








・
Perplexityの著作権侵害リスクとは?商用利用の注意点とおすすめの活用法

近年、高精度なリサーチツールとして世界中で注目を集めているAI検索エンジンPerplexity。情報源のリンクが明示されるため事実確認がしやすく、日々の業務や情報収集に活用している方も多いのではないでしょうか。しかしその一方で、大手メディアから記事の無断学習に対する提訴や抗議が相次ぐなど、著作権侵害のリスクが懸念されています。
本記事では、Perplexityをビジネスやコンテンツ制作で利用する際の著作権をめぐる現状と、商用利用時の注意点について詳しく解説します。さらに、実際にツールを使って検証した結果をもとに、安全かつ効果的なおすすめの活用方法もご紹介しますので、ぜひ日々の業務にお役立てください。
✍️検証の前に:Perplexityの基本情報・料金をチェック

まずは、Perplexityがどのようなサービスなのか、その基本情報を整理しておきましょう。
本記事の想定読者
- Perplexityを日々の業務や情報収集で活用したいと考えているビジネスパーソン
- コンテンツ制作に携わるクリエイターの方
- 生成AIを利用する際に懸念される著作権侵害のリスクについて正しく理解し、安全にツールを活用したい方
Perplexityとは?
Perplexityは、ユーザーの入力した質問に対して、インターネット上の情報をリアルタイムで検索し、それを要約して回答を出力する対話型のAI検索エンジン(アンサーエンジン)です。
一般的な検索エンジンがWebサイトのリンクを一覧で表示するのに対し、Perplexityは複数のサイトから情報を集めて一つのまとまった回答を生成してくれます。最大の特徴は、回答の根拠となった情報源(ソース)のリンクが必ず提示される点にあり、事実確認(ファクトチェック)が非常に容易なため、精度の高いリサーチツールとして世界中で注目を集めています。
Perplexityの料金プラン
- 無料プラン(Standard):基本的なAI検索機能が無料で利用可能です。
-
Proプラン:月額20ドル
より高度なAIモデル(GPT-4やClaude 3 、Geminiなど)の選択、ファイルアップロード機能の強化、1日最大600回のPro検索など、プロフェッショナルな用途に耐えうる機能が解放されます。 -
Enterprise Proプラン:月額40ドル/ユーザー
企業向けのカスタマイズ可能なプランで、無制限のプロ検索が利用可能なほか、シングルサインオン(SSO)対応、データプライバシーの強化や高度なセキュリティ機能が解放されます。 - APIプラン:
開発者向けのプランで、用途に応じて2種類の課金体系があります。
・Search API(検索結果のみ): 1,000リクエストあたり5ドル(トークン料金なし)
・Sonarモデル(AI回答生成): 検索手数料(1,000リクエストあたり5ドル〜)+トークン従量課金
・入力トークン100万あたり2ドル
・出力トークン100万あたり8ドル
※Proプランユーザーには毎月5ドル分のAPIクレジットが付与されます。
📣YoomはPerplexityを活用したリサーチ業務を自動化できます
Yoomは、プログラミングの知識がなくても業務フローを自動化できるノーコードツールです。[Yoomとは]
たとえば、Telegramで投稿されたキーワードをもとにAIがPerplexityでリサーチを行い、有益な情報だけを抽出して自動で通知することができます。
また、Googleスプレッドシートに追加されたデータをもとに、OpenAIやPerplexityを活用してブランドの可視性を分析し、その結果を自動で反映することも可能です。
このように、情報収集から分析・整理までの一連の作業を効率化することで、日々の業務負担を減らしながら質の高いアウトプットを実現することが期待できます。
以下のような自動化が可能です。
- PerplexityとTelegramを活用した情報収集プロセスを自動化したい方
- AIワーカーにリサーチ情報の有益性を自律的に判定させ、業務を効率化したい方
- 手作業での情報収集と要約作成に時間がかかり、本来の業務に集中できない方
- Telegramへのキーワード投稿を起点にリサーチから要約、通知までが自動処理されるため、情報収集にかかる作業時間を短縮できます。
- AIワーカーが設定された基準で情報を処理するため、人による判断のばらつきや見落としを防ぎ、リサーチ品質の均一化が図れます。
- はじめに、PerplexityとTelegramをYoomと連携します。
- 次に、トリガーでTelegramの「ボットがメッセージを受け取ったら」を選択し、リサーチしたいキーワードの受信を検知できるように設定します。
- 最後に、オペレーションでAIワーカーを設定し、Perplexityでのリサーチから有益性などの判定、要約、通知を行うためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- AIワーカーでは、情報の有益性判定や要約に使用するAIモデルを選択し、どのような基準で判定・要約を行うか、具体的な指示を任意で設定してください。
- Perplexityの情報検索のモデルやプロンプト、Telegramの送信先チャットなども自由にカスタマイズできます。
- Telegram、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
- Google スプレッドシートでキーワードを管理し、手作業でブランドの可視性を分析しているマーケティング担当者の方
- OpenAIやPerplexityなどの生成AIを活用した情報収集や分析業務を効率化したいと考えている方
- AIワーカーを利用して、分析結果をGoogle スプレッドシートに自動で反映し、データ管理を円滑にしたい方
- Google スプレッドシートへの行追加を起点に、一連の分析から結果の反映までを自動化するため、手作業での情報収集や転記にかかる時間を短縮できます
- 手動での分析やコピー&ペーストによる入力ミス、確認漏れといったヒューマンエラーを防ぎ、常に一定の品質で分析業務を実行することが可能です
- はじめに、Google スプレッドシート、OpenAI、PerplexityをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、OpenAIやPerplexityを利用してブランドの可視性を分析し、改善案を生成して記録するためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー設定では、分析対象の情報を管理している任意のスプレッドシートIDと、対象のシート名(タブ名)を指定してください
- AIワーカーのオペレーションでは、分析に利用したい任意のAIモデルを選択し、ブランド可視性を分析・評価するための具体的な指示内容を業務に合わせて設定してください
- Google スプレッドシート、OpenAI、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- ChatGPT(OpenAI)のアクションを実行するには、OpenAIのAPI有料プランの契約が必要です。(APIが使用されたときに支払いができる状態)
- OpenAIのAPIはAPI疎通時のトークンにより従量課金される仕組みとなっています。そのため、API使用時にお支払いが行える状況でない場合エラーが発生しますのでご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
⚠️Perplexityの著作権をめぐる現状とリスク
Perplexityをビジネスで活用するうえで、まず理解しておきたいのが著作権をめぐる現状です。近年は生成AIによる情報収集や要約の仕組みが広く利用される一方で、その裏側にある学習データの扱いや、既存コンテンツとの関係について懸念の声も高まっています。ここでは、国内外の動向をもとに、Perplexityを取り巻く著作権リスクの実態を整理します。
報道機関やメディアからの提訴・抗議
近年、生成AIによるWebコンテンツの無断利用が世界的な議論を呼んでおり、Perplexityも例外ではありません。国内外のメディア企業が、著作権侵害や利益の毀損を理由に相次いで法的措置や抗議を行っています。
〈日本国内における主な動き(2025年8月)〉
- 日本経済新聞・朝日新聞:
2025年8月26日に国内メディアとして初めて共同提訴。 -
読売新聞:
2025年8月7日に国内メディアとして初めて提訴。約21.7億円の損害賠償を請求。 -
共同通信・毎日新聞・産経新聞:
記事の無断学習や、情報元としての虚偽表示に関して一斉に抗議。
〈海外における主な動き〉
-
大手メディアの提訴:
The New York Times、Chicago Tribune、Britannica といったパブリッシャーが、自社の著作物を違法にコピーし配信しているとしてPerplexityを相次いで提訴。
これらの動きは、AIがインターネット上の情報を収集・要約してユーザーに直接回答を提供する仕組みが、元のコンテンツ制作者である報道機関やパブリッシャーの利益を損なっているという懸念から生じており、AIと著作権のあり方を問う重要な転換点となっています。
ユーザー生成コンテンツの著作権の扱いと商用利用
Perplexityのような生成AIを利用して出力されたコンテンツの著作権の扱いについては、ユーザー側も十分に理解しておく必要があります。
〈著作権の発生に関する原則〉
-
創作的寄与の欠如:
一般的に、ユーザーが簡単なプロンプト(指示語)を入力してAIに生成させた文章には、「人間による創作的な寄与」が認められません。 -
権利主張の困難さ:
原則として著作権は発生しないと考えられています。そのため、AIの回答はフリー素材に近い扱いとなり、他人にコピーされても著作権侵害を主張することは困難です。
〈商用利用時の侵害リスク〉
-
既存著作物への酷似:
AIが生成した回答が、学習元の既存の著作物(Web記事やニュースなど)に酷似している場合があります。 -
利用者の責任:
酷似した内容を自身のブログや企業サイトでそのまま公開・商用利用すると、ユーザー自身が著作権侵害の責任を問われる可能性があります。
AIは非常に便利なツールですが、出力された内容をそのまま転載するのではなく、参考情報として扱い、最終的には必ず自分自身の言葉で書き直すなどの対策を講じることが強く推奨されます。
🤔Perplexityでリサーチ業務を検証してみた
著作権侵害のリスクを避けてPerplexityを安全に活用するため、実際のリサーチ業務を想定した検証を行いました。
検証内容
今回は、以下のような検証をしてみました!
検証:著作権リスク回避と回答精度の実証検証
〈検証項目〉
以下の項目で、検証していきます!

検証目的
本検証は、ビジネスリサーチにおけるPerplexity活用の安全性と信頼性を評価することを目的としています。「生成AIと著作権」という法的専門性の高いテーマを用い、国内動向や法解釈の要約を指示した際、出力内容が参照元の一次情報と正確に一致しているか、法的根拠や最新事例を漏れなく網羅できているか、そして既存記事の安易な翻案(デッドコピー)を避け著作権侵害リスクを排除した独自の要約がなされているかを多角的に分析し、実務における安全な活用基準を策定します。
使用モデル
Perplexity(無料プラン)
🔍検証:著作権リスク回避と回答精度の実証検証
ここからは、実際に検証した内容とその手順を解説します。
まずは実際の検証手順のあとに、それぞれの検証項目について紹介していきます!
検証方法
本検証では、プロンプトを使用してPerplexityにリサーチさせ、安全性と信頼性を確認します。
プロンプト:
生成AIの著作権に関する日本の最新動向と法的な解釈を要約し、必ず情報源(ソース)のリンクを提示してください。
想定シーン
クライアントに提出するレポート作成において、最新の法規制(著作権動向など)を引用する必要がある場面。
検証手順
こちらの画面が表示されるので、プロンプトを入力したら送信します。
1分以内(20秒ほど)で完了しました!
結果は以下のものとなりました。(結果が、非常に長文のため一部抜粋しています)

🖊️検証結果
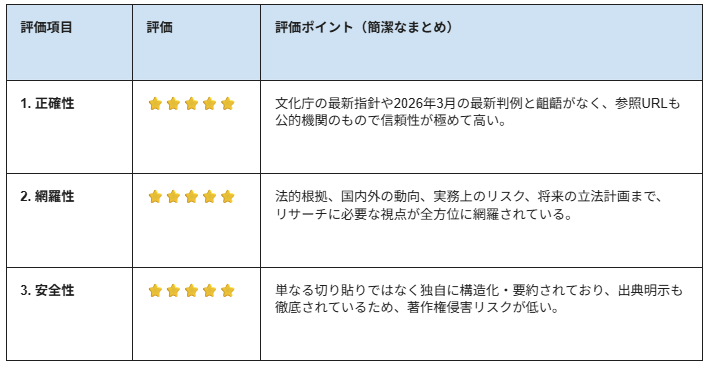
実際に、検証を行った結果を画像とともにまとめています。
※本評価は、多数のAIツールを実務に導入してきた著者の知見に基づき、実用性の観点から相対的に算出したものです。
1.正確性
提示されたソース(文化庁、国立国会図書館、情報処理学会等)の内容と出力結果を照らし合わせた結果、かなり高い正確性が確認できました。
-
事実関係の一致:
文化庁の「AIと著作権に関する考え方について(2024年3月)」や、著作権法30条の4の解釈など、公的機関の発表に基づいた正確な記述がなされています。 -
直近の情報の反映:
2026年3月の東京地裁による著作権侵害の認定報告(直近の司法動向をキャッチアップできている例として)など、検証時点(2026年3月)での新しいニュースを正確にキャッチアップしています。 -
リンクの有効性:
提示されたURLはすべて内容に関連する適切なドメイン(.go.jp, .or.jp等)であり、情報の裏付けが容易です。
単なる情報の羅列ではなく、「学習」と「生成・利用」のフェーズを分けて整理している点も、法的な論点整理として正確であり、実務レベルで信頼に足る内容と評価できます。
2.網羅性
リサーチ業務に求められる「多角的な視点」と「法理から実務までの階層構造」が十分に網羅されています。
-
法理的根拠:
著作権法30条の4(権利制限規定)といった具体的な条文への言及。 -
行政・司法の動向:
文化庁のガイドラインから、下級審レベルでの裁判例、さらには既に施行されている「AI基本法(人工知能関連技術の研究開発及び活用の推進に関する法律)」などの現行法規まで網羅。 -
具体的リスクの提示:
特定クリエイターの作風模倣や「意図的な模倣」が違法となり得る実務的な境界線が示されています。 -
海外動向との対比:
米国の判断基準(創作性の必要性)に触れつつ、日本のスタンスを解説。
情報の抜け漏れが少なく、この回答一つで「現状の全体像」を把握できるレベルに達しています。フォローアップ質問の提案内容も、さらに深掘りすべき論点を的確に示しており、網羅性を補完しています。
3.安全性
既存のWeb記事の切り貼り(デッドコピー)ではなく、AIによる独自の構造化と要約が行われており、著作権侵害のリスクは低いと判断できます。
-
独自構成の構築:
複数のソースから情報を抽出し、「政府の整理」「学習データ」「生成物のリスク」「判例」「今後の方向性」と独自に章立てして再構成されています。 -
表現の抽象化・整理:
専門的な法文や長いニュース記事をそのまま転載せず、箇条書きを用いて「実務上のざっくり整理」としてエッセンスを抽出しており、翻案(独自のまとめ)として機能しています。 -
適切な出典表示:
記述の随所にソースのインライン引用(current.ndl等)が付与されており、どの情報がどこに由来するかを明示することで、不適切な無断転用を避ける配慮が見られます。
出力内容がそのまま「自社の独自レポート」として活用可能なレベルのオリジナリティを持っており、ビジネス利用における安全性が確認できました。
✅まとめ

Perplexityは、入力した質問に対して的確な回答を生成し、その出典元のリンクを明示してくれるため、高度なリサーチや情報収集において非常に優れたツールです。しかし、AIが学習し生成した文章をそのままブログ等で公開したり商用利用したりすると、既存のコンテンツ制作者に対する著作権侵害のリスクを伴う可能性があります。また、簡単な指示で生成された文章自体には著作権が認められないケースがほとんどです。
そのため、生成されたコンテンツはそのまま流用するのではなく、あくまで「構成案の作成補助」や「一次情報へ辿り着くための検索ツール」として活用し、最終的なアウトプットは自身の言葉と責任で作成することが、安全かつ賢明な使い方と言えるでしょう。
💡Yoomでできること
Yoomを導入することで、PerplexityなどのAIツールを使ったリサーチ業務や、それに関連する情報整理のプロセスをさらに効率化し、日々の業務負担を大きく軽減することができます。
たとえば、定期的に特定のキーワードに関する市場調査や競合調査を行う場合、Yoomを使ってスケジュールトリガーを設定し、自動でAIにリサーチを実行させることが可能です。収集されたリサーチ結果は、Yoomを介して指定したGoogle スプレッドシートやNotionのデータベースに自動で蓄積されたり、SlackやChatworkといったコミュニケーションツールに通知されたりします。
これにより、担当者が毎回手作業で検索し、結果をコピー&ペーストして資料にまとめるという単純作業から解放されます。
■概要日々の業務における情報収集では、関連情報をリサーチし、その中から有益な情報を見極めて要約するといった手間のかかる作業が発生します。 このワークフローを活用すれば、Telegramでキーワードを受け取ったらAIワーカーが Perplexityでリサーチを行い、さらに 情報の有益性を自律的に判定して要約・通知するまでの一連のプロセスを自動化し、情報収集業務の効率化を実現します。■このテンプレートをおすすめする方- PerplexityとTelegramを活用した情報収集プロセスを自動化したい方
- AIワーカーにリサーチ情報の有益性を自律的に判定させ、業務を効率化したい方
- 手作業での情報収集と要約作成に時間がかかり、本来の業務に集中できない方
■このテンプレートを使うメリット- Telegramへのキーワード投稿を起点にリサーチから要約、通知までが自動処理されるため、情報収集にかかる作業時間を短縮できます。
- AIワーカーが設定された基準で情報を処理するため、人による判断のばらつきや見落としを防ぎ、リサーチ品質の均一化が図れます。
■フローボットの流れ- はじめに、PerplexityとTelegramをYoomと連携します。
- 次に、トリガーでTelegramの「ボットがメッセージを受け取ったら」を選択し、リサーチしたいキーワードの受信を検知できるように設定します。
- 最後に、オペレーションでAIワーカーを設定し、Perplexityでのリサーチから有益性などの判定、要約、通知を行うためのマニュアル(指示)を作成します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- AIワーカーでは、情報の有益性判定や要約に使用するAIモデルを選択し、どのような基準で判定・要約を行うか、具体的な指示を任意で設定してください。
- Perplexityの情報検索のモデルやプロンプト、Telegramの送信先チャットなども自由にカスタマイズできます。
■注意事項- Telegram、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
■概要競合他社の価格情報を定期的にチェックし、レポートを作成する業務は重要ですが、手作業では多くの時間と手間がかかってしまうのではないでしょうか。 このワークフローを活用すれば、Perplexityによる競合価格の調査からレポート作成までを自動化し、定めたスケジュールでOutlookに通知できます。手作業による情報収集の手間を減らし、効率的に市場の動向を把握することが可能になります。■このテンプレートをおすすめする方- Perplexityを使い、手動で競合の価格情報を収集しているマーケティング担当者の方
- 競合価格に関する定期的なレポート作成を自動化し、業務を効率化したい方
- 競合調査の結果を自動でチームに共有し、情報共有を円滑にしたいマネージャーの方
■このテンプレートを使うメリット- Perplexityでの情報検索からレポート生成までの一連の流れが自動化されるため、これまで手作業に費やしていた情報収集の時間を削減できます。
- 定期的な情報収集を自動化することで、検索漏れやレポート作成時の転記ミスといった人為的なエラーを防ぎ、情報の正確性を高めることに繋がります。
■フローボットの流れ- はじめに、PerplexityとOutlookをYoomと連携します。
- 次に、トリガーで「スケジュールトリガー」を選択し、このワークフローを起動したい日時や頻度を設定します。
- 次に、オペレーションでPerplexityの「情報を検索」アクションを選択し、競合の価格情報を収集するための検索クエリを設定します。
- 続いて、Perplexityの「テキストを生成」アクションを設定し、検索で得た情報を基にレポートを作成するよう指示します。
- 最後に、Outlookの「メールを送る」アクションを設定し、生成されたレポートを指定の宛先に送信します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- スケジュールトリガーでは、日次、週次、月次など、レポートを取得したい頻度や実行したい時間帯を任意で設定してください。
- Perplexityの各アクションでは、調査したい競合名や製品名といった検索内容や、レポートの要約形式などの指示内容を任意で設定してください。
- Outlookの「メールを送る」オペレーションでは、レポートを通知したい宛先(To, Cc, Bcc)やメールの件名、本文を任意で設定してください。
■注意事項- PerplexityとOutlookのそれぞれとYoomを連携してください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- PerplexityとTelegramを活用した情報収集プロセスを自動化したい方
- AIワーカーにリサーチ情報の有益性を自律的に判定させ、業務を効率化したい方
- 手作業での情報収集と要約作成に時間がかかり、本来の業務に集中できない方
- Telegramへのキーワード投稿を起点にリサーチから要約、通知までが自動処理されるため、情報収集にかかる作業時間を短縮できます。
- AIワーカーが設定された基準で情報を処理するため、人による判断のばらつきや見落としを防ぎ、リサーチ品質の均一化が図れます。
- はじめに、PerplexityとTelegramをYoomと連携します。
- 次に、トリガーでTelegramの「ボットがメッセージを受け取ったら」を選択し、リサーチしたいキーワードの受信を検知できるように設定します。
- 最後に、オペレーションでAIワーカーを設定し、Perplexityでのリサーチから有益性などの判定、要約、通知を行うためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- AIワーカーでは、情報の有益性判定や要約に使用するAIモデルを選択し、どのような基準で判定・要約を行うか、具体的な指示を任意で設定してください。
- Perplexityの情報検索のモデルやプロンプト、Telegramの送信先チャットなども自由にカスタマイズできます。
- Telegram、PerplexityのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカーで大容量のデータを処理する場合、処理件数に応じて膨大なタスクを消費する可能性があるためご注意ください。
- Perplexityを使い、手動で競合の価格情報を収集しているマーケティング担当者の方
- 競合価格に関する定期的なレポート作成を自動化し、業務を効率化したい方
- 競合調査の結果を自動でチームに共有し、情報共有を円滑にしたいマネージャーの方
- Perplexityでの情報検索からレポート生成までの一連の流れが自動化されるため、これまで手作業に費やしていた情報収集の時間を削減できます。
- 定期的な情報収集を自動化することで、検索漏れやレポート作成時の転記ミスといった人為的なエラーを防ぎ、情報の正確性を高めることに繋がります。
- はじめに、PerplexityとOutlookをYoomと連携します。
- 次に、トリガーで「スケジュールトリガー」を選択し、このワークフローを起動したい日時や頻度を設定します。
- 次に、オペレーションでPerplexityの「情報を検索」アクションを選択し、競合の価格情報を収集するための検索クエリを設定します。
- 続いて、Perplexityの「テキストを生成」アクションを設定し、検索で得た情報を基にレポートを作成するよう指示します。
- 最後に、Outlookの「メールを送る」アクションを設定し、生成されたレポートを指定の宛先に送信します。
■このワークフローのカスタムポイント
- スケジュールトリガーでは、日次、週次、月次など、レポートを取得したい頻度や実行したい時間帯を任意で設定してください。
- Perplexityの各アクションでは、調査したい競合名や製品名といった検索内容や、レポートの要約形式などの指示内容を任意で設定してください。
- Outlookの「メールを送る」オペレーションでは、レポートを通知したい宛先(To, Cc, Bcc)やメールの件名、本文を任意で設定してください。
- PerplexityとOutlookのそれぞれとYoomを連携してください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
【出典】
Perplexity料金プラン
プログラミング知識なしで手軽に構築できます。







