・
DifyでRAG構築|社内規程ボットを例にチャンク設定の違いを実務検証

RAGを構築したくても、専門知識がないと導入のハードルが高くなります。そこで解決策の1つとなるのがノーコードで設定できるDify(ディフィー)です。本記事では、DifyにおけるRAGの基本情報から、検索精度を向上させるための具体的な設定項目、活用できるユースケースまでを詳しく解説します。また、実際にRAGを構築し、チャンク長を変えたときの検証結果も紹介するので、ぜひ参考にしてみてください。
📖DifyにおけるRAGの基本概念と仕組み
DifyでのRAG構築を成功させるためには、まずRAGがどのような仕組みで動いているのかを根本から理解することが不可欠です。ここでは、LLM単体で発生する課題をRAGがどう解決するのか、そしてDifyを活用してシステムを構築するメリットやよくある課題について解説します。
RAG(検索拡張生成)とは何か?LLM単体との違いと必要性
RAG(Retrieval-Augmented Generation)は、外部の知識ベースから関連情報を検索し、その情報を基にLLMが回答を生成する仕組みです。LLM単体では学習データに含まれない最新情報や社内特有の情報を回答できず、事実に基づかない回答(ハルシネーション)を引き起こすリスクがあります。RAGを導入することで、常に最新かつ正確な社内情報に基づいた回答が可能になります。
LLM単体とRAGの主な違いは以下の通りです。

DifyでRAGを使うメリット(ノーコード構築・強力なワークフロー)
Difyを利用する最大の魅力は、高度なRAGシステムを専門的なコーディングなしで直感的に構築できる点にあります。複雑なプログラミング言語を習得していなくても、画面上の操作だけでデータソースの連携やチャットボットの公開が可能です。
Difyを活用するメリットとして、主に以下の3点があげられます。
- ノーコードでの直感的なUI操作:
ファイルのアップロードからテキストの分割処理、チャットボットの作成に至るまで、すべての工程をブラウザ上のGUI画面で完結させることができます。 - 豊富なデータソースとの連携機能:
PDFやCSVなどのローカルファイルだけでなく、Notionアカウントとの直接同期やWebスクレイピングツールを用いた動的なデータ収集に標準で対応しています。 - ワークフローによる拡張性の高さ:
単なる一問一答のボットにとどまらず、ユーザーの入力内容に応じて異なるナレッジベースを参照したり、外部APIと連携したりする高度なフローを構築できます。
🤖Yoomは問い合わせ対応以外も自動化できます
DifyでRAGを構築することで一部の問い合わせ作業を効率化できます。それでも、業務全体ではデータベースで顧客やタスクを管理したり、期限を確認したり、書類を作成したりといった作業が残ることがあり、時間に追われる環境を変えることは難しいのではないでしょうか。
Yoomは、さまざまな生成AIやDifyをはじめとするSaaSツールをノーコードで連携できるため、問い合わせ以外の業務フローも自動化できます。これには、以下のようなメリットがあります。
- データベースのステータスを更新するだけで付随する業務が自動で完了
- ヒューマンエラーを削減しながら1案件にかかる時間を短縮
導入により月間320時間の工数を削減している企業もあります。
[Yoomとは]
直感的な設定だけで柔軟なフローを構築できるため、自社に合わせたカスタマイズもノーコードでできます。無料プランや以下のようなテンプレートも豊富に用意されており、気軽に試すことができるので、自動化による新しい働き方をぜひ体験してみてください。
- Slackでの社内問い合わせ対応に多くの時間を割かれている情報システムや総務担当者の方
- AIワーカーを導入して、社内問い合わせ対応の効率化を検討しているDX推進担当者の方
- ナレッジを有効活用し、属人化しがちな問い合わせ業務の標準化を目指している方
- Slackへの投稿をトリガーにAIワーカーが回答案を自動で作成するため、社内問い合わせ対応にかかる工数を削減し、コア業務に集中できます。
- Googleドキュメントのナレッジを基に回答が生成されるため、担当者による回答の質のばらつきを防ぎ、業務の標準化と属人化の解消に繋がります。
- はじめに、GoogleドキュメントとSlackをYoomと連携します。
- 次に、トリガーでSlackを選択し、「メッセージがチャンネルに投稿されたら(Webhook)」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、投稿された問い合わせ内容とGoogleドキュメントのナレッジを基に回答を作成するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Slackのトリガー設定では、問い合わせを受け付ける対象のチャンネルを任意で設定してください。
- AIワーカーの設定では、利用したいAIモデルを任意で選択できます。また、問い合わせ内容の分類方法や回答のトーンなど、具体的な指示(プロンプト)を任意で設定してください。
- Slack、GoogleドキュメントのそれぞれとYoomを連携してください。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
■このテンプレートをおすすめする方
- kintoneで案件管理を行っており、提案書作成の初動をよりスムーズに進めたい営業担当者の方
- 商談メモからの課題抽出や提案構成案の作成に時間がかかり、効率化を検討しているチームリーダーの方
- 営業組織全体の提案品質の底上げと、属人化の解消を目指している経営層や営業推進担当の方
■このテンプレートを使うメリット
- kintoneのステータス更新に伴い、AIワーカーが商談メモを分析して提案書構成を自動作成するため、作成にかかる工数を削減し、質の高い提案準備をスムーズに開始できます。
- 作成された提案書ドラフトのURLがkintoneに自動保存され、Slackで通知されるため、情報の一貫性が保たれ、チーム内でのスムーズな情報共有が実現します。
■フローボットの流れ
- はじめに、kintone、Googleドキュメント、Slack、Google スプレッドシート、Google DriveをYoomと連携します。
- 次に、トリガーで、kintoneを選択し、「指定のステータスに更新されたら(Webhook起動)」というアクションを設定します。
- 次に、AIワーカーで、顧客の真の課題特定と最適な提案書の構成案を作成するためのマニュアルを作成(指示)をします。
■このワークフローのカスタムポイント
- kintoneのトリガー設定では、提案フェーズへの移行を検知できるよう、対象とするプロセス管理のステータス名を正確に設定してください。
- AIワーカーへの指示(プロンプト)を調整することで、自社の商材特性や特定の提案フォーマットに合わせた、より精度の高い構成案を作成することが可能です。
- Googleドキュメントの作成設定では、ファイル名の命名規則を任意で設定し、管理しやすい形式にカスタマイズすることも可能です。
■注意事項
- kintone、Google スプレッドシート、Googleドキュメント、Slack、Google DriveのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
🛠️DifyでのRAGアプリ構築手順
ここからは、実際にDifyの画面を操作してRAGアプリを構築していく具体的な手順を解説します。データソースの準備から知識パイプラインの構築、そしてチャットボットとしての動作確認まで、一連のステップを順番に確認していきましょう。
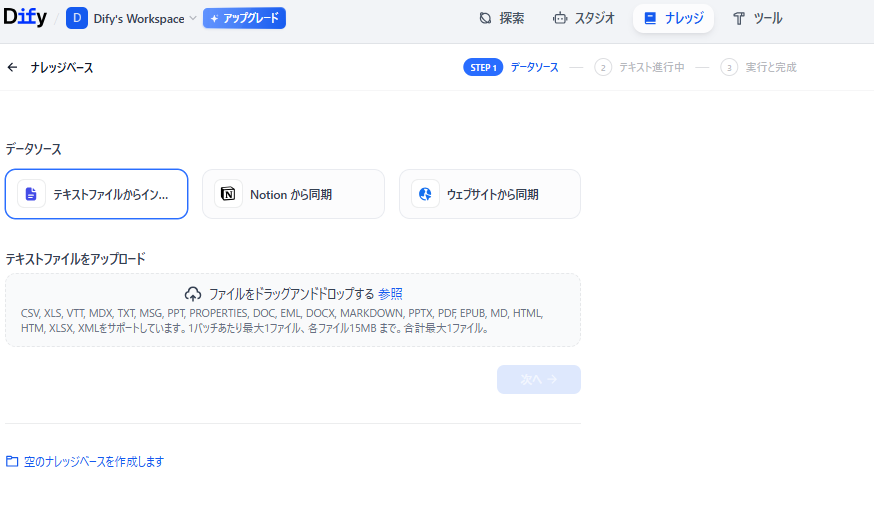
ナレッジベース(データソース)の作成
ナレッジベースは、DifyのRAGが参照する知識の源泉であり、正確な回答を生成するための最も重要な土台となります。用意するデータの品質が高ければ高いほど、最終的なチャットボットの回答精度も向上します。Difyでは多様なデータソースをサポートしており、用途に応じた取り込みが可能です。
データソース作成の手順には、以下の2通りがあります。
- ファイルの直接アップロード:
ローカルに保存されているCSV、XLSX、TXT、DOCX、PDF、HTMLなどの多様なフォーマットのドキュメントをアップロードできます。 - 外部サービスからのデータ同期:
Notionアカウントを連携させて特定のページを直接同期したり、Jina ReaderやFirecrawlを利用してWebサイトのコンテンツをスクレイピングしたりできます。
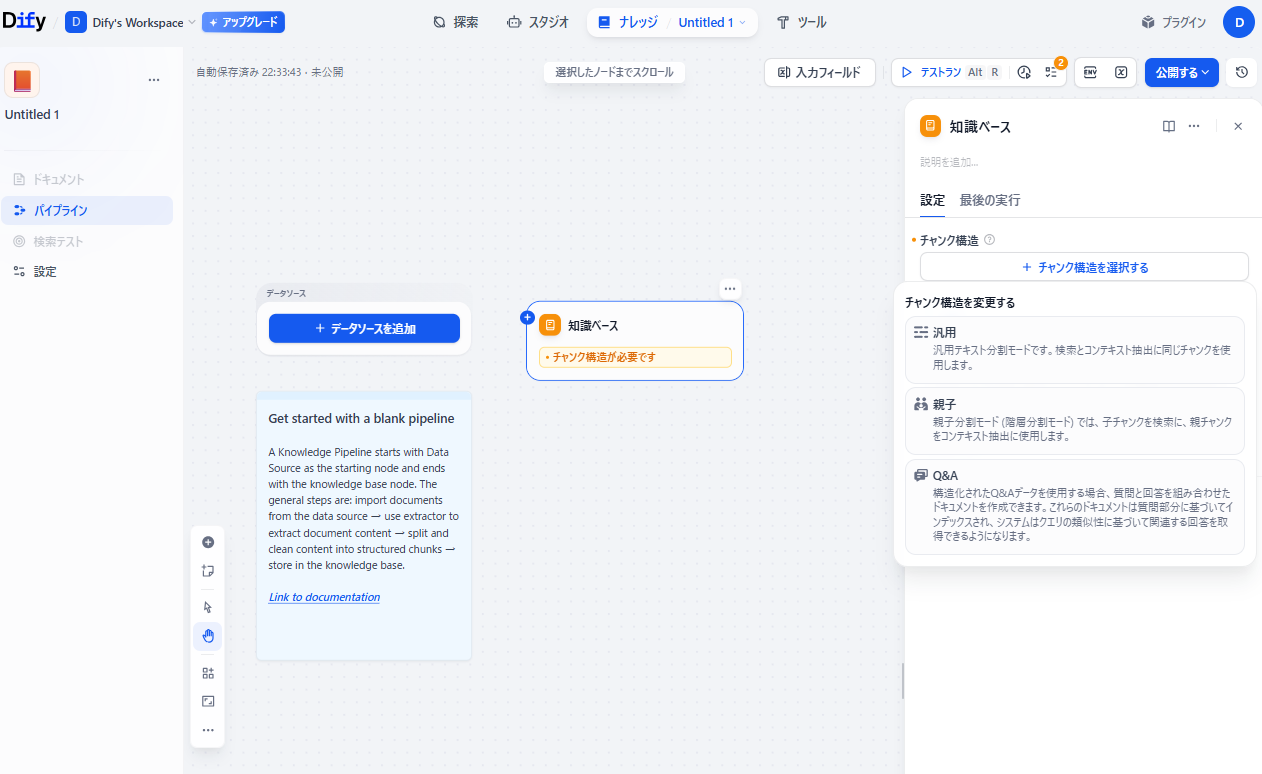
知識パイプラインの構築
知識パイプラインは、取り込んだデータをLLMが理解しやすい形に変換・整理する重要なプロセスです。ただデータをインポートするだけでなく、用途に応じて適切な処理テンプレートを適用することで、検索のヒット率が向上します。
パイプライン構築の主な流れは以下の通りです。
- データのインポートとパース:
アップロードされたドキュメントからテキストを抽出し、DOCXやPPTXなどの複雑なファイル形式をシステムが処理しやすいMarkdown形式等に変換します。 - チャンク化とインデックス作成:
抽出したテキストを意味のある適切なブロック(チャンク)に分割し、ナレッジベースに保存するためのインデックス処理を実行します。
RAGアプリ(チャットボット)の作成と動作確認
ナレッジベースの準備が完了すれば、あとはそれを組み合わせたRAGアプリを作成し、実際の動きをテストするだけです。Difyのスタジオ画面からプロンプトを設定し、対象のナレッジを紐付けることでチャットボットが稼働します。
具体的には以下の手順で進めます。
- アプリケーションの新規作成:
Difyのダッシュボードからチャットボットタイプのアプリを新規作成し、システムプロンプトにアシスタントの役割や回答ルールを記述します。 - コンテキストの連携とテスト:
作成したナレッジベースをコンテキストとして追加し、デバッグ画面で実際に質問を入力して、意図した通りの情報が検索・回答されるかを確認します。
🎯DifyでRAGの検索精度を向上させるコツ
アプリがひと通り動くようになった後、多くの人が直面するのが「回答の精度が低い」「欲しい情報がヒットしない」という壁です。ここでは、チャンク構造の見直しや検索アルゴリズムの調整など、検索精度を引き上げるための実践的なテクニックを紹介します。
最適なチャンク構造の選び方(汎用・親子・Q&Aモードの使い分け)
ドキュメントを分割する「チャンク構造」の選択は、RAGの検索精度を決定づける最重要ポイントの1つです。対象となるドキュメントの性質(長文か、一問一答かなど)に合わないモードを選ぶと、情報が欠落したり関係ないノイズが混じったりします。
Difyには主に3つのチャンクモードが用意されており、以下のような特徴があります。
- 汎用モードの特徴と用途:
検索対象とするテキストブロックと、LLMにコンテキストとして渡すテキストブロックを同一のものとして扱う、最も基本的な処理モードです。 - 親子モードの特徴と用途:
文章の要約や見出し(子チャンク)で高速に検索をヒットさせつつ、回答生成時には詳細な本文(親チャンク)をLLMに渡すことで、長文ドキュメントに威力を発揮します。 - Q&Aモードの特徴と用途:
ドキュメントから想定される質問文を事前にインデックス化し、ユーザーの検索意図とマッチした際にのみ回答を引き当てるため、FAQデータに最適です。ただし、Q&Aモードはセルフホスト環境でのみ利用可能です。
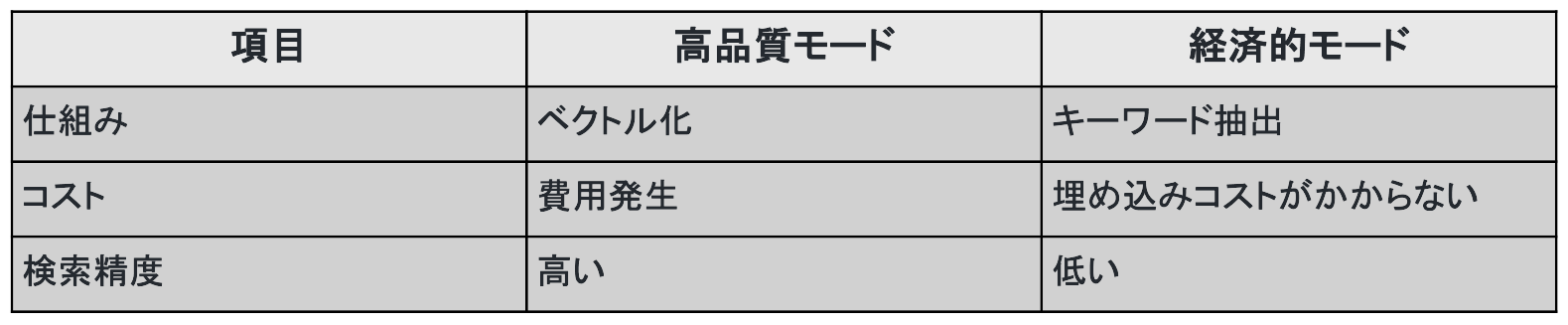
インデックス方法の選択(高品質モードと経済的モードの違い)
データをデータベースに登録する際のインデックス方法は、検索の質とコストのバランスに直結します。高度なベクトル化モデルを使用すれば曖昧な表現でも検索可能になりますが、APIの利用コストが発生します。プロジェクトの予算や求められる精度に応じて適切なモードを選択します。
具体的には以下のような違いがあります。
検索設定のチューニング
RAGの検索フェーズにおいて、どのような検索アルゴリズムを採用するかで、ユーザーの質問に対する回答の網羅性と正確性が変わります。Difyでは複数の検索手法を組み合わせることで、それぞれの弱点を補完し合うことが可能です。
検索設定のチューニングには、以下の2つの重要なアプローチがあります。
- ハイブリッド検索の導入:
単語の完全一致に強い「全文検索」と、意味の類似性を捉える「ベクトル検索」を同時に実行することで、表記揺れや意図の汲み取りに対応します。 - Rerankモデルによるスコア調整:
検索された複数の候補群に対して、Rerankモデルを利用してユーザーの質問との関連性を再計算し、Top K(取得件数)やスコア閾値を最適化します。
テキスト前処理(データクリーニング)の重要性
チャンク化やインデックス作成の前段階で行うデータクリーニングは、地味ながらも回答精度を底上げする必須の工程です。元のドキュメントに不要な情報が多く含まれていると、LLMが文脈を見失い、無関係な回答を生成する原因となります。
Difyの前処理ルールを活用して、以下の処理を行います。
- 不要な記号や空白の除去:
OCRで読み取った文書などに含まれる不自然なスペースや、連続する不要な改行を自動的に削除して、テキストの連続性を確保します。 - URLやメールアドレスのマスク:
回答に直接関係のないURLやメールアドレスなどの情報を事前に取り除くことで、ベクトル化の際のノイズを軽減し、意味の抽出精度を高めます。
🧪【検証】チャンク長の違いによる回答精度を比較してみた!
設定による精度の違いを明確にするため、架空の社内規程ドキュメントを用意し、チャンク長による回答結果の変化を検証しました。
検証条件
今回の検証は、以下の条件で行いました。
- アカウント:無料プラン
- AIモデル:gpt-4o-mini
- 埋め込みモデル:text-embedding-3-large
- 検索設定:ハイブリッド検索
- インデックス方法:高品質
- チャンク設定:汎用
- 最大チャンク長:300/800
- チャンクのオーバーラップ:60/160
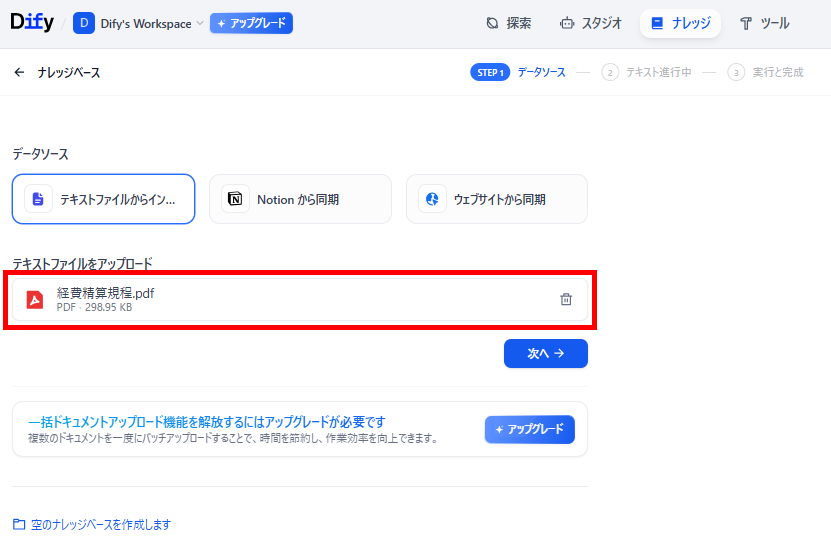
また、読み込ませたファイルは、以下の架空の経費精算規程PDFです。
【経費精算規程のPDFファイル】

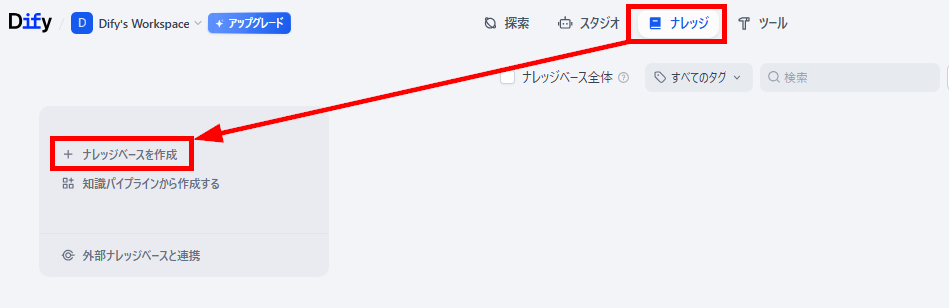
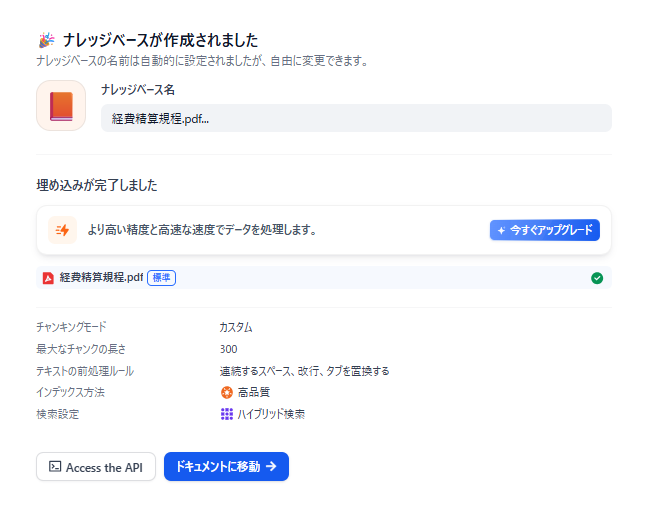
ナレッジベースの作成
チャットボットを構築する前に、コンテキストとして登録するためのナレッジベースを作成します。
- ナレッジベースの作成:「ナレッジ」メニューを開き「ナレッジベースを作成」をクリックします。
- ファイルをアップロード:先ほどの経費精算規程PDFをアップロードし、「次へ」をクリックします。
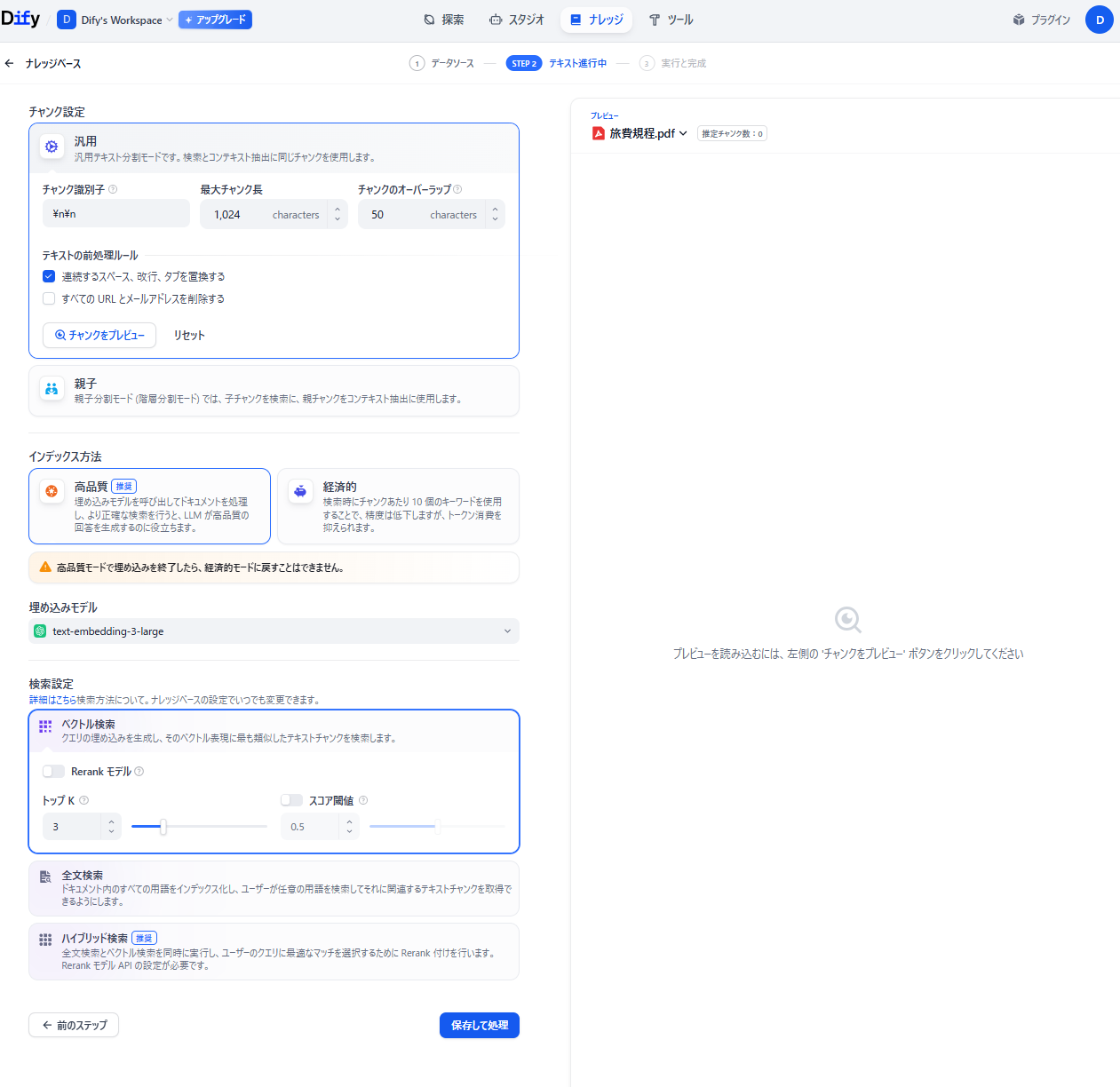
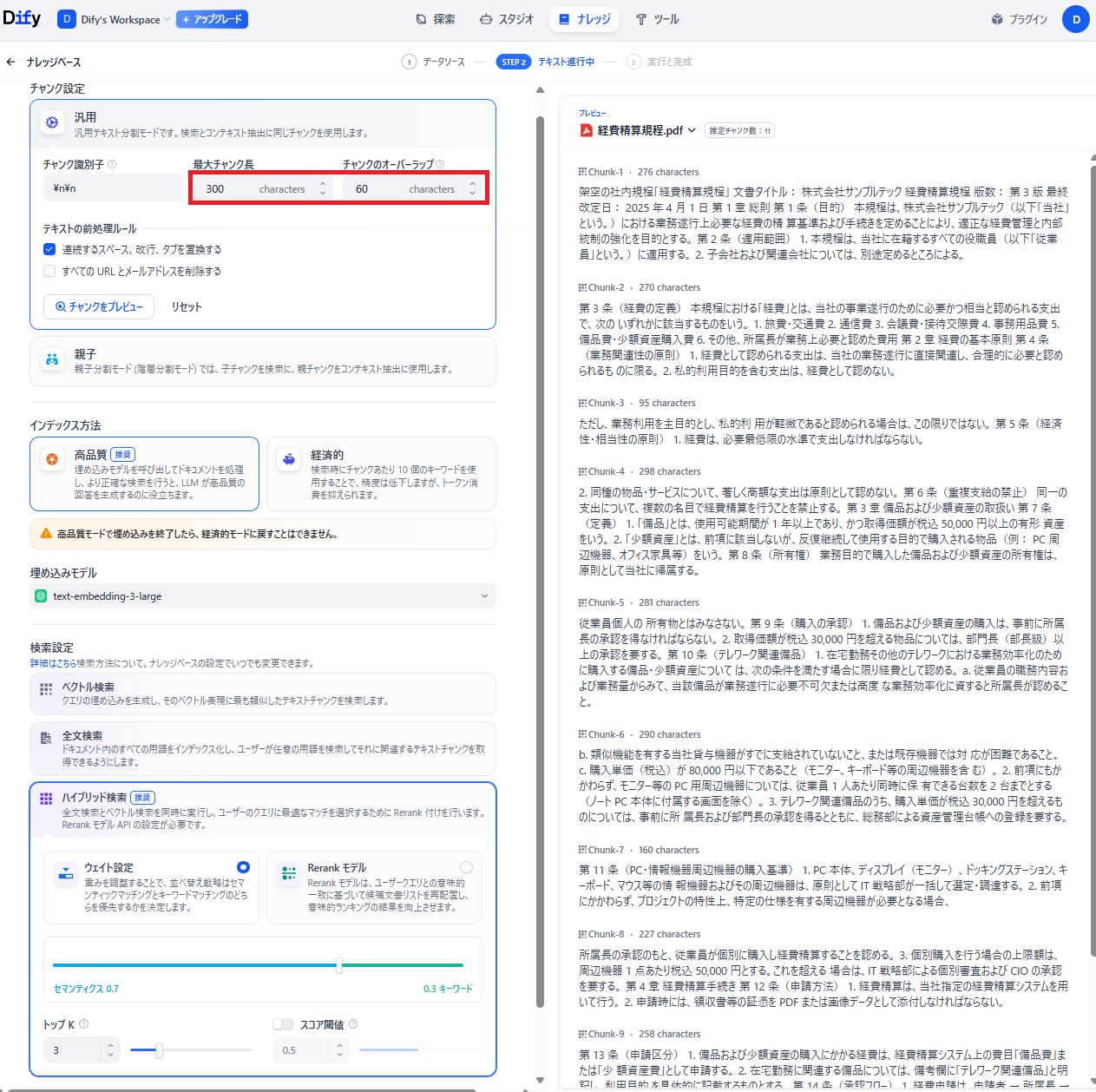
- ナレッジベースの設定と保存:チャンク設定、インデックス方法、埋め込みモデル、そして検索設定を行い保存します。はじめは、「最大チャンク長:300、チャンクのオーバーラップ:60」で設定しています。
- 作成完了:保存すると、ナレッジベースが作成されます。有料プランは、より高速で処理が可能です。
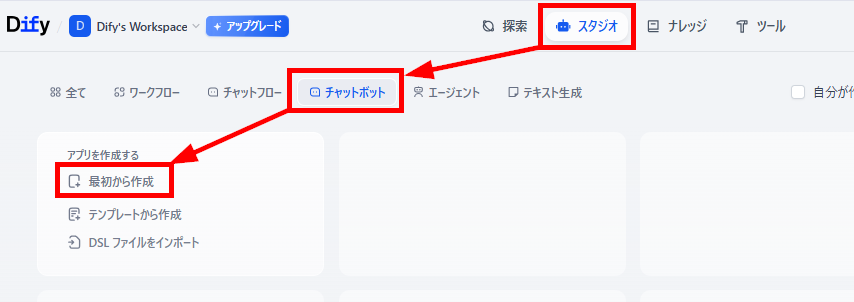
チャットボット作成
ここから、チャットボット形式のアプリでRAGを構築していきます。
- アプリの作成:「スタジオ」メニューで「チャットボット」を選択し、「最初から作成」をクリックします。
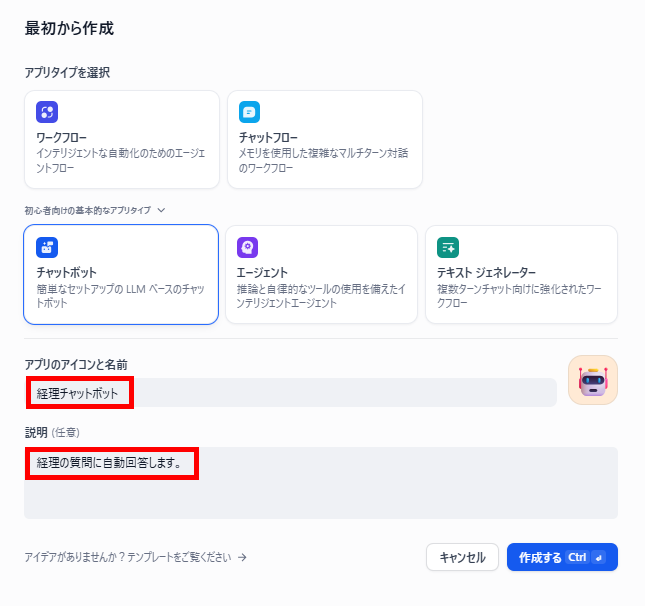
- アプリの概要設定:「名前」「説明」を入力したら「作成する」をクリックします。
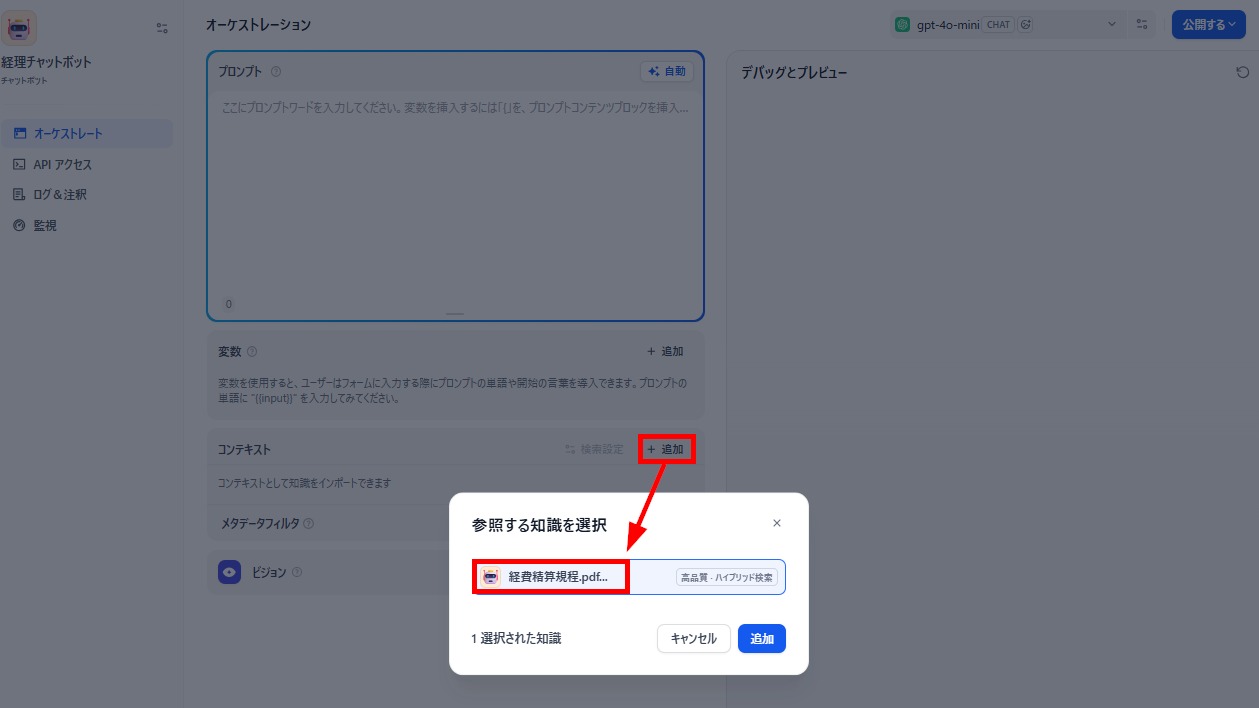
- コンテキストの追加:コンテキスト欄の「+」マークをクリックし、先ほど登録したナレッジベースを選択して追加します。
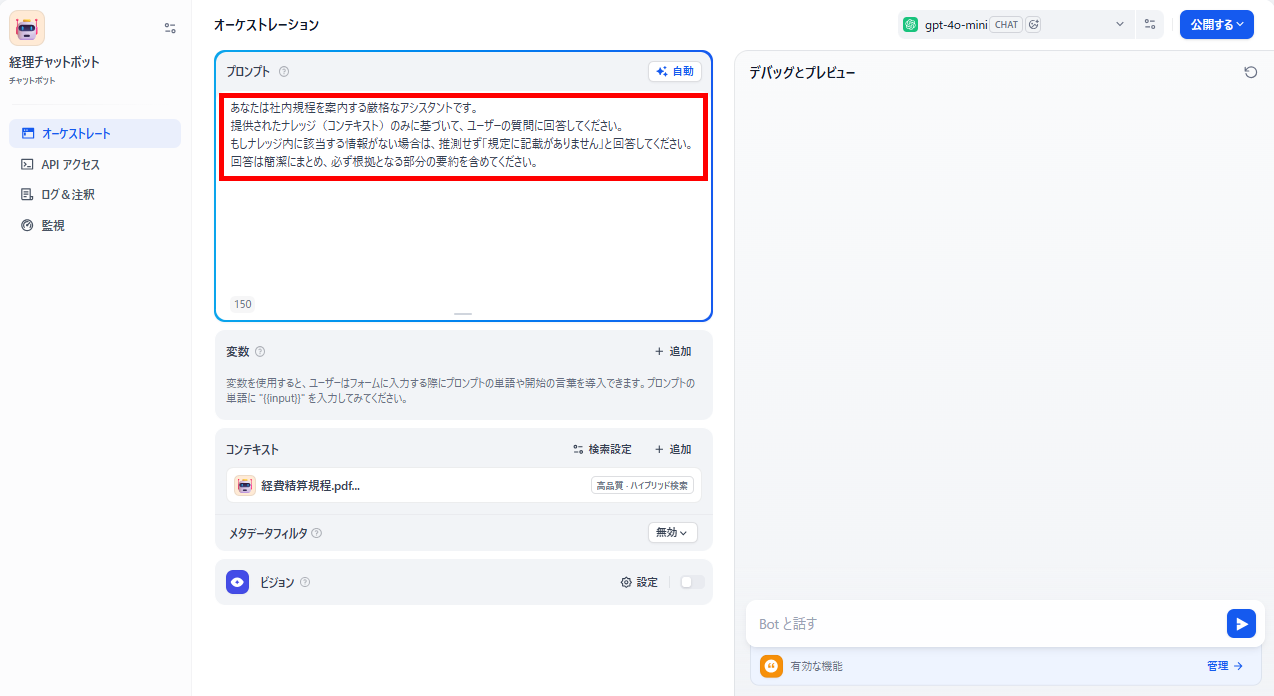
- プロンプトの設定:プロンプト欄に任意の指示を設定し、その他の設定はデフォルトのままにしています。今回は、以下の指示をプロンプト欄に入力しました。
【プロンプト】
あなたは社内規程を案内する厳格なアシスタントです。提供されたナレッジ(コンテキスト)のみに基づいて、ユーザーの質問に回答してください。もしナレッジ内に該当する情報がない場合は、推測せず「規程に記載がありません」と回答してください。回答は簡潔にまとめ、必ず根拠となる部分の要約を含めてください。
動作確認
作成したチャットボットの動作を確認します。今回は、最大チャンク長が「300」と「800」の結果を比較します。
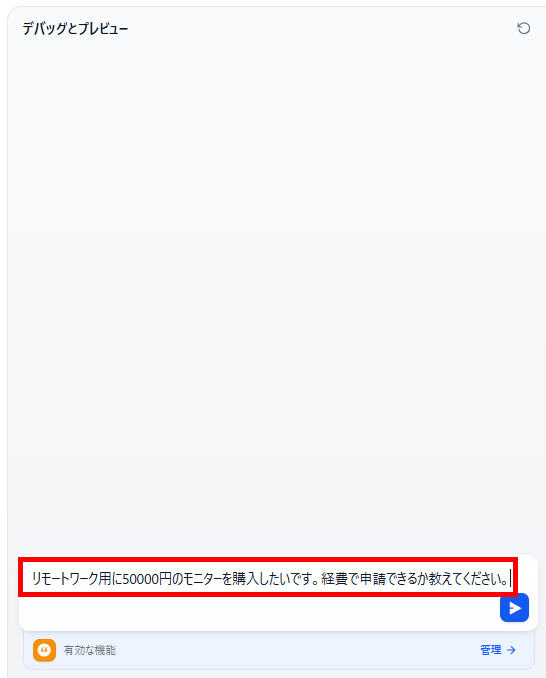
- テストメッセージの送信:テスト用のメッセージを入力して送信します。
【テスト用メッセージ】
リモートワーク用に50000円のモニターを購入したいです。経費で申請できるか教えてください。 - 結果の生成:送信した内容に対する回答が生成されました。
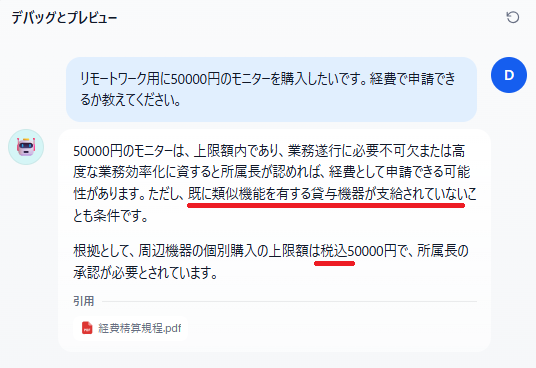
【最大チャンク長:300】
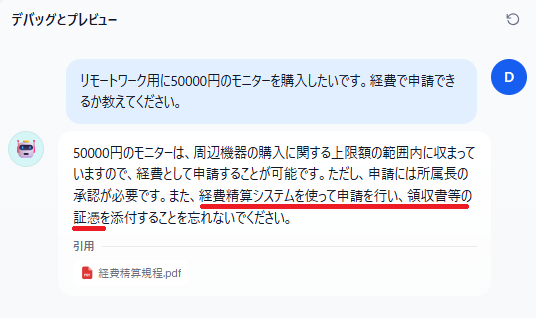
【最大チャンク長:800】
検証結果
最大チャンク長を変えて社内向けチャットボットを構築してみて、以下のことがわかりました。
- チャンク長の違い(300と800)によって、回答の詳細度や引き出される関連情報が変化した
- チャンク長の調整だけで、自社の運用目的に応じた回答のカスタマイズが容易にできる
- チャンク長の設定だけでは細かな条件の漏れが発生することもあり、他の要素との複合的な調整が必要
🔷自社の運用に合わせた柔軟なカスタマイズが可能
今回の検証では、チャンク長の設定を変更するだけで、回答の傾向を調整できることがわかりました。具体的には、以下の挙動の違いが確認されています。- チャンク長300の場合:質問に対して、税込み金額の上限や貸与機器の有無など、より詳細で関連性の高い回答が得られました。
- チャンク長800の場合:質問への回答(イエス/ノー)を簡潔に答えた上で、経費の申請方法といった付随する情報が提示されました。
このように、数値を変更するだけで回答の粒度や方向性を調整できるため、自社の用途やユーザーが求める回答スタイルに合わせて、柔軟にチャットボットを構築しやすい点は大きなメリットです。また、もしチャンク長の調整だけでは解決が難しい場合でも、設定するプロンプトや他の条件を変更することで、回答精度を改善しやすいという拡張性の高さも魅力と言えます。
🔷情報の漏れと設定項目の多さへの対策が必要
一方で、チャンク長の調整だけでは完全に防ぎきれない情報の漏れや、運用上の課題も確認できました。今回の検証では、以下のような具体的な課題が見つかっています。- 「モニター保有は1人2台まで」という、規程上重要な条件が回答から漏れていた。
- 質問文の「50000円」という記載に対して、それが税込みか税抜きかを確認するアクションがなく、状況に応じた正確な判断が下されていなかった。(税込みで50000円を超えるか、それ以下かで対応が変わる)
これらの結果から、チャンク長のみに依存するのではなく、プロンプトで条件確認を促すような指示を追加するなどの工夫が必要です。ただし、Difyはプロンプトや検索設定、インデックス方法など調整できる要素が非常に多いため、初心者が慣れるまでは最適な設定を見つけるのが大変というデメリットも感じられました。導入初期は、検証と調整を繰り返す根気が必要になります。
💼Dify RAGの具体的な業務ユースケース

RAGは単なる情報検索システムにとどまらず、実際の業務フローに組み込むことで真の価値を発揮します。ここでは、Difyを活用した社内FAQや調査業務の効率化など、企業で導入効果が出やすい実践的なユースケースをいくつか紹介します。
社内FAQ・マニュアル検索ボットによる問い合わせ対応の自動化
RAGの最も代表的で効果が出やすい用途が、社内の問い合わせ業務の効率化です。総務や人事、情シス部門に寄せられる定型的な質問をDifyで構築したボットに任せることで、担当者の負担を劇的に削減できます。
具体的には以下の業務に活用できます。
- 就業規則や経費精算ルールの案内:
複雑な社内規程のPDFやNotionページをナレッジとして読み込ませ、社員からの「有給申請の方法は?」といった質問に自動応答させます。 - カスタマーサポートのナレッジ共有:
過去の応対履歴や製品マニュアルをベクトル化し、オペレーターが顧客対応中に必要な情報を瞬時に引き出せるように支援します。
競合分析やマーケット調査の効率化
Web上の公開情報をナレッジとして取り込むことで、自社のマーケティング活動や調査業務を高度化することができます。手動で行っていた情報収集と分析をAIに代替させることで、迅速な意思決定が可能になります。
具体的には以下のユースケースが挙げられます。
- 競合他社のWebサイトクローリング分析:
Jina Reader等を用いて競合企業のサービスサイトやIR情報を定期的に同期し、自社サービスとの機能比較や最新動向の要約を自動で出力させます。 - 最新の業界ニュースや論文の要約:
特定の業界メディアや公開論文のPDFを随時アップロードし、特定のキーワードに関する市場トレンドやインサイトを抽出してレポート化します。
Agentic RAG(エージェント)への応用と今後の展望
単なる情報検索にとどまらず、Difyのワークフロー機能を活用することで、システムが自律的に思考して複数のツールを操作する「Agentic RAG」へと進化させることが可能です。これにより、人間が介入せずとも複雑なタスクを完結させられるようになります。
具体的には以下のような高度化が考えられます。
- ナレッジ検索とアクションの自動連携:
RAGで社内規程を検索してルールを確認したうえで、ユーザーの代わりに自動で申請フォームを作成し、システムへ送信するといった一連の動作を実現します。 - 複数データソースの自律的な使い分け:
ユーザーの質問意図をAIエージェントが自己判断し、社内データベースを検索すべきか、外部のWeb情報を検索すべきかを自動で振り分けて最適な回答を組み立てます。
✨まとめ
Difyを活用したRAGシステムの構築は、専門知識がなくても強力なチャットボットを作成できる画期的な手段です。質の高いナレッジデータの準備から、用途に合わせたチャンク調整、ハイブリッド検索やRerankモデルを駆使した検索設定まで、各ステップを丁寧に行うことが成功の鍵となります。
また、実際にRAGを運用する際は、文脈の繋がりが重要なドキュメントには長めのチャンクを設定し、一問一答形式のFAQには短いチャンクやQ&Aモードを適用するなど、データに応じた設計が重要です。さらに、チャットボット公開後も、ユーザーがどのような質問をして、AIがどのように回答したかのログを分析し、前処理ルールや検索スコアの閾値を微調整し続けることがポイントになります。
🚀 Yoomでできること
Difyを活用してRAGを構築することで業務の効率化を図れますが、自動化できるのは問い合わせなどの一部の作業に限られます。Yoomは、750以上のAIやSaaSツールといったサービスを連携でき、Difyで作成したアプリを組み込んだ業務フローも構築できるため、より多くの自動化が実現可能です。これにより、以下のような効果が期待できます。
- これまでと同じ時間でより多くの作業を完了する
- 時間に追われることなく業務に集中する
導入により、月200件の転記業務を自動化して心理的な負担を削減している企業もあります。Yoomには、自動化フローを構築するためのテンプレートが豊富にあり、直感的な操作で簡単に設定できるので、ぜひ試してみてください。
- AIによる効率的なキーワード生成の方法を導入したいSEO・コンテンツ担当者の方
- キーワードリストの作成から検索意図の分析まで、一連の作業を自動化したいマーケターの方
- Google スプレッドシートで管理しているコンテンツ案から、自動でキーワードを生成したい方
- Google スプレッドシートへの追記を起点にキーワード生成と分類が自動化され、これまで手作業で行っていたリサーチ時間を短縮できます。
- AIが一定の基準でキーワードの適合性を判断するため、担当者による品質のばらつきや判断ミスを防ぎ、ヒューマンエラーのリスクを軽減します。
- はじめに、Google スプレッドシートとNotionをYoomと連携します。
- トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」アクションを設定します。
- オペレーションでAIワーカーを設定し、トリガーで取得したトピックからSEOに最適なキーワードを生成し、検索意図の分類と適合性の判断を自律的に行いNotionに記録するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー設定では、対象のスプレッドシートやシート、読み込むテーブル範囲などを任意で設定してください。
- AIワーカーでは、生成したいキーワードの数や分類の基準、 Notionへの出力方法といったマニュアル(指示)などを目的に応じて任意で設定できます。
- Google スプレッドシート、NotionのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
このワークフローは、Google スプレッドシートへの情報追加を起点に、AIエージェントのように請求内容の妥当性を自動でチェックし、MakeLeapsで請求書を発行する一連の流れを自動化するため、確認作業の精度を高めつつ、請求書発行業務を効率化できます。
- MakeLeapsでの請求書発行プロセスを、より効率的にしたいと考えている経理担当者の方
- AIを活用して、請求内容のチェックを自動化し、業務精度を高めたい方
- Google スプレッドシートのデータを手作業でMakeLeapsに転記している方
- AIが請求内容の妥当性を自動でチェックするため、手作業による確認漏れや判断ミスといったヒューマンエラーの発生を防ぎます
- Google スプレッドシートへの追加からMakeLeapsでの請求書発行までが自動化され、これまでかかっていた作業時間を短縮できます
- はじめに、Google スプレッドシートとMakeLeapsをYoomと連携します
- 次に、トリガーでGoogle スプレッドシートを選択し、「行が追加されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、Google スプレッドシートから取得した情報をもとに請求内容の整合性をチェックしたうえでMakeLeapsで請求書を発行するためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- Google スプレッドシートのトリガー設定では、連携対象としたい任意のスプレッドシートIDとシート名(タブ名)を指定してください
- AIワーカーのオペレーションでは、利用するAIモデルを任意で選択し、請求内容のチェックや判断基準となる指示(プロンプト)を具体的に設定してください
- Google スプレッドシート、MakeLeapsのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Google スプレッドシートをアプリトリガーとして使用する際の注意事項は「【アプリトリガー】Google スプレッドシートのトリガーにおける注意事項」を参照してください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
【出典】
プログラミング知識なしで手軽に構築できます。