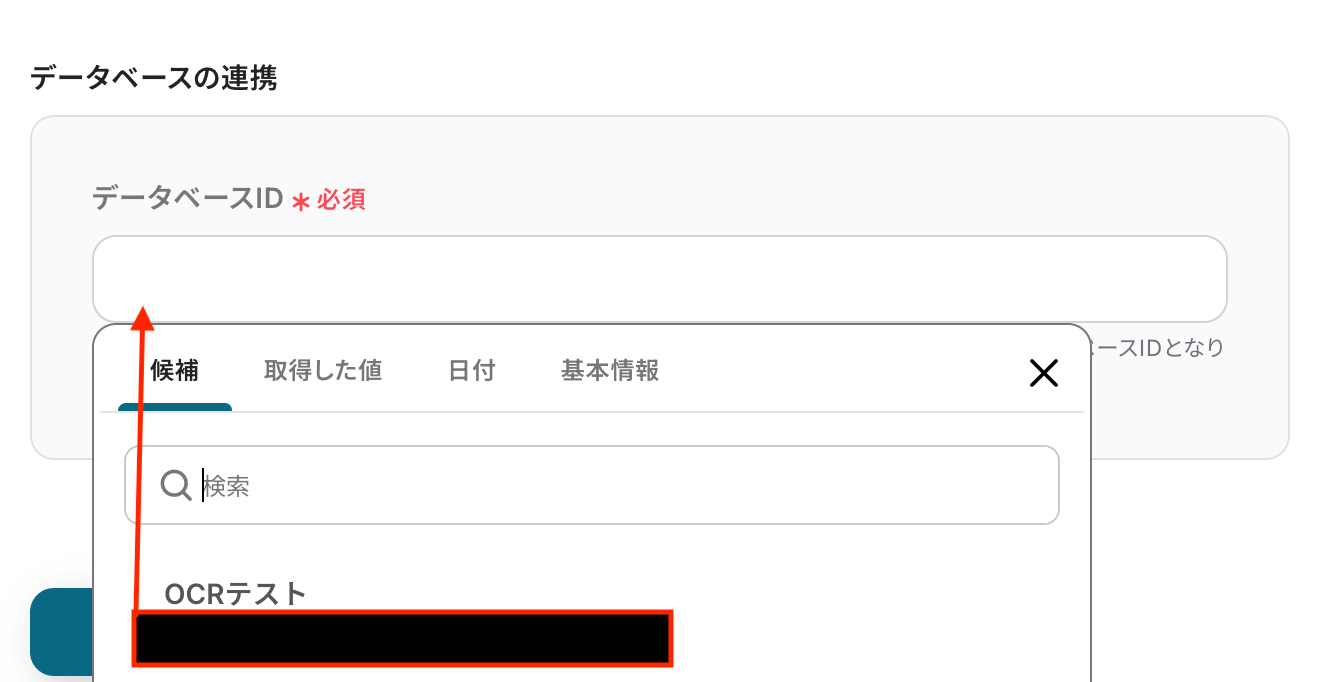
データベースID こちら
追加するレコードの値 なお、テキストを直接入力した部分は固定値とされるため、アウトプットを活用せず設定を行うと毎回同じ内容のレコードがNotionに追加されてしまうので注意が必要です。
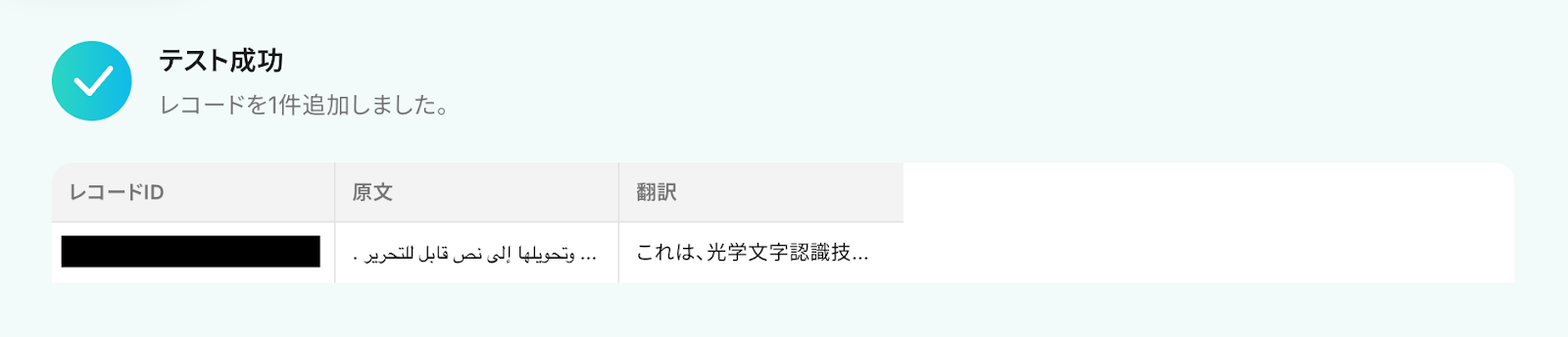
入力が完了したら「テスト」をクリックして、設定した内容でNotionにレコードが追加されるか確認しましょう。
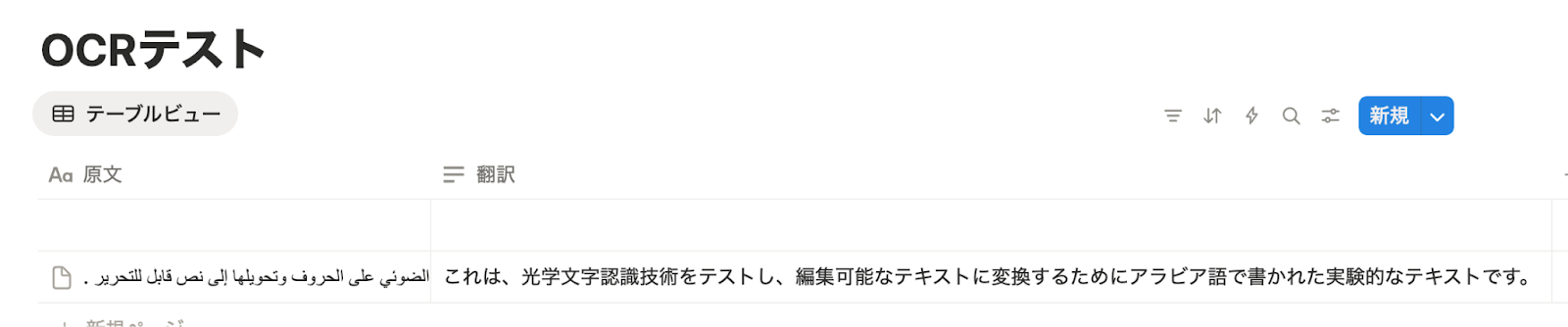
テストに成功すると、Notionに追加されたレコードの情報が表示されます。
あわせてNotionの画面を開き、指定した内容でレコードが実際に追加されているかを確認してみましょう。
問題がなければYoomの操作画面に戻り、「保存する」をクリックします。
ステップ6: トリガーをONにし、フローが起動するかを確認
設定が完了すると、画面上に以下のようなメニューが表示されます。
OCRを使ったその他の自動化例
OCRを活用することで、紙や画像の情報をデジタルデータ化し、管理や共有を効率化できます。
Google DriveにアップロードされたファイルをOCRして、Anthropic(Claude)で要約後、Gmailでメールを送信する
試してみる
■概要
Google Driveにアップロードされた請求書や議事録などを、都度ダウンロードして内容を確認し、要約を作成してメールで共有する作業は手間がかかるのではないでしょうか。このワークフローを活用すれば、Google Driveへのファイルアップロードをきっかけに、OCRによる文字情報の抽出からAnthropic(Claude)による要約、そしてGmailでのメール送信までの一連の業務を自動化し、これらの課題を解消します。
■このテンプレートをおすすめする方
Google Driveに保存したPDFなどのファイル内容の確認や共有に手間を感じている方 OCRで読み取ったテキストを手作業で要約し、メールに転記している方 複数のツールをまたぐ定型業務を自動化し、生産性を向上させたいと考えている方 ■このテンプレートを使うメリット
ファイルアップロードから情報抽出、要約、メール共有までが自動で実行されるため、手作業に費やしていた時間を他の業務に充てることができます。 手作業によるテキストの転記ミスや要約の抜け漏れ、メールの送信間違いといったヒューマンエラーのリスクを軽減します。 ■フローボットの流れ
はじめに、Google Drive、Anthropic(Claude)、GmailをYoomと連携します。 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します。 続いて、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知したファイルを指定します。 次に、オペレーションでOCRの「画像・PDFから文字を読み取る」アクションを設定し、ダウンロードしたファイルから文字情報を抽出します。 続いて、オペレーションでAnthropic(Claude)の「テキストを生成」アクションを設定し、OCRで抽出したテキストを要約します。 最後に、オペレーションでGmailの「メールを送る」アクションを設定し、生成された要約を本文に含めて指定の宛先に送信します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Google Driveのトリガー設定では、自動化の起点としたい監視対象のフォルダを任意で指定してください。 OCR機能では、画像やPDFファイルから抽出したい項目を、帳票の種類などに合わせて任意で設定することが可能です。 Anthropic(Claude)の設定では、OCRで抽出したテキストを変数として用い、要約や翻訳など、任意のプロンプト(指示)を実行できます。 Gmailでメールを送信するアクションでは、宛先(To, Cc, Bcc)や件名、本文を自由に設定でき、前工程で生成した要約などを変数として利用できます。 ■注意事項
Google DriveとAnthropic(Claude)とGmailのそれぞれとYoomを連携してください。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。
Gmailで受信したPDFをOCRで全文読み取り、Google スプレッドシートに追加する
試してみる
■概要
取引先からGmailに届く請求書や注文書などのPDFファイル。その都度ファイルを開き、内容を確認してGoogle スプレッドシートへ手入力する作業は、手間がかかる上に転記ミスも起こりがちです。このワークフローを活用すれば、Gmailで特定のPDF付きメールを受信するだけで、OCR機能が自動で文字情報を読み取り、Google スプレッドシートへデータを追加します。面倒な転記作業から解放され、業務の正確性と効率を向上させることが可能です。
■このテンプレートをおすすめする方
Gmailで受信するPDFの内容を手作業でGoogle スプレッドシートに転記している方 請求書や注文書の処理業務を自動化し、人的ミスをなくしたい経理・営業事務担当の方 定型的なデータ入力作業を効率化し、より重要な業務に集中したいと考えている方 ■このテンプレートを使うメリット
Gmailでのメール受信を起点に、PDFの文字抽出からデータ転記までが自動化され、これまで手作業に費やしていた時間を短縮することができます。 手作業での転記がなくなることで、入力間違いや記載漏れといったヒューマンエラーを防ぎ、データの正確性を維持することに繋がります。 ■フローボットの流れ
はじめに、GmailとGoogle スプレッドシートをYoomと連携します。 次に、トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します。 次に、オペレーションで分岐機能を設定し、メールにPDFファイルが添付されている場合のみ後続の処理に進むよう条件を設定します。 続いて、オペレーションでOCR機能の「画像・PDFから文字を読み取る」を設定し、添付されたPDFファイルからテキストデータを抽出します。 最後に、オペレーションでGoogle スプレッドシートの「レコードを追加する」を設定し、抽出したデータを指定のシートに追加します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Gmailのトリガー設定では、フローを起動させたいメールの件名や本文に含まれるキーワード(例:「請求書」)や、メールをチェックする間隔を任意で設定してください。 分岐機能では、後続の処理に進む条件(例:添付ファイルが存在する)を自由に設定できます。 OCR機能では、使用するAIエンジンや言語の選択、PDF内のどの項目を抽出するかなどを細かく指定することが可能です。 Google スプレッドシートにレコードを追加する設定では、出力先のファイルやシート、書き込むセルの範囲を自由に指定し、OCRで読み取ったどの値をどのセルに追加するかを設定できます。 ■注意事項
Gmail、Google スプレッドシートのそれぞれとYoomを連携してください。 分岐はミニプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 ミニプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。
Gmailの添付ファイルをOCRで読み取りTrelloに登録する
試してみる
■概要
Gmailに届く請求書や発注書などの添付ファイル、その都度内容を確認してTrelloへ手入力でタスク登録する作業に手間を感じていないでしょうか。こうした手作業は時間がかかるだけでなく、入力ミスなどのヒューマンエラーを引き起こす原因にもなります。このワークフローを活用すれば、Gmailで受信した特定の添付ファイルをOCR機能で自動でテキスト化し、その内容をTrelloカードとして登録できるため、一連の業務を円滑に進めることが可能です。
■このテンプレートをおすすめする方
Gmailで受信する請求書などの添付ファイルをTrelloで管理している方 手作業によるデータ転記やタスク登録の手間を削減したいと考えている方 タスク管理の初動を自動化し、対応漏れなどのミスをなくしたい方 ■このテンプレートを使うメリット
Gmailの添付ファイルを自動でOCR処理しTrelloに登録するため、これまで手作業で行っていたファイル確認やデータ転記の時間を短縮できます。 OCRで読み取ったテキストデータを活用してカードを作成するため、手入力による転記ミスやタスクの作成漏れといったヒューマンエラーを防ぎます。 ■フローボットの流れ
はじめに、GmailとTrelloをYoomと連携します。 次に、トリガーでGmailを選択し、「特定のラベルのメールを受信したら」というアクションを設定することで、処理対象のメールを絞り込みます。 続いて、オペレーションでOCR機能の「任意の画像やPDFを読み取る」アクションを設定し、受信したメールの添付ファイルをテキストデータに変換します。 最後に、オペレーションでTrelloの「新しいカードを作成」アクションを設定し、OCRで読み取ったテキスト情報をもとにカードを自動で作成します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
Trelloで新しいカードを作成するアクションでは、カードを追加したいボードIDやリストIDを任意で指定することが可能です。 作成するTrelloカードの説明欄には、前のステップであるOCR機能で読み取ったテキスト内容を変数として自動で埋め込めます。 ■注意事項
Trello、GmailのそれぞれとYoomを連携してください。 OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。プランによって最短の起動間隔が異なりますので、ご注意ください。
OneDriveにファイルがアップロードされたら、OCRで読み取りGmailで通知する
試してみる
■概要
OneDriveにアップロードされた請求書や領収書の内容を確認し、関係者にメールで通知する作業は、手間がかかる上に後回しにしてしまいがちではないでしょうか。
■このテンプレートをおすすめする方
OneDriveにアップロードされた書類の内容確認と通知を手作業で行っている方 書類内容の転記ミスや関係者への通知漏れなどのヒューマンエラーを防ぎたい方 OCR機能を活用して、紙媒体やPDFの情報を効率的にデータ化したいと考えている方 ■このテンプレートを使うメリット
OneDriveへのファイルアップロードから内容の読み取り、Gmailでの通知までが自動化され、これまで手作業で行っていた時間を短縮できます。 手作業での確認や情報転記が不要になるため、読み取り間違いや通知漏れといったヒューマンエラーの発生を防ぐことに繋がります。 ■フローボットの流れ
はじめに、OneDriveとGmailをYoomと連携します。 トリガーでOneDriveを選択し、「特定フォルダ内にファイルが作成または更新されたら」アクションを設定して対象のフォルダを指定します。 オペレーションで「分岐する」アクションを追加し、特定のファイル形式のみ処理を進めるなど、任意の条件を設定します。 次に、OneDriveの「ファイルをダウンロード」アクションを設定し、トリガーで取得したファイルを指定します。 続けて、OCR機能の「任意の画像やPDFを読み取る」アクションを設定し、ダウンロードしたファイルからテキストを抽出します。 最後に、Gmailの「メールを送る」アクションを設定し、抽出したテキスト情報を含んだメールを自動で送信します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
OneDriveの「ファイルをダウンロード」アクションでは、トリガーで取得したファイルのIDを設定してください。 分岐機能では、業務に合わせた条件を自由に設定可能です。 OCR機能で読み取る項目は、書類の中から会社名や金額など、必要な情報だけを任意に指定して抽出することができます。 Gmailで送信するメールの件名や本文、宛先は、OCRで読み取った情報などを活用して自由にカスタマイズしてください。 ■注意事項
OneDrive、GmailのそれぞれとYoomを連携してください。 Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。 分岐するオペレーションはミニプラン以上、OCRのAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。 ミニプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。 トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。 プランによって最短の起動間隔が異なりますので、ご注意ください。 ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。 トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は下記をご参照ください。https://intercom.help/yoom/ja/articles/9413924 アプリの仕様上、ファイルの作成日時と最終更新日時が同一にならない場合があり、正しく分岐しない可能性があるのでご了承ください。 OCRデータは6,500文字以上のデータや文字が小さい場合などは読み取れない場合があるので、ご注意ください。
Gmailの添付ファイルをOCRで読み取り、Boxに自動保存する
試してみる
■概要
取引先からGmailで届く請求書や発注書を手作業でダウンロードし、Boxに保存していませんか。この作業は時間がかかる上に、ファイルの保存漏れや命名ミスといったヒューマンエラーの原因にもなりがちです。このワークフローを活用すれば、特定のGmailで受信した添付ファイルをAIが自動でOCR処理し、内容に応じたファイル名でBoxへ保存するため、こうした定型業務を正確かつ効率的に自動化できます。
■このテンプレートをおすすめする方
Gmailで受信する請求書などを手作業でBoxに保存している経理・営業事務担当者の方 取引先からの添付ファイルをBoxで管理しており、一連の業務を効率化したいと考えている方 手作業によるファイルの保存漏れや、ファイル名の付け間違いといったミスを防ぎたい方 ■このテンプレートを使うメリット
Gmailの添付ファイルダウンロードからBoxへのアップロードまでを自動化できるため、これまで手作業に費やしていた時間を短縮できます。 人の手による作業を介さないため、ファイルの保存漏れやファイル名の入力ミスといったヒューマンエラーの発生を防ぎ、正確な管理を実現します。 ■フローボットの流れ
はじめに、GmailとBoxをYoomと連携します。 トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します。 オペレーションでGmailの添付ファイルをダウンロードするアクションを設定し、トリガーで受信したメールの添付ファイルを取得します。 オペレーションでAI機能の「画像・PDFから文字を読み取る」を設定し、ダウンロードしたファイルからテキスト情報を抽出します。 オペレーションでAI機能の「テキストを生成する」を設定し、抽出した情報(請求書番号や日付など)を元に任意のファイル名を生成します。 最後に、オペレーションでBoxの「ファイルをアップロードする」を設定し、生成したファイル名で指定のフォルダにファイルを保存します。 ※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
このワークフローで利用するOCR機能(画像・PDFから文字を読み取る)は、チームプランまたはサクセスプランでご利用いただける機能です。フリープランやミニプランではエラーとなるためご注意ください。 チームプランやサクセスプランなどの有料プランで利用できる機能は、2週間の無料トライアル期間中にお試しいただくことが可能です。
まとめ
アラビア語のファイルをOCRで自動的にテキスト化することで、これまで手作業で行っていたデータ入力の手間を削減し、転記ミスなどのヒューマンエラーを防ぐことができます。
これにより、担当者は面倒な文字起こし作業から解放され、抽出したデータを分析・活用するといった、より付加価値の高い業務に集中できる環境が整います!
今回ご紹介したような業務自動化を実現できるノーコードツール「Yoom」を使えば、プログラミングの知識がない方でも、直感的な操作で簡単に業務フローを構築できます。ぜひ こちら から無料登録 して、Yoomによる業務効率化を体験してみてください!
よくあるご質問
Q:読み取りと同時に翻訳も可能ですか?
A:はい、OCRによる読み取りの段階でも翻訳を同時に行うことができます。
今回の記事のように日本語へ翻訳したい場合は、抽出項目に「(Translate to Japanese)」と指示を入れるだけで、読み取りと翻訳が一度に実行されます。
「翻訳」の設定方法はこちら
Q:アラビア語OCRの読み取り精度は?
A:PDFや画像から高い精度で文字を抽出できますが、ファイルの内容や形式によって結果が変わります。
詳しくはこちら
Q:Notion以外に転記する方法はありますか?
A:はい、今回ご紹介したNotion以外にも、さまざまな活用が可能です。
例えば、OCRで読み取った請求書データをfreee会計やkintoneといった会計・業務システムに自動登録したり、内容をAIで要約してSlackやMicrosoft Teamsへ通知したりすることも可能です。
フローボットの基本的な操作方法については、こちら