








・
Qwenのローカル環境の推奨スペック|ビジネスメール作成で実務レベルを検証

ローカルLLM(大規模言語モデル)の進化は目覚ましく、特にAlibaba Cloudが開発する「Qwen」シリーズは、その高い性能とオープンなアクセス性で世界中の開発者やAI愛好家から注目を集めています。
かつては高価なサーバーやクラウド環境でしか動作しなかったような高性能AIが、今や個人のPC環境、いわゆる「ローカル環境」で手軽に動かせるようになりました。
プライバシーを気にせず、オフラインでも自由にAIを使いたいというニーズに応えるQwenは、まさに現代の「知能の民主化」を象徴する存在です。
本記事では、Qwenをローカル環境で導入するための具体的な手順や、快適に動作させるためのPCスペック、そして実際に使用してみた感想を詳しく解説します。
✍️Qwenとは?Qwenシリーズの主な特徴

Qwenは、Alibaba Cloudによって開発された、世界トップクラスの性能を誇る大規模言語モデル(LLM)シリーズです。
オープンソースとして公開されており、誰でも自由にダウンロードして利用できる点が最大の特徴です。
ここでは、Qwenシリーズの特徴をご紹介します。
驚異的な日本語性能
Qwenは、多言語データセットを用いた学習により、日本語の読み書きにおいて非常に高いレベルに到達しています。
敬語の使い分けや文脈の理解、さらには日本のサブカルチャーに関する知識まで網羅しており、ビジネス文書の作成から創作活動まで、幅広い用途で違和感なく使用できます。
例えば、日本語の言語処理能力を評価する「Nejumi LLM Leaderboard」や「ELYZA-tasks-100」といったベンチマークテストにおいて、Qwen 2.5-72B-Instructなどは、商用の日本語特化型モデルやGPT-4クラスのモデルに匹敵、あるいは一部のタスクで凌駕するスコアを記録することもあります。
Thinking Mode(思考プロセス)
一部のモデル(Thinkingモデルなど)には、複雑な問題を解く際に「思考の過程」を出力する機能が搭載されています。
これは、AIがいきなり答えを出すのではなく、「まず条件を整理しよう」「次にこの可能性を検討しよう」といった具合に、人間のように順序立てて推論を行うものです。
これにより、数学の問題やプログラミングのデバッグ、論理パズルなどの難易度の高いタスクにおいて、正答率が向上しています。
MoE(Mixture of Experts)アーキテクチャ
Qwenモデルの中には、「MoE」と呼ばれる技術を採用したものがあります。
これは、モデル全体が巨大なパラメータを持っていても、一度の推論で使用するのはその一部(エキスパート)だけに限定する仕組みです。
例えば、「30B(300億)」のパラメータを持つモデルであっても、実際に動くのは「3B(30億)」程度というように、「賢さは維持しつつ、動作は軽い」 という理想的なバランスを実現しています。
これにより、ミドルレンジのPCでも高性能なモデルを動かせるようになりました。
⭐YoomはAI活用を自動化できます
ローカルLLMの導入は、AIを自分の手足のように使いこなすための第一歩です。
しかし、個人のPCでAIを動かすだけでなく、チームや組織全体でAIの力を活用したいと考えたことはないでしょうか?
Yoomは、QwenをはじめChatGPTやClaude、Geminiといった様々なAIモデルと、SlackやGoogleドキュメント、Notionなどの日常業務で使うアプリをノーコードで連携させることができるハイパーオートメーションプラットフォームです。
例えば、「毎日届く大量のメールをAIが自動で要約してチャットに通知する」といったワークフローをすぐに構築できます。
Yoomには、すぐに使えるテンプレートが多数用意されています。
「まずは試してみたい!」という方は、以下のテンプレートから自動化を体験してみてください。
■このテンプレートをおすすめする方
- Gmailに届く大量のメールから、重要な情報を効率的に収集したいと考えている方
- メール内容の確認とSlackへの共有作業に、日々手間を感じているチームリーダーの方
- AIを活用して定型的な情報共有業務を自動化し、チームの生産性を高めたい方
■このテンプレートを使うメリット
- 特定のメール受信から内容の要約、Slackへの通知までが自動化され、情報共有にかかる時間を短縮することができます。
- 手作業による重要メールの見落としや、関係者への共有漏れといったヒューマンエラーを防ぎ、確実な情報連携を実現します。
■フローボットの流れ
- はじめに、GmailとSlackをYoomと連携します
- 次に、トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します
- 次に、オペレーションでAI機能の「要約する」アクションを設定し、トリガーで取得したメールの本文を要約します
- 最後に、オペレーションでSlackの「チャンネルにメッセージを送る」アクションを設定し、AIによって要約された内容を指定のチャンネルに通知します
■このワークフローのカスタムポイント
- AI機能の要約オペレーションでは、要約で抽出したい項目や文字数などを任意でカスタムすることが可能です。
- Slackにメッセージを送るオペレーションでは、通知先のチャンネルを任意で設定できるほか、メッセージ内容にメールの件名など前段で取得した値を組み込むといったカスタムが可能です。
■注意事項
- Gmail、SlackのそれぞれととYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 要約機能はミニプラン以上でご利用いただけるアプリとなっております。フリープラン・パーソナルプランの場合は設定しているフローボットのオペレーションやデータコネクトはエラーとなりますので、ご注意ください。
- パーソナルプラン・ミニプラン・チームプラン・サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリを使用することができます。
■このテンプレートをおすすめする方
- Gmailで受信する大量のメールから、重要な情報を効率的に収集したいと考えている方
- 収集した情報をNotionで管理しており、手作業での転記に手間を感じている方
- チーム内での情報共有を円滑にし、担当者の対応漏れなどを防ぎたいと考えている方
■このテンプレートを使うメリット
- Gmailで受信したメールをAIが自動で要約してNotionへ追加するため、情報収集や転記にかかる時間を短縮できます。
- 人の手による転記作業をなくすことで、内容の入力ミスや重要な情報の見落としといったヒューマンエラーの防止に繋がります。
■フローボットの流れ
- はじめに、GmailとNotionをYoomと連携します。
- 次に、トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します。
- 次に、オペレーションでAI機能を選択し、受信したメール本文を対象に「要約する」アクションを設定します。
- 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、要約された内容を指定のデータベースに追加します。
■このワークフローのカスタムポイント
- AI機能の要約アクションでは、目的に応じて要約の粒度や抽出したい項目などを任意でカスタムできます。
- Notionに追加する際、対象のデータベースを任意で設定可能です。また、各プロパティには、前段のAI機能で取得した要約結果を変数として埋め込んだり、定型文を固定値として設定したりできます。
■注意事項
- Gmail、NotionのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 要約機能はミニプラン以上でご利用いただけるアプリとなっております。フリープラン・パーソナルプランの場合は設定しているフローボットのオペレーションやデータコネクトはエラーとなりますので、ご注意ください。
- パーソナルプラン・ミニプラン・チームプラン・サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリを使用することができます。
✅ローカル環境でQwenを使うためのPCスペック

ローカル環境でQwenを動かす際、最も重要になるのがPCのスペック、特に「GPU(グラフィックボード)」と「VRAM(ビデオメモリ)」の容量です。
LLMは非常に多くの計算リソースを消費するため、一般的な事務用PCでは動作が重かったり、そもそも起動しなかったりすることがあります。
しかし、適切なモデルを選べば、ゲーミングPCやMacBookでも十分に快適な動作が可能です。
ここでは、モデルのサイズ(パラメータ数)と、それを動かすために必要な推奨スペックの関係を解説します。
PCのスペックと相談しながら、自分に最適なモデルを見つけましょう。
軽量モデル(1.5B ~ 7Bクラス)
- 推奨VRAM:4GB ~ 8GB
- 対応PC:エントリークラスのゲーミングPC、MacBook Air(M1/M2/M3)などの比較的新しいノートPC
最も手軽に試せるモデルサイズです。
特に「4B(40億パラメータ)」前後のモデルは、Webブラウジングや資料作成の補助など、簡単なタスクなら快適に動作します。
ただし、出力精度が落ちる傾向があります。
VRAMが6GB程度のGPU(NVIDIA GeForce GTX 1660 TiやRTX 3050など)でも、量子化(データを軽量化する技術)されたモデルであれば十分に利用可能です。
中規模モデル(14B ~ 32Bクラス)
- 推奨VRAM:12GB ~ 24GB
- 対応PC:ミドル〜ハイエンドのゲーミングPC(RTX 3060/4070以上)、MacBook Pro(16GB RAM以上)
性能と動作のバランスが良いゾーンです。
特に「14B」クラスは、VRAM 12GBのGPU(RTX 3060など)でギリギリ動作し、7Bクラスよりも明らかに賢い回答が得られます。
「32B」クラスになると、VRAM 16GB〜24GBが必要となり、RTX 3090/4090などのハイエンドGPUや、メインメモリをVRAMとして共有できるMacBook(32GB RAM以上推奨)が選択肢に入ります。
このクラスになると、複雑な指示や長文の要約も高精度にこなせます。
量子化(Quantization)の活用
スペック要件を見る際に重要なのが「量子化」です。
通常、モデルは「16bit」などの精度で提供されますが、これを「4bit」や「8bit」に圧縮することで、必要なVRAM容量を大幅に削減できます。
例えば、本来VRAMが60GB以上必要な巨大モデルでも、4bit量子化を行えば24GBのVRAM(RTX 3090/4090 1枚)で動作する可能性があります。
出力精度(回答の精度)は若干落ちる場合がありますが、ローカル環境ではメモリ節約のために「4bit量子化モデル(Q4_K_Mなど)」を利用するのが一般的です。
CPU実行という選択肢
GPUのVRAMが足りない場合でも、メインメモリ(RAM)を使ってCPUで計算させること(CPUオフロード)が可能です。
ただし、GPUに比べて計算速度は圧倒的に遅くなります。
「回答が返ってくるまで数分かかる」ということも珍しくありません。
実用的な速度(1秒間に数文字以上が表示されるレベル)を求めるなら、やはりモデル全体がVRAMに収まるサイズのモデルを選ぶか、Macのようにメモリ帯域が広いマシンを選ぶことをおすすめします。
💡Qwenをローカルで利用するおすすめの方法

QwenのようなローカルLLMを動かすためのプラットフォームはいくつか存在しますが、初心者から上級者まで幅広くおすすめできるのが「LM Studio」と「Ollama」の2つです。
これらは、複雑な環境構築(Pythonやライブラリのインストールなど)をほとんど必要とせず、アプリをインストールするだけで、最新モデルを含めて簡単にQwenをローカルで始められるツールです。
それぞれの特徴と、利用時のポイントを紹介します。
LM Studio:視覚的で直感的な操作が可能
LM Studioは、GUI(グラフィカルユーザーインターフェース)を備えたデスクトップアプリです。
Webブラウザのような画面でモデルを検索・ダウンロードし、そのままチャット画面で会話を楽しむことができます。
【メリット】
- モデルの検索が簡単:アプリ内の検索バーに「Qwen」と入力するだけで、利用できるモデルを探してダウンロードできます。
- 設定が視覚的:GPUへの負荷分散(GPU Offload)やコンテキスト長の設定などを、スライダーやプルダウンで直感的に調整できます。
- 商用利用の緩和:2025年7月8日より、企業や組織での商用利用が無料化され、ビジネス用途でも導入しやすくなりました(※最新のライセンス条項は必ず公式サイトで確認してください)。
【使い方】
- 公式サイトからインストーラーをダウンロードして実行
- LM Studioを開き、モデルを検索してダウンロード
- チャット画面(吹き出しアイコン)でモデルを選択し、会話を開始
Ollama:コマンド一つで高速起動
Ollamaは、コマンドライン(ターミナル)での操作を基本とするツールですが、その手軽さと軽快な動作で絶大な人気を誇ります。
バックグラウンドで動作するため、他のアプリとの連携も容易です。
【メリット】
- 導入が爆速:インストール後、ターミナルで `ollama run qwen3` などのコマンドを打つだけで、モデルのダウンロードから起動まで全自動で行われます。
- ライブラリが豊富:PythonやJavaScriptなどのプログラムからOllamaを呼び出すライブラリが充実しており、自作アプリへの組み込みが簡単です。
- 軽量:動作が非常に軽く、リソースの消費を抑えられます。
【使い方】
- 公式サイトからインストーラーをダウンロード
- ターミナル(コマンドプロンプト)を開き、`ollama run qwen3:4b` などのコマンドを入力
- ダウンロード完了後、そのままターミナル上でチャットが可能
注意点
Qwen自体はApache 2.0などのオープンなライセンスで提供されることが多いですが、派生モデルや特定のバージョンによっては利用規約が異なる場合があります。
商用利用を検討する際は、Hugging Faceのモデルカードなどでライセンスを確認しましょう。
また、ストレージ容量についても注意が必要です。
モデルデータは数GB〜数十GBのサイズになります。
SSDの空き容量には十分余裕を持たせてください。
🤔Qwenをローカル環境で使ってみた

今回は、LM Studioを使用して、実際にQwenをローカル環境で動作検証してみました。
検証に使用したモデルは、一般的なノートPCでも利用できる2つの軽量モデルです。
検証条件
使用ソフト:LM Studio
使用モデル:Qwen3-4B-Thinking-2507(4bit量子化版)/Qwen3-4B(4bit量子化版)
※執筆時点では、Qwen3.5-397B-A17Bモデルも公開されていますが、PCのスペックの関係で上記のモデルを選択しました。
PC環境:
- CPU:Intel Core i5-13420H
- GPU:なし
- RAM:16GB
検証内容
今回は、一般的な業務シーンを想定し、ビジネスメールを作成してもらい、生成にかかる時間と日本語の流暢さを確認しました。
検証:ビジネスメールの作成
それでは、LM Studioを使って、各モデルを利用します。
まずは、LM Studioをインストール後、以下の手順で利用モデルをダウンロードします。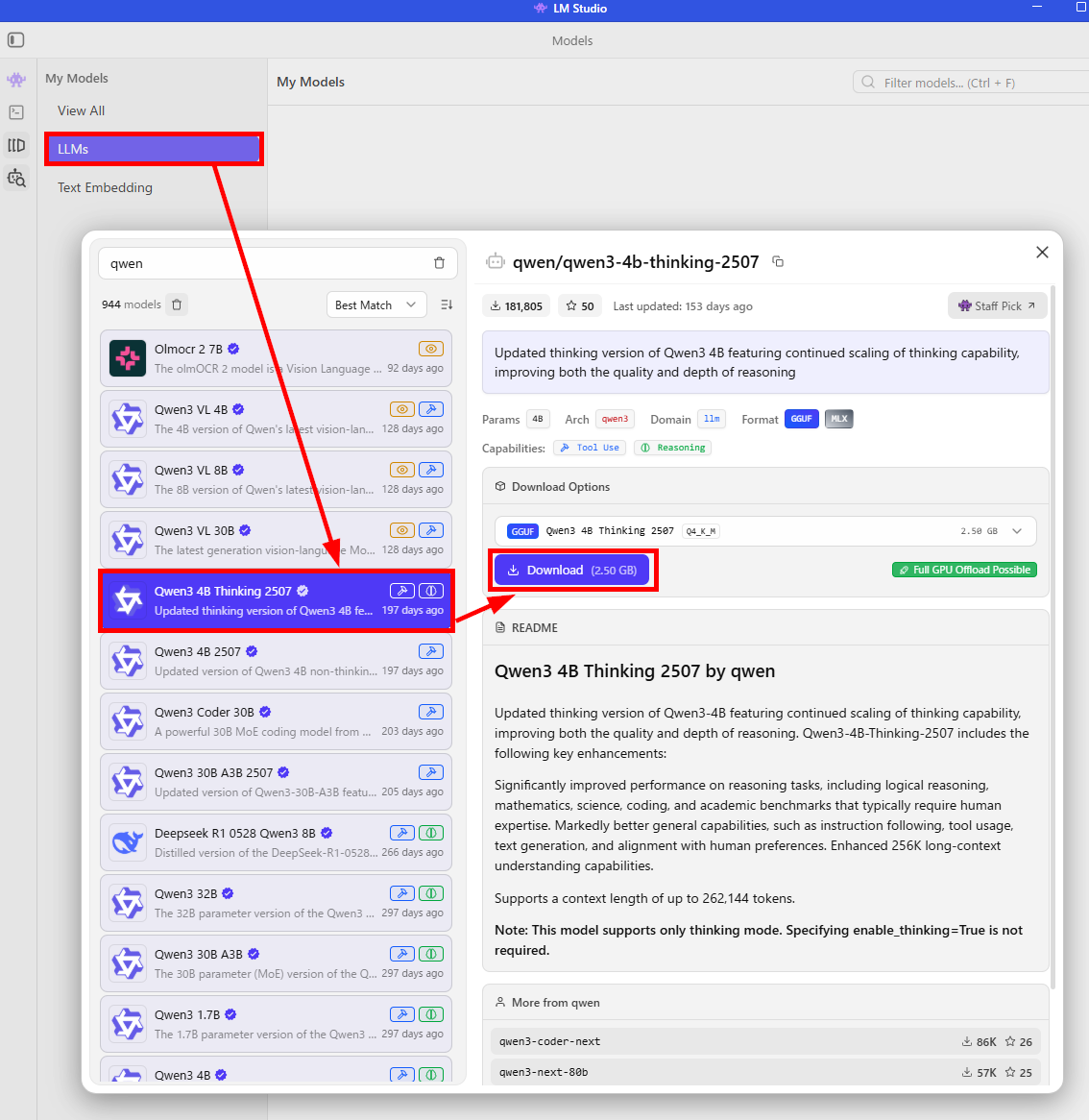
モデルをダウンロード後、チャット画面を開き、モデルを選択したらプロンプトを送信します。
今回は、以下のプロンプトを送信しました。
【検証プロンプト】
取引先の「株式会社Yoom」の佐藤様に、来週の月曜日の14時から打ち合わせをお願いするメールを作成してください。
件名は分かりやすく、本文は丁寧なビジネス敬語を使ってください。
【Qwen3-4B-Thinking-2507】
【Qwen3-4B】
結果と感想
上記のプロンプトを2つのモデルで検証したところ、以下の結果が生成されました。
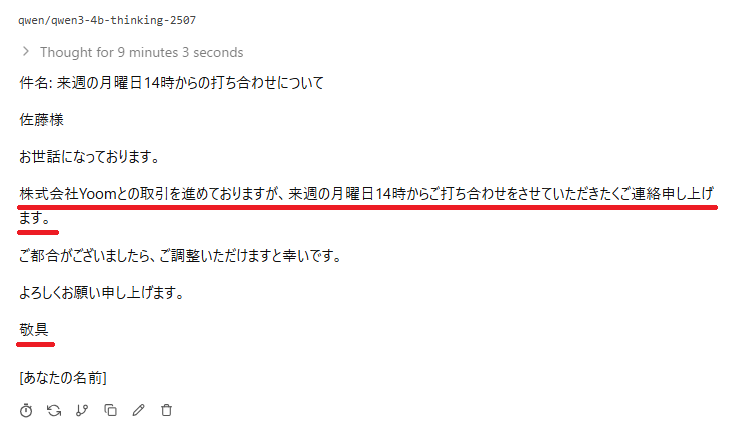
【Qwen3-4B-Thinking-2507】
【Qwen3-4B】

生成された結果から、以下のことがわかりました。
- LM Studioを使えば、難しい設定不要でQwenをローカル環境で利用可能
- GPU非搭載のPCでも動作はするが、「Thinking」モデルは出力に時間がかかる
- 軽量モデル(4Bクラス)は不自然な日本語や他言語が混ざり実用性に課題がある
LM Studioを活用することで、GPUを搭載していない一般的なPC環境でも、難しい設定を行わずに「Qwen」をローカルで即座に利用開始できました。
モデルの選択肢がある点や、簡単にダウンロードして利用できる点は非常に便利です。
一方で、今回の検証環境ではスペックの制約から軽量な4Bモデルを使用しましたが、生成精度には課題が見られました。
【Qwen3-4B】は約1分で素早く出力したものの「您的」といった不自然な表記が混じりました。
また、【Qwen3-4B-Thinking-2507】は思考プロセスを経るため出力に10分近くかかった上、相手を「第三者」と呼ぶなどビジネスメールとしては違和感のある日本語となりました。ローカル環境でQwenを利用するハードルは低いですが、実用レベルで活用するには、より高性能なモデルを選定し、それを快適に動かせる十分なPCスペックを用意することが重要だと言えます。
📉まとめ
本記事では、Qwenをローカル環境で動かすための基礎知識から、推奨スペック、そしてLM Studioを使った具体的な検証結果までを解説しました。
LM StudioやOllamaといったツールの登場により、ローカルLLMの導入ハードルはかつてないほど下がっています。
Qwenは、日本語性能の高さと「Thinking Mode」による深い推論能力を兼ね備えたモデルで、軽量モデルであれば、一般的なPCでも動作し、プライバシーを守りながらAIを利用できます。
ただし、検証結果からもわかるように、軽量モデルはプロンプトの文脈を理解することに課題があります。
実用的な業務で利用するには、タスクに見合ったモデルとPCのスペックが必要になる点に注意してください。
⭐Yoomでできること
ローカル環境でのQwenの検証を通じて、AIの可能性を実感していただけたのではないでしょうか。
しかし、ローカルで動かすAIはあくまで「個人の作業補助」にとどまりがちです。
Yoomを使えば、AIのパワーをチーム全体に拡張し、業務フローそのものを変革することができます。
例えば、「Notionに書き溜めたアイデアメモを、AIが自動で要約や解析などを行いメンバーに共有する」といったフローや、「毎日提出される日報をAIが読み込み、重要なトピックだけを抽出してSlackでマネージャーに報告する」 といった仕組みを簡単に実現できます。
気になる方は、ぜひ試してみてください。
このワークフローは、Notionのデータソースに新しいページが追加・更新されると、その内容をGeminiが自動で解析し、要約した結果をGoogle Chatに通知します。GeminiとGoogle Chatを連携させることで、情報共有のプロセスを自動化し、手作業による確認や転記の手間を省き、チーム全体の情報共有を円滑にします。
■このテンプレートをおすすめする方
- Notionに集約した情報を、手作業でGoogle Chatに共有しており手間を感じている方
- GeminiとGoogle Chatを連携させ、情報共有の自動化や効率化を実現したい方
- 最新情報の確認漏れを防ぎ、チーム内の効率的な意思決定を促進したいマネージャーの方
■このテンプレートを使うメリット
- Notionへの情報追加を起点にGeminiでの解析とGoogle Chatへの通知が自動化され、これまで手作業で行っていた情報共有の時間を短縮します。
- 手作業による情報の転記ミスや共有漏れを防ぎ、常に正確な情報に基づいたコミュニケーションを実現できます。
■フローボットの流れ
- はじめに、Notion、Gemini、Google ChatをYoomと連携します。
- 次に、トリガーでNotionを選択し、「特定のデータソースのページが作成・更新されたら」というアクションを設定します。
- 次に、オペレーションで分岐機能を設定し、取得した情報をもとに特定の条件で後続のアクションを実行するかを判断させます。
- 次に、オペレーションでNotionの「レコードを取得する(ID検索)」を設定し、トリガーで反応したページのより詳細な情報を取得します。
- 次に、オペレーションでGeminiの「コンテンツを生成」を設定し、取得したNotionの情報を元に要約などのテキストを生成します。
- 最後に、オペレーションでGoogle Chatの「メッセージを送信」を設定し、Geminiが生成したテキストを指定のスペースに送信します。
■このワークフローのカスタムポイント
- Notionのトリガー設定では、連携の対象としたいデータソースIDを任意で設定してください。
- 分岐機能では、Notionから取得したページのプロパティ(ステータスなど)の値を基に、後続の処理を実行する条件を自由に設定できます。
- Geminiにテキスト生成を依頼する際のプロンプトは自由にカスタマイズでき、Notionから取得した情報を変数として組み込むことで、目的に応じた文章を作成させることが可能です。
- Google Chatへの通知では、メッセージを送信するスペースを任意で指定できるだけでなく、本文にGeminiが生成した内容やNotionの情報を変数として埋め込めます。
■注意事項
- Notion、Gemini、Google ChatのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。プランによって最短の起動間隔が異なりますので、ご注意ください。
- 分岐はパーソナルプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- パーソナルプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。詳しくは、「料金プランのページ」をご参照ください。
- Google Chatとの連携はGoogle Workspaceの場合のみ可能です。詳細は「Google Chatでスペースにメッセージを送る方法」を参照ください。
- フォームで収集した業務日報の確認に、多くの時間を費やしているマネージャーの方
- DeepSeekなどの生成AIを活用して、日報の要約プロセスを自動化したいと考えている方
- Slackでの情報共有を効率化し、チームの生産性を向上させたいチームリーダーの方
- フォーム送信をトリガーに日報の要約とSlack通知が自動で実行されるため、これまで日報の確認に費やしていた時間を短縮することができます。
- AIが日報の要点を抽出して通知するため、重要な情報の見落としを防ぎ、確認業務の品質を一定に保つことに繋がります。
- はじめに、DeepSeekとSlackをYoomと連携します。
- 次に、トリガーでフォームトリガー機能を選択し、「フォームが送信されたら」というアクションを設定します。
- 次に、オペレーションでAI機能の「画像・PDFから文字を読み取る」を設定し、フォームで送信された日報ファイルからテキストを抽出します。
- 次に、オペレーションでDeepSeekの「テキストを生成」アクションを設定し、抽出したテキストを要約するよう指示します。
- 最後に、オペレーションでSlackの「チャンネルにメッセージを送る」アクションを設定し、生成された要約文を指定のチャンネルに通知します。
- フォームトリガーで設定するフォームの質問項目は、日報に必要な内容に合わせて自由にカスタマイズが可能です。
- DeepSeekにテキスト生成を依頼する際のプロンプト(指示文)は、箇条書きでの要約を依頼するなど、目的に応じて自由に設定できます。
- Slackへの通知メッセージは、通知先のチャンネルを任意で設定できるほか、本文に固定のテキストや、前段のオペレーションで取得した情報を変数として埋め込むことも可能です。
- DeepSeek、SlackのそれぞれとYoomを連携してください。
【出典】
GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud./LM Studio/Ollama/Qwen/GitHub - wandb/llm-leaderboard: Project of llm evaluation to Japanese tasks/日本語LLMまとめ | LLM-jp/Qwen2.5: A Party of Foundation Models! | Qwen
プログラミング知識なしで手軽に構築できます。







