








・
Geminiのマルチモーダルを実務検証|手書き領収書のデータ化で探る導入の判断材料

人工知能技術の進化により、AIは単なる計算機から、仕事のパートナーとしての役割を担えるようになりました。
その進化の中心にあるのが「マルチモーダル」という概念です。
これまでのAIは、主にテキストデータの処理に特化していましたが、Googleが開発したGeminiは、テキストに加え、画像、音声、動画といった異なる形式の情報を同時に理解し、処理する能力を持っています。
これは、AIが人間のように「目」で見て、「耳」で聞いて世界を認識できるようになったことを意味します。
本記事では、Geminiのマルチモーダル機能の仕組みから、具体的な制限事項、そしてすぐ使える活用事例までを網羅的に解説するので、ぜひ参考にしてみてください。
✍️マルチモーダルAIの概要と仕組み

Geminiを語る上で欠かせない「マルチモーダル」という言葉ですが、具体的にどのような仕組みで、従来のAIと何が異なるのでしょうか。
ここでは、その基本的な概念と、Geminiが持つ独自の特徴である「ネイティブマルチモーダル」について詳しく解説します。
シングルモーダルAIとの決定的な違い
従来の多くのAIモデルは「シングルモーダル」と呼ばれ、特定の種類のデータしか処理できませんでした。
例えば、翻訳AIはテキストデータのみを扱い、画像認識AIは画像データのみを扱います。
これらを組み合わせて「画像を見て翻訳する」というタスクを行う場合、一度画像を別のAIでテキストに変換し、そのテキストを翻訳AIに渡すというステップが必要です。
しかも、この方法では画像に含まれる微妙なニュアンスや、音声のトーンに含まれる感情などが、テキスト変換の過程で抜け落ちてしまうことがあります。
一方、マルチモーダルAIは、テキスト、画像、音声、動画といった異なるモダリティ(情報の種類)を、変換することなくそのまま入力として受け取ることができます。
一部の入出力データの種類によっては、依然として複数のステップが必要ですが、マルチモーダルAIは複数の情報を並列で処理し、より深く、正確な理解が可能です。
これにより、AIの活用範囲は飛躍的に広がりました。
Geminiの強みである「ネイティブマルチモーダル」
Geminiが他のマルチモーダルAIと一線を画す点は、「ネイティブマルチモーダル」として設計されていることです。
多くのマルチモーダルモデルは、テキスト専用のモデルに視覚や聴覚のコンポーネントを後付けで学習させて作られています。
これに対し、Geminiは開発の初期段階から、テキスト、画像、音声、動画、コードなど、多様なデータを同時に学習しています。
この「生まれながらにしてマルチモーダルである」という特徴により、Geminiは異なる種類の情報をシームレスに結びつけることができます。
これが、Googleが提供するGeminiの最大のアドバンテージと言えます。
🖊️Geminiマルチモーダル機能の具体的な制限と仕様
Geminiは非常に強力なツールですが、無限に何でもできるわけではありません。
システムのリソースや安全性を保つために、いくつかの制限が設けられています。
ここでは、ビジネスや開発で利用する際に押さえておくべき、具体的な数値や仕様について解説します。
コンテキストウィンドウとトークン制限
AIが一度に処理できる情報量は「コンテキストウィンドウ」と呼ばれ、トークン数で表されます。
Gemini 3.1 Proなどのモデルでは、標準で100万トークン(一部の環境では200万トークン)という膨大なコンテキストウィンドウを持っています。
これは、テキストであれば数千ページの文書に相当し、動画であれば約1時間分、音声であれば約11時間分のデータを一度に読み込める計算になります。
無料版のGeminiを利用する場合でも、一般的なWeb記事や短時間の動画であれば問題なく処理することが可能です。
ただし、同じモデルでもプランに応じてコンテキストウィンドウの大きさが変わるため、映画1本分の動画や、膨大な過去の議事録データを一度に分析させたい場合は、Google AI Pro以上の有料プランやAPIの上位モデルを利用する必要が出てきます。
また、APIの利用にはレート制限(1分間あたりのリクエスト数など)があり、新たな使用量ティアの導入により無料枠(Free Tier)ではモデルによって1日に20〜100リクエスト程度といった制限が存在するため、システムに組み込む際は注意が必要です。
ファイル入力に関する制限(画像・動画・音声)
Geminiにアップロードできるファイルにも、サイズや形式の制限があります。
Google AI StudioやVertex AIなどの開発環境における仕様に基づくと、以下のような制限が一般的です。
-
画像
JPEG、PNG、WebPなどの形式に対応しており、一度のプロンプトで処理できる枚数は最大で3,000枚(Gemini 3.1 Proの場合)とされています。
また、Geminiのチャット版ではUI上の制限により、一度にアップロードできるのは10枚に制限されることが一般的です。 -
動画
MP4、MOVなどの形式に対応しています。
動画データは内部的に画像フレームと音声に分解されて処理されます。
トークン数の制限内であれば処理可能ですが、Web版などではアップロードできるファイルサイズに上限(2GB)があります。
チャット版では、ファイルの種類を問わず1つのファイルの上限は100MBです。 -
音声
MP3、WAV、AACなどに対応しており、最大で約11時間分の音声データを処理可能(Gemini 3.1 Pro)です。
ただし、これもトークン数の上限に依存するため、内容の密度によって処理できる長さは変動します。
出力生成における制限と対応形式
入力に関しては多様なフォーマットを受け付けるGeminiですが、出力に関しては制限があります。
執筆時点において、Geminiが生成できるのは、「テキスト」「画像」「動画」「音楽」の4種類です。
-
テキスト出力
文章の要約、翻訳、コードの生成、構造化データ(JSONやCSV)の作成など、あらゆるテキストタスクに対応しています。 -
画像出力
Googleが開発する画像生成AIモデルのImagenの技術を統合したNano Bananaというモデルが、テキストの指示から画像を生成することが可能です。 -
動画・音楽出力
チャット画面から直接、音楽(Lyria)やショート動画(Veo)を生成・出力することが可能になりました。
「Lyria 3」モデルの統合により、プロンプトを入力するだけで30秒程度のオリジナル楽曲(歌詞付きも可能)をチャット内で生成・再生・共有できます。
また「Veo 3.1」モデルにより、テキストや画像プロンプトから約8秒間の高品質な動画をチャット内で直接生成することが可能です。
⭐YoomはGeminiを業務フローに組み込めます
Geminiのマルチモーダルは単体でも十分使えますが、業務全体の効率化を考えると、データの入口から出口まで自動化したいところです。
Yoomなら、その仕組みをノーコードでつくれます。
[Yoomとは]
たとえば、Dropboxに書類が追加されたらAIワーカーが内容を自動分析し、NotionへのDB登録とSlack通知までまとめて処理してくれるテンプレートがすぐに使えます。
「まずは試してみたい!」という方は、以下のテンプレートからすぐに自動化を体験してみましょう!
- 複数の業者からの相見積もりの比較検討に時間がかかっている購買担当者の方
- AIを活用して、属人化しがちな相見積もり業務を標準化したい方
- Gmailに届く大量の見積書の管理と内容確認を効率化したいと考えている方
- Gmailで見積書を受信するとAIが自動で内容を比較するため、これまで手作業で行っていた確認や比較検討の時間を短縮できます。
- AIが設定された基準で相見積もりの比較を行うため、担当者による判断のブレを防ぎ、業務の標準化に繋がります。
- はじめに、GmailをYoomと連携します。
- 次に、トリガーでGmailを選択し、「特定のキーワードに一致するメールを受信したら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、受信した見積書の内容を比較し、最適なものを判定するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Gmailのトリガー設定では、「見積書」「相見積もり」など、検知したいメールの件名や本文に含まれるキーワードを任意で設定してください。
- AIワーカーへの指示内容は、価格や納期、サービス内容といった比較項目や判定基準などを、自社のルールに合わせて自由に設定することが可能です。
- GmailとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIエージェントを活用して、膨大な応募書類の書類選考を効率化したい採用担当者の方
- DropboxやNotionを使い、採用候補者情報を管理している人事責任者の方
- 候補者への迅速な対応と、選考基準の標準化を実現したいチームリーダーの方
- 書類が追加されるとAIが自動で内容を分析するため、**書類選考**にかかる時間や確認作業の手間を削減できます
- **ai agent**が設定された基準で評価を行うため、担当者による評価のばらつきを防ぎ、選考プロセスの属人化解消に繋がります
- はじめに、Dropbox、Notion、SlackをYoomと連携します
- 次に、トリガーでDropboxを選択し、「特定のフォルダ内でファイルが作成または更新されたら」というアクションを設定します
- 次に、オペレーションでAIワーカーを設定し、受け取った履歴書・職務経歴書を自動でスコアリングするためのマニュアル(指示)を作成します
- 続けて、オペレーションでNotionの「データベースにアイテムを作成する」アクションを設定し、AIの評価結果などを記録します
- 最後に、オペレーションでSlackの「メッセージを送信する」アクションを設定し、担当チャンネルに評価結果を通知します
■このワークフローのカスタムポイント
- Dropboxのトリガー設定では、履歴書を格納する対象フォルダのパスやファイル名を任意の値に設定してください
- AIワーカーの設定では、利用したいAIモデルを選択し、自社の採用基準に合わせた評価を行うよう、指示(プロンプト)を任意の内容で設定してください
- Notionへ連携する際には、情報を記録したいデータベースや、各プロパティに設定する値を任意で指定してください
- Slackへ通知する際には、通知先のチャンネルやメッセージの内容を任意で設定してください
- Dropbox、Notion、SlackのそれぞれとYoomを連携してください
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます
- プランによって最短の起動間隔が異なりますので、ご注意ください
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
📜入力と出力を組み合わせた6つの活用事例

マルチモーダル機能の真価は、異なる入力と出力を組み合わせることで発揮されます。
ここでは、ビジネスシーンや日常業務ですぐに役立つ、具体的な6つの活用パターンを紹介します。
事例1:【画像→テキスト】手書きメモのデジタル化・構造化
会議やブレインストーミングの際、ホワイトボードに書かれた図や手書きのメモを、後からデジタルデータに起こす作業は非常に手間がかかります。
Geminiを使えば、この作業をスムーズに完了させることができます。
例えば、ホワイトボードの写真を撮影してGeminiにアップロードし、「この図の内容を読み取って、箇条書きでまとめてください」と指示すれば、手書きの文字認識(OCR)だけでなく、矢印で示されたフローや関係性も含めてテキスト化されます。
さらに、「この表の内容をCSV形式で出力して」と指示すれば、Excelやスプレッドシートに直接貼り付けられる形式でデータを受け取ることも可能です。
単なる文字起こし以上の、構造化されたデータ変換ツールとして活用できます。
事例2:【音声→テキスト】会議録音からの議事録作成とタスク抽出
ビジネスにおいて最も需要の高い「音声入力」の活用例です。
Geminiは音声データを直接理解できるため、ICレコーダーやスマートフォンで録音した会議データをアップロードするだけで、高精度な議事録を作成できます。
「この音声データを聞いて、議論された主要な決定事項を3点にまとめてください」や「会話の中から、来週までに誰が何をすべきかというタスク(ToDo)を抽出してリスト化してください」といった指示が可能です。
Geminiは単に音声を文字に変換するだけでなく、話者の声のトーンや会話の流れから文脈を理解するため、「えーっと」などの不要な言葉(フィラー)を除去した要約や、感情の機微を汲み取った分析も可能です。
多言語会議の音声をアップロードして、日本語で要約してもらうといった使い方も効果的です。
事例3:【動画→テキスト】長尺動画の要約とシーン検索
1時間を超えるセミナー動画や、長時間の会議録画の内容を確認したい場合、最初から最後まで視聴するのは時間の浪費です。
Geminiに動画ファイルをアップロード(またはYouTubeのURLを入力)することで、動画の内容を素早く把握し、必要な情報だけを抜き出すことができます。
例えば、「この動画の全体的な要約を500文字以内で作成してください」といった基本的な要約指示に加え、特定のシーンを探し出すことも可能です。
これにより、動画全体を見直すことなく、必要な情報にピンポイントでアクセスできるようになります。
事例4:【テキスト→音声】オリジナルBGM・音楽の生成
テキストの指示から新しい音楽を作り出す機能です。
Googleの音楽生成AI技術(MusicFXなど)がGeminiのエコシステムに統合されつつあり、クリエイティブな制作活動を支援します。
「瞑想するための、リラックスできるローファイ(Lo-Fi)な曲を作って」や「アップテンポなジャズと電子音楽を融合させた、30秒のジングルを生成して」といったテキストプロンプトを入力することで、AIがそのイメージに合った楽曲を生成します。
インストゥルメンタル(楽器演奏のみ)やBGMの生成だけでなく、歌詞入りの歌(ボーカル曲)の生成も可能です。
動画のバックグラウンドミュージックや、プレゼンテーションのBGM作成において、著作権フリーのオリジナル音源を即座に用意できる点は大きなメリットです。
事例5:【テキスト→画像】資料用図解・インフォグラフィックの生成
プレゼンテーション資料やブログ記事を作成する際、内容をわかりやすく伝えるための図解や挿絵が必要になることがあります。
Geminiの画像生成機能を使えば、テキストの指示だけでオリジナルの素材を作成できます。
「AIが社会に与える影響を表現した、未来的で明るい色調のイラストを生成してください」や「スマートシティの概念図を、フラットデザインのアイコンを使って作成して」といった指示を出すことで、著作権を気にせず使える画像を生成可能です。
生成された画像がイメージと違う場合は、「もう少し青色を増やして」や「人物を削除して」といった追加の指示を出すことで、対話形式で修正していくことも可能です。
事例6:【テキスト→動画】ショート動画やプレゼン素材の生成
テキスト入力から数秒間の高品質な動画クリップを生成する活用事例です。
Googleの動画生成モデル(Veoなど)の技術がGeminiに統合され、言葉だけで映像を作り出すことが可能になりました。
例えば、「夕暮れ時の海岸をドローンで撮影したような、シネマティックな映像を生成して」や「未来的な都市を車が走るアニメーション動画を作って」と指示することで、SNSマーケティングに使えるショート動画や、プレゼンテーションのスライドに埋め込むための動画素材を瞬時に作成できます。
撮影機材や編集スキルがなくても、頭の中にあるイメージを具体的な映像として具現化できるため、クリエイターだけでなくビジネスパーソンの表現力も大きく拡張します。
🤔【検証】Geminiのマルチモーダルを試してみた

ここからは、実際にGeminiを使ってそのマルチモーダル性能を検証してみます。
今回は、実際にビジネスシーンを想定して、「手書き領収書のデータ化」と「動画内容のインフォグラフィック化」の2つに挑戦しました。
検証①:手書きの領収書を撮影してデータ化する
まずは、手書きの領収書をGeminiがどこまで正確に読み取り、デジタルデータとして構造化できるかを検証します。
添付する領収書画像は、以下になります。

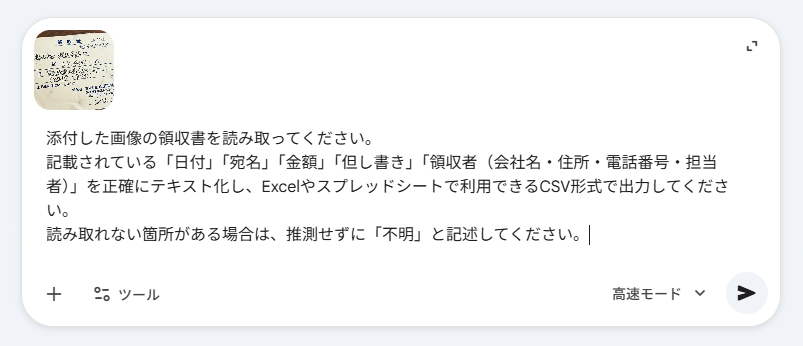
【検証プロンプト】
添付した画像の領収書を読み取ってください。
記載されている「日付」「宛名」「金額」「但し書き」「領収者(会社名・住所・電話番号・担当者)」を正確にテキスト化し、Excelやスプレッドシートで利用できるCSV形式で出力してください。
読み取れない箇所がある場合は、推測せずに「不明」と記述してください。
検証結果
上記のプロンプトを送信すると、以下の結果が生成されました。
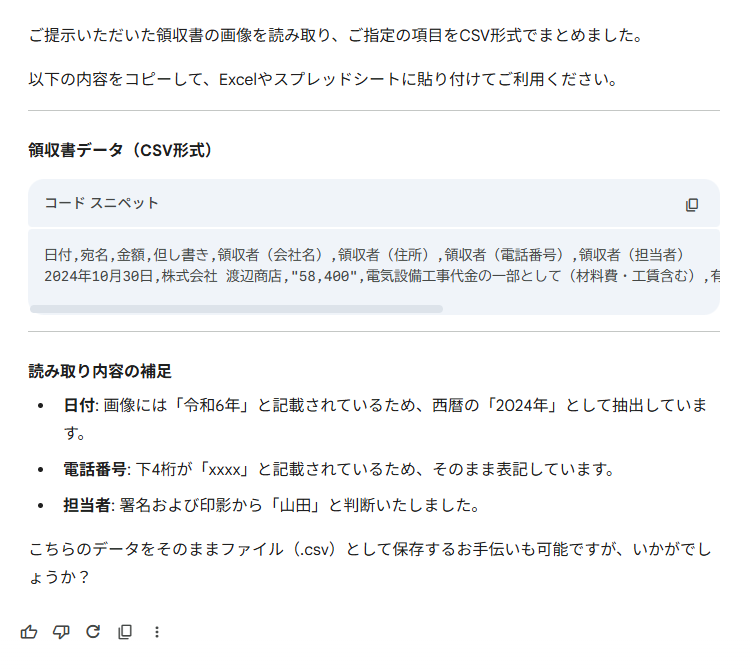
生成された結果から、以下のことがわかりました。
- 最軽量モデルの高速モードでも10秒未満で正確に手書き文字をデータ化
- 少し崩れた手書き文字(担当者名「山田」など)も高い精度で読み取り可能
- 表計算ソフトでそのまま使えるCSVファイルの生成とダウンロードに対応している
今回は手書きの領収書画像を読み込ませましたが、Geminiは最軽量モデルの高速モードを使用しても、10秒もかからずに正確なデータ化を実現しました。
従来のOCR(光学式文字認識)技術では、文字の大きさや記述のきれいさが読み取り精度に大きく影響しがちです。
しかし、Geminiのマルチモーダル機能であれば、担当者名の「山田」といった少し字体が崩れている手書き文字であっても、高い精度で読み取り、正確にテキストへ反映してくれることがわかりました。
画像からテキストデータを瞬時に抽出できるという、マルチモーダル対応ならではの高い利便性を実感できる結果です。
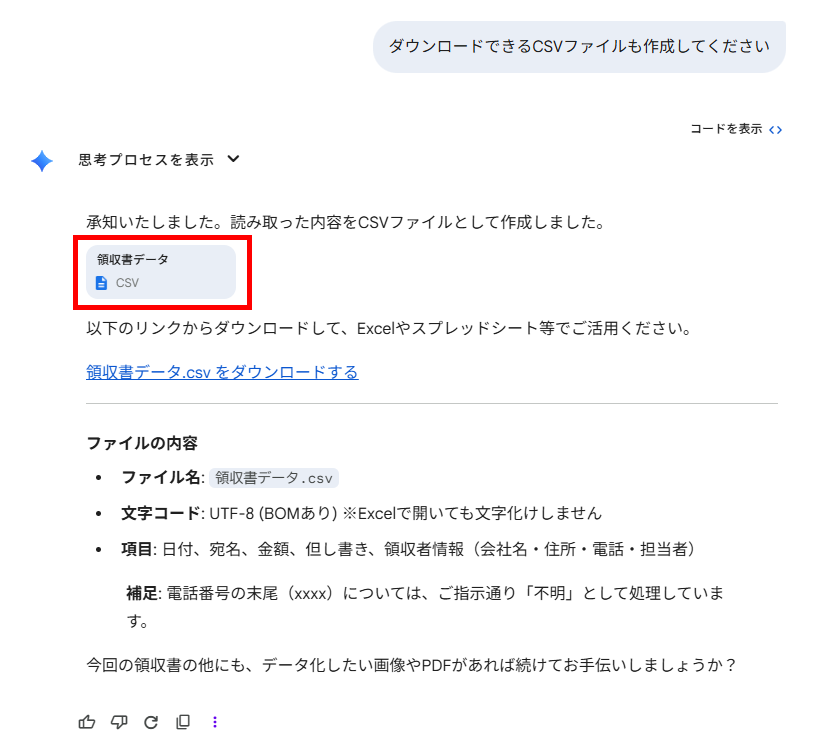
さらに、今回は画面上に直接生成されませんでしたが、指示をすればCSVファイル自体を出力し、そのままダウンロードして保存することも可能なため、経費精算などのビジネスシーンで大いに役立ちます。
検証②:YouTube動画からインフォグラフィック画像を生成する
次に、動画からインフォグラフィック(画像)を作成する高度なタスクに挑戦します。
ただし、執筆時点ではYouTube動画の内容を解析して、そのまま画像で出力することはできません。
そこで、動画から内容をテキストとして出力し、その後、画像を生成するというステップで行います。
動画は、YoomのYouTubeチャンネルで公開されているAIワーカーの解説動画を利用します。
【使用動画】
【初心者もOK】1つで10人分働くAIエージェントが登場!?色んなアプリを使いこなす「仕事」をするAIが登場しました【Yoom/AIワーカー】
【検証プロンプト1】
以下のYouTube動画の内容を1枚のインフォグラフィックにまとめたいです。
解説されている内容をまとめてください。
URL:https://youtu.be/gyhy0GSHgKs?si=w3wP3NDzUuhFnBSY
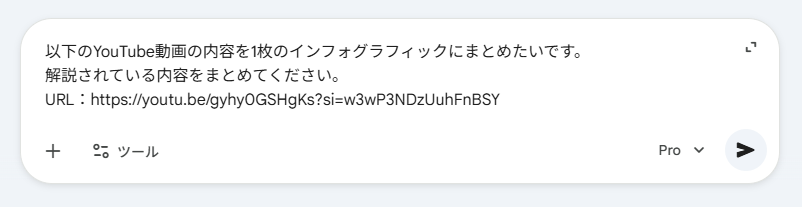
上記のプロンプトで、以下のように内容が解析されました。

【検証プロンプト2】
上記の内容をもとに、インフォグラフィックを作成してください。
画像内には「AIワーカー by Yoom」というタイトルを含めてください。
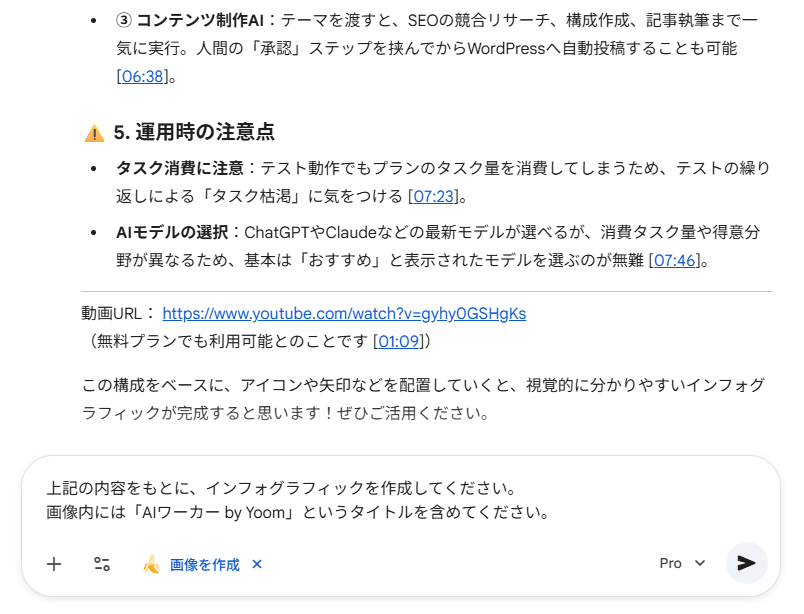
検証結果
上記のプロンプトで、以下のインフォグラフィックが作成されました。
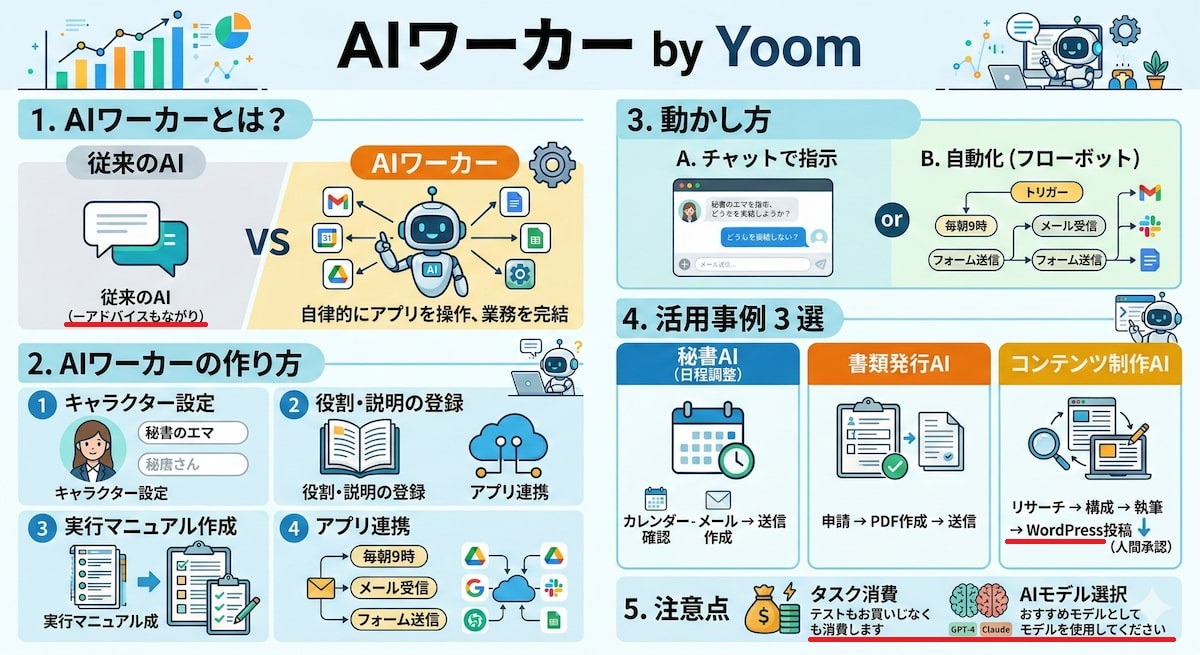
インフォグラフィックを作成してみて、以下のことがわかりました。
- 動画の要約と画像生成の2ステップを踏むことで、動画内容のインフォグラフィック化が可能
- 長時間の動画内容を視覚的にわかりやすくまとめたいシーンにおいて非常に有用
- 複雑な文字情報を画像に組み込む際、不自然な文章やレイアウトのズレが生じる場合がある
現在の仕様では動画から直接画像を生成できないため、一度動画をテキストで解析し、その内容をもとに画像を生成するという2ステップを踏みました。
少し手間はかかりますが、動画の内容をパッと見てわかるように視覚的にまとめたいシーンでは、有用性が高いと言えます。
一方で、生成された画像への文字入れには注意が必要です。
Geminiに搭載されている画像生成モデル「Nano Banana」は日本語の文字処理性能に優れていますが、今回のように複雑な文字情報を図解に組み込む指示を出すと、一部でおかしな文章になったり、指示とは異なる内容が表示されたりすることがあります。(画像内の赤線箇所)
また、矢印の位置関係がズレるなど、細かなレイアウトの調整がうまくいかないケースも見受けられるため、資料として活用する際は生成後の目視確認や手直しを前提として利用するのがおすすめです。
📉まとめ
Geminiのマルチモーダル機能は、AIの可能性を「テキスト処理」から「五感を使った認識」へと大きく広げました。
画像からスムーズにデータを抜き出し、動画から必要なシーンを見つけ出す能力は、私たちの情報処理のスピードを向上させます。
まだ発展途上の部分もありますが、今回の検証2のようにタスクを分けるなど、入力と出力を工夫することで、その活用方法は無限に広がります。
まずは手元にあるスマートフォンで写真を撮り、Geminiに話しかけることから始めてみてください。
その一歩が、新しい働き方への入り口になるはずです。
💡Yoomでできること
👉今すぐYoomに登録する今回検証したGeminiのマルチモーダル機能、実務で活かすなら「その先の業務フローごと自動化」まで考えたいところです。
YoomならAPIを通じてさまざまなツールをノーコードで連携できるため、画像解析→データ登録→通知といった一連の流れを自動化できるようになります。
たとえば、Google Driveにファイルが追加されたらAIが内容をチェックしてスプレッドシートに記録する、といったテンプレートもあるので、気になる方はぜひ触ってみてくださいね!
- AIワーカーを活用して、効率的なキャッチコピー作成のフローを構築したいと考えているマーケティング担当者の方
- 商品画像をもとに、複数のキャッチコピー案をスピーディーに生成したい商品企画担当者の方
- 生成したキャッチコピー案をkintoneで一元管理し、チームでの共有や活用を円滑に進めたい方
- フォームに画像をアップロードするだけで自動でキャッチコピーが生成されるため、プロンプトの考案や入力作業の時間を短縮できます
- 作成されたキャッチコピーは自動でkintoneに蓄積されるため、転記ミスを防ぎ、チームのナレッジとして情報を一元管理できます
- はじめに、kintoneとAIワーカーをYoomと連携する
- 次に、トリガーで、フォームトリガー機能を選択し、「フォームが送信されたら」というアクションを設定する
- 最後に、オペレーションで、AIワーカーのアクションを設定し、フォームで受け取った画像を解析してキャッチコピーを生成し、kintoneへ登録を行うためのマニュアル(指示)を作成する
■このワークフローのカスタムポイント
- フォームトリガーで設定するフォームは、画像だけでなく商品名やターゲット層など、キャッチコピー作成の参考となる項目を任意で追加できます
- AIワーカーに設定するマニュアル(指示)は、生成したいキャッチコピーのテイストや文字数、盛り込みたい要素など、目的に合わせて自由に編集してください
- kintoneとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- 契約書や利用規約などのコンプライアンスチェックに多くの時間を要している法務担当者の方
- 広告表現やクリエイティブのレギュレーション遵守を効率化したいマーケティング担当者の方
- AIエージェントを活用したコンプライアンスチェックの自動化を推進しているDX担当者の方
- Google Driveにファイルを格納するだけで自動でチェックが実行されるため、これまで目視での確認に費やしていた時間を短縮することができます。
- AIエージェントが規定のルールに基づきチェックを行うため、確認漏れや担当者ごとの判断のばらつきといったヒューマンエラーの防止に繋がります。
- はじめに、Google Drive、Google スプレッドシート、SlackをYoomと連携します。
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを起動し、アップロードされたファイルに対してコンプライアンスチェックとGoogle スプレッドシート、Slackへの情報出力を行うためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Google Driveのトリガー設定では、コンプライアンスチェックの対象ファイルが格納されるフォルダを任意で設定してください。
- AIワーカーに与える指示内容や、チェック結果の通知先となるSlackのチャンネル、または記録用のGoogle スプレッドシートのアカウントなどは任意で設定可能です。
- Google Drive、Google スプレッドシート、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
【出典】
Gemini API モデル/Gemini API のレート制限/Vertex AI の生成 AI モデル/Gemini アプリでファイルをアップロードして分析する - Android
プログラミング知識なしで手軽に構築できます。







