








・
Geminiの動画解析は仕事で使える?複数動画のポイント抽出で検証した実力

動画コンテンツが情報伝達の中心となる現代において、膨大な映像データから必要な情報を効率的に抽出する技術が求められています。
会議の録画、製品のデモ動画、教育用の教材など、ビジネスの現場では日々多くの動画が生成されていますが、それらをすべて視聴し、内容を確認するには多大な時間と労力を要します。
こうした課題を解決するのが、AIによる動画解析技術です。
Googleが提供するAIモデルのGeminiは、テキストだけでなく、画像、音声、動画を同時に理解するマルチモーダルな能力を持っています。
本記事では、Geminiを活用した動画解析の仕組みや具体的な手順、ビジネスでの活用事例、そして利用時の注意点について詳しく解説します。
✍️Geminiの動画解析機能(Video Understanding)とは

Geminiの動画解析機能は、単に動画内の音声を文字起こしするだけではありません。
映像に映っている物体、人物の動作、画面上のテキスト、そして音声のトーンや背景音までを含めた総合的な情報をAIが読み取り、理解する機能です。
これにより、人間が動画を見て内容を把握するのと同じように、AIも動画の「意味」を理解することができます。
Geminiの概要
Geminiは、Googleが開発した高度なマルチモーダルAIです。
このAIの最大の特徴は、テキスト・画像・音声・動画・コードなど、異なる種類の情報をネイティブに理解できる点です。つまり、事前に別の形式へ変換する必要がありません。
従来のAIでは、動画を解析する際にいくつかの前処理が必要でした。たとえば、動画を手動で分割したり、音声をテキストに変換したりするといった作業です。
一方、Geminiではこうした前処理を行わず、動画データをそのまま入力して処理することが可能です。
また、Gemini*非常に長いコンテキストウィンドウ(扱える情報量)を持っています。そのため、短い動画だけでなく、長時間の動画でも内容をまとめて理解できます。
例えば、次のようなコンテンツでも処理できます。
- 数分程度の短い動画
- 最大1時間程度の長尺動画
- 長時間の会議録画やストーリー性のある映像
このようなデータでも文脈を保ったまま内容を理解し、要約や質疑応答を行うことができます。
さらにGeminiは推論能力にも優れており、動画内の断片的な情報から状況を推測し、文脈を踏まえて論理的な結論を導くことも得意です。
このように、複数の情報を組み合わせながら高度な理解や分析を行える点が、Geminiの大きな特徴です。
解析の仕組み
Geminiが動画を解析する際、内部的には動画を「連続した画像フレーム」と「音声波形」の組み合わせとして処理しています。
具体的には、動画ファイルから1秒間に1フレームの画像をサンプリングし、同時に音声トラックを解析します。
この仕組みにより、音声がない動画(無音の防犯カメラ映像や、BGMのみのプロモーションビデオなど)であっても、映像内の動きや変化を捉えて内容を説明することが可能です。
逆に、映像の変化が少ない動画(スライドが固定されたままのプレゼンテーションなど)では、音声やスライド内の微細な文字情報を重点的に解析します。
さらに、マルチモーダルな理解力によって、「誰が(視覚情報)、何を言ったか(聴覚情報)」を正確に紐付けることができ、話者の特定や発言内容の属性分析も高い精度で行うことができます。
⭐Yoomは動画解析後の業務フローを自動化できます
Geminiを活用することで業務の効率化を図れますが、得られたテキストデータやインサイトを、実際の業務フローに組み込み、次のアクションへと繋げることで、真の自動化が実現します。
Yoomは、Geminiを含むさまざまなAIやSaaSアプリをノーコードで連携させ、複雑な業務フローを自動化するプラットフォームです。
例えば、Googleドライブに動画ファイルがアップロードされたタイミングで自動的にGeminiで解析を行い、その要約や議事録をSlackなどのチャットツールに通知するといったフローを構築できます。
これにより、手動でファイルをアップロードしたり、解析結果をコピー&ペーストして共有したりする手間が一切不要になります。
- Google Driveにアップされる画像の内容を定期的に確認・共有しているご担当者の方
- AIを活用して、画像に写っているオブジェクトの特定や説明文の生成を自動化したい方
- 日々の定型業務を効率化し、より創造的な業務に時間を割きたいと考えているすべての方
- Google Driveへの画像アップロードを起点に、Geminiでの解析とChatworkへの通知が自動で実行されるため、これまで手作業に費やしていた時間を短縮できます。
- 手作業による画像の見落としや、報告内容の転記ミスといったヒューマンエラーの発生を防ぎ、業務の正確性を高めます。
- はじめに、Google Drive、Gemini、ChatworkをYoomと連携します。
- 次に、トリガーでGoogle Driveを選択し、「新しくファイル・フォルダが作成されたら」というアクションを設定し、監視したいフォルダを指定します。
- 続いて、オペレーションでGoogle Driveの「ファイルをダウンロードする」アクションを設定し、トリガーで検知した画像ファイルを取得します。
- 次に、オペレーションでGeminiの「ファイルをアップロード」アクションと「コンテンツを生成(ファイルを利用)」アクションを設定し、画像の内容を解析させます。
- 最後に、オペレーションでChatworkの「メッセージを送る」アクションを設定し、Geminiが生成した内容を指定したチャットルームに通知します。
- Geminiの「コンテンツを生成(ファイルを利用)」アクションでは、どのような情報を画像から抽出したいか、プロンプトを自由にカスタマイズして設定することが可能です。
- Chatworkの「メッセージを送る」アクションでは、通知先のルームIDを任意で設定できるほか、メッセージ内容に固定のテキストを追加したり、Geminiの解析結果などの動的な値を埋め込んだりすることができます。
- Google Drive、Gemini、SlackのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
- Boxで管理しているドキュメントの内容把握を、より効率的に行いたいと考えている方
- Geminiを活用した自動化を導入し、情報収集のスピードを高めたい方
- 最新のAI技術を用いて定型的な確認作業を自動化し、業務の生産性を向上させたい方
- Boxへのファイルアップロードを起点に、Geminiが自動で要点を抽出するため、これまで手作業での確認に費やしていた時間を短縮することができます
- 大量のドキュメントの中から重要な情報を見落とすといったリスクを軽減し、Geminiが抽出した要点を基に、確実な情報把握が可能になります
- はじめに、GeminiとBoxをYoomと連携します
- 次に、トリガーでBoxを選択し、「フォルダにファイルがアップロードされたら」というアクションを設定します
- 次に、オペレーションでBoxの「ファイルをダウンロード」アクションを設定します
- 次に、オペレーションでGeminiの「ファイルをアップロード」アクションを設定します
- 次に、オペレーションでGeminiの「コンテンツを生成(ファイルを利用)」アクションを設定し、アップロードしたファイルから要点を抽出します
- 最後に、メール機能の「メールを送る」アクションを設定し、生成された要約を指定の宛先に送信します
■このワークフローのカスタムポイント
- Boxのトリガー設定では、自動化の監視対象としたいフォルダをコンテンツIDで任意に設定してください
- Geminiでコンテンツを生成するオペレーションでは、用途やファイルの特性に応じて任意のモデルを設定することが可能です
- Box、GeminiのそれぞれとYoomを連携してください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
✅Geminiで画像・動画解析を行う際の注意点と制限
Geminiは非常に強力なマルチモーダル解析能力を持っていますが、利用にあたっては倫理的な配慮や技術的な制約から、いくつかの重要な制限と注意点が設けられています。
これらを正しく理解し、適切に利用することで、予期せぬトラブルを防ぎ、AIの能力を最大限に引き出すことができます。
1.人物特定とプライバシーへの配慮
Geminiには、個人のプライバシーを保護するための厳格な制限が組み込まれています。
動画や画像内に映っている人物について、特定の個人名を同定したり、個人情報を抽出したりすることはできません。
例えば、「この動画に映っているのは有名人の〇〇さんですか?」といった質問や、「社員のAさんが映っているシーンを探して」といった指示に対しては、AIが回答を拒否するか、一般的な「人物」としての記述にとどめる挙動を示します。
これは、AI技術が生体認証や監視目的に悪用されることを防ぐための措置です。
動画解析を行う際は、特定の個人の追跡や特定を目的とするのではなく、あくまで動画全体の文脈理解や、行動・状況の把握(例:「プレゼンテーションを行っている男性」「赤い服を着て走っている人」など)に焦点を当てる必要があります。
また、解析結果を公開する場合も、映り込んでいる人々の肖像権やプライバシーに十分配慮し、必要に応じてぼかし処理などの対策を行うことが求められます。
2.著作権とコンテンツの取り扱い
Geminiを使用してYouTube動画や市販の映像コンテンツを解析する場合、著作権法や各プラットフォームの利用規約を遵守する必要があります。
YouTube動画を解析する際は、その動画が一般公開されている(Public設定である)ことが前提となります。
限定公開の動画については、チャット版では解析が拒否される場合がありますが、Google AI StudioやAPI経由での利用であれば、URLを指定することで限定公開動画の解析も可能です。なお、いずれの方法でも、完全にアクセスが制限された「非公開(Private)」の動画や有料コンテンツは解析できません。
また、AIによって生成された要約や分析結果を利用する際も注意が必要です。
元となる動画が第三者の著作物である場合、その要約をそのまま自社のコンテンツとして公開したり、商用利用したりすることは、著作権侵害にあたる可能性があります。
特に、動画内の創作的な表現(脚本、音楽、演出など)を詳細に描写した出力結果は、翻案権などの権利に関わる場合があります。
業務で利用する際は、自社が権利を持つ動画を使用するか、著作権者の許諾を得た上で解析を行うことが安全です。
3.動画ファイルのアップロード上限
Gemini(ブラウザ・アプリ版)およびAPI経由での動画解析には、読み込めるファイルサイズや動画の長さに物理的な上限があります。
-
動画の長さ
3.1 Proなどのモデルでは、1つの動画ファイルにつき最大1時間程度まで解析が可能とされています。
これを超える長尺動画の場合、解析が途中で打ち切られたり、エラーが発生したりする可能性があります。 -
ファイルサイズ
直接アップロードする場合、API利用時は1ファイルあたり2GBが上限となっています。
チャット版では、より低い制限(100MB)が適用されます。
これを超える高画質な動画などは、あらかじめ圧縮するか、分割して読み込ませる必要がある点に注意が必要です。 -
ファイル数
1つのプロンプト(チャット)で同時に処理できる動画ファイル数にも制限があり、通常は最大10ファイル程度までとなっています。
なお、APIを利用する場合、これらの制限は「コンテキストウィンドウ(トークン数)」にも依存します。
動画は画像フレームと音声に分解されてトークン化されるため、解像度やフレームレートが高い動画は、時間が短くても多くのトークンを消費し、モデルの上限(例:100万トークン)に達してしまう場合があります。
4.技術的な解析仕様と精度(サンプリングレート・ハルシネーション)
Geminiの動画解析は、動画の全フレームを連続して見ているわけではなく、一定の間隔で画像を間引いて認識しています。
-
サンプリングレート
通常、1秒間に1フレーム(1fps)の頻度で画像として認識します。
そのため、1秒未満の一瞬の出来事(サブリミナル的な映像や、極めて高速な動き)は認識されない可能性があります。 -
ハルシネーション(誤認)
AIモデル全般に言えることですが、事実とは異なる情報を生成してしまう「ハルシネーション」が発生する可能性があります。
特に、画質が悪い動画、照明が暗いシーン、音声が不明瞭な箇所では認識精度が低下しやすくなります。
画面内の小さな文字を読み間違えたり、人物の動作を見誤ったりすることもあるため、重要な情報については必ず元の動画を目視で確認するフローを設けることが重要です。
🖊️Geminiで実現できる動画解析の活用事例

Geminiを動画の解析に利用することで、さまざまな業務が効率化されます。
具体的な活用事例を知っておくことで、活用の幅はさらに広がります。
1.長時間動画の要約と議事録作成
1時間を超えるような定例会議やウェビナーの録画データをGeminiにアップロードすることで、会議の要点や決定事項を瞬時に抽出できます。
従来、録画データを見直して議事録を作成するには、動画の再生時間以上の作業時間が必要でしたが、Geminiを使えばその時間を数分に短縮できます。
また、単なる会話の文字起こしだけでなく、「誰がどのような発言をしたか」という話者分離や、「次のアクションアイテムは何か」といったタスクの抽出も可能です。
映像内のホワイトボードに書かれた文字や、共有されたスライドの内容も解析対象となるため、音声だけでは拾いきれない情報も補完された、質の高い議事録が自動生成されます。
これにより、会議に参加できなかったメンバーへの情報共有もスムーズに行えます。
2.特定シーンの検索・抽出
膨大な動画アーカイブの中から、必要な情報が含まれているシーンだけをピンポイントで見つけ出すことができます。
例えば、製品のユーザーテストの録画データが数十時間分ある場合、「ユーザーが操作に迷っているシーン」や「エラー画面が表示された瞬間」などをGeminiに検索させることができます。
Geminiは「15分30秒付近で、画面右上にエラーメッセージが出ています」といったように、該当するタイムスタンプとともに結果を提示します。
これにより、動画全体を視聴することなく、改善が必要な箇所だけを効率的にピックアップできます。
カスタマーサポートにおける通話録画の分析や、教育現場での授業動画の見直しなど、特定のトピックや状況を素早く参照したい場面で非常に有効です。
3.操作マニュアルの作成支援
PCの画面操作を録画した動画を元に、ソフトウェアや業務システムのマニュアルを作成する作業も、Geminiによって効率化できます。
操作画面のキャプチャ動画をGeminiに読み込ませ、「この動画の手順をステップバイステップで説明するマニュアルを作成してください」と指示するだけで、操作の流れを記述したテキストが生成されます。
Geminiは画面上のボタン名やメニュー項目、入力されたテキストなどを視覚的に認識するため、「『設定』メニューをクリックし、『ユーザー管理』を選択します」といった具体的な指示を含んだマニュアルを作成できます。
人間がいちいちスクリーンショットを撮り、説明文を考える手間が省け、動画が誰でも簡単に高品質なマニュアルを作成できるようになります。
📜動画解析機能の使い方

Geminiで動画解析を行う場合、チャット版以外でも利用できます。
ここでは、プラットフォームごとに、Geminiで動画を解析する方法を解説します。
Gemini(チャット)での利用
一般のビジネスパーソンや個人ユーザーにとって最も手軽な方法は、ブラウザ版のGemini(gemini.google.com)やスマートフォンアプリを利用することです。
直感的なインターフェースで、専門的な知識がなくてもすぐに動画解析を始められます。
利用手順は非常にシンプルです。
まず、Geminiのチャット画面を開き、入力欄にある「+」ボタン(または画像アップロードアイコン)をクリックします。
そこからローカルに保存されている動画ファイルを選択してアップロードするか、解析したいYouTube動画のURLをプロンプト入力欄に貼り付けます。
動画の読み込みが完了したら、「この動画を要約してください」「○○について話している箇所を教えて」といった指示をテキストで入力し、送信します。
数秒待つだけで、AIからの回答が得られます。
Google AI Studio / Vertex AIでの利用
エンジニアや開発者が、自社のアプリケーションに動画解析機能を組み込んだり、大量の動画データをバッチ処理したりする場合は、Google AI StudioまたはGoogle CloudのVertex AIを利用します。
これらのプラットフォームでは、GeminiのAPI(Application Programming Interface)を通じて機能を利用できます。
Google AI Studioは、プロトタイピングや実験的な利用に適した開発環境です。
Webブラウザ上でAPIキーを取得し、GUIベースでモデルのパラメータ調整やプロンプトのテストを行えます。
動画ファイルをアップロードし、Gemini 3.1 Proなどのモデルを選択して実行ボタンを押すだけで、API経由での解析結果を確認できます。
一方、Vertex AIは、より大規模な商用利用や、セキュリティとガバナンスが重視されるエンタープライズ環境向けです。
Pythonなどのプログラミング言語を使ってコードを記述し、システムの一部として動画解析プロセスを統合することが可能です。
🤔【検証】GeminiにYouTube動画を解析させてみた

Geminiの実力を確かめるため、実際にYouTubeで公開されている動画を読み込ませ、その内容を解析できるか検証を行いました。
今回は、Yoomの公式チャンネルで公開されている以下の5本の動画を対象とします。
1本8~10分の動画で、合計約45分の動画を一度に処理できるかを検証しました。
検証内容
今回は、Google AI Proプランを利用して、YouTube動画を要約してもらいます。
動画は、Yoomのチャンネルで公開されている以下の動画を利用します。
【検証動画】
- 【必見】Xのポスト考えるのは卒業🌸 毎日の投稿を完全自動化する方法を紹介します【Yoom】
- 【最新AIブラウザ】OpenAIからChatGPT Atlas登場!より精度上がる使い方は〇〇一択!?
- 【初心者もOK】1つで10人分働くAIエージェントが登場!?色んなアプリを使いこなす「仕事」をするAIが登場しました【Yoom/AIワーカー】
- 【OCR】Gemini vs ChatGPTで文字起こし機能徹底比較!精度が高いAIは〇〇です。【AI文字起こし】
- 【2026最新版】GeminiとGoogleカレンダー連携で、スケジュール管理の完全自動化!さらなる活用法も!【Yoom】
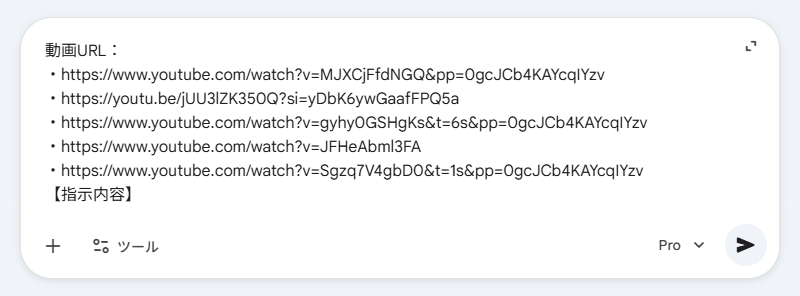
【検証プロンプト】
以下のYouTube動画の内容を解析してください。
動画URL:【指示内容】
- https://www.youtube.com/watch?v=MJXCjFfdNGQ&pp=0gcJCb4KAYcqIYzv
- https://youtu.be/jUU3lZK350Q?si=yDbK6ywGaafFPQ5a
- https://www.youtube.com/watch?v=gyhy0GSHgKs&t=6s&pp=0gcJCb4KAYcqIYzv
- https://www.youtube.com/watch?v=JFHeAbml3FA
- https://www.youtube.com/watch?v=Sgzq7V4gbD0&t=1s&pp=0gcJCb4KAYcqIYzv
それぞれの動画のポイントを3つ箇条書きでまとめてください
検証結果
上記のプロンプトで検証したところ、以下の結果となりました。

解析結果から、以下のことがわかりました。
- 合計45分の動画をわずか1分ほどで処理する圧倒的な解析スピード
- 字幕や音声を認識し、文脈に合わせて自然な表現に言い換える高い理解力
- 情報の抜け漏れが生じるケースがあり、解析精度はまだ完璧ではない
合計45分にも及ぶ5本の動画を、わずか1分程度で解析できたことは非常に魅力的です。
動画視聴にかかる時間を大幅に削減し、ストレスのない業務効率化が期待できます。
また、単なる文字起こしにとどまらず、字幕や音声を認識し、文脈を深く理解している点も優秀です。
例えば、1つ目の動画内にある「セミオート運営」という言葉を、より一般的な「ハイブリッド運営」と言い換えるなど、自然で親しみやすい要約が作成されていました。
一方で、解析精度は完璧ではない点に注意が必要です。
2つ目の動画では、実際には4つの機能が紹介されているにもかかわらず、「強力な3つの機能」と要約されるなど、一部の情報に抜け漏れが発生していました。
Geminiの動画解析をビジネスで活用する際は、AIの出力結果をそのまま使用するのではなく、重要な数字や要素について人間の目で最終確認を行うプロセスを取り入れることをおすすめします。
📉まとめ
Geminiの動画解析機能は、ビジネスにおける動画活用の可能性を大きく広げる革新的な技術です。
長時間の会議動画からの議事録作成、膨大な映像アーカイブからの情報検索、そしてマニュアル作成の自動化など、その応用範囲は多岐にわたります。
マルチモーダルな理解力と長いコンテキストウィンドウを持つGeminiは、動画の内容を人間と同じように、あるいはそれ以上の速度と精度で把握することを可能にします。
しかし、その能力を最大限に引き出し、実際のビジネス成果に繋げるためには、単にツールを使うだけでなく、業務フロー全体を最適化する視点が不可欠です。
Yoomのような自動化プラットフォームと組み合わせることで、動画解析を日々の業務に自然な形で組み込み、生産性の向上に繋がります。
ぜひ、GeminiとYoomを活用して、新しい時代の業務効率化を実現してください。
💡Yoomでできること
Yoomを活用することで、Geminiの動画解析機能を既存の業務フローにシームレスに統合できます。
動画データの移動、解析の実行、結果の通知といった一連のプロセスを自動化することで、人間の作業ミスを減らし、業務スピードを向上させることができます。
例えば、以下のようなフローボットを作成することが可能です。
■このテンプレートをおすすめする方
- フォームからの問い合わせやアンケート回答の管理に手間を感じている担当者の方
- Geminiなどの生成AIを活用して、テキストの要約や整理を自動化したい方
- フォームの回答をGoogle スプレッドシートで管理しており、転記作業をなくしたい方
■このテンプレートを使うメリット
- フォームへの回答からGeminiでの要約、Google スプレッドシートへの記録までが自動化され、手作業での確認や転記にかけていた時間を短縮できます。
- 手作業による情報の転記ミスや要約内容のブレを防ぎ、データの正確性と業務の均質化に繋がります。
■フローボットの流れ
- はじめに、GeminiとGoogle スプレッドシートをYoomと連携します。
- 次に、トリガーでフォームを選択し、「回答が送信されたら」というアクションを設定します。
- 次に、オペレーションでGeminiの「コンテンツを生成」アクションを設定し、フォームの回答内容を要約するよう指示します。
- 最後に、オペレーションでGoogle スプレッドシートの「レコードを追加する」アクションを設定し、Geminiが生成した要約結果を指定のシートに追加します。
■このワークフローのカスタムポイント
- トリガーとなるフォームでは、アンケートや問い合わせなど、用途に合わせて質問項目を自由に設定してください。
- Geminiのアクションでは、要約の精度や形式を調整するために、プロンプトや使用するモデルを任意で設定することが可能です。
- Google スプレッドシートのアクションでは、データを記録したい任意のスプレッドシートIDやシート名を指定してください。
■注意事項
- Gemini、Google スプレッドシートのそれぞれとYoomを連携してください。
■概要
フォームからの問い合わせやアンケートの回答内容は重要な情報ですが、その一つ一つを確認し、要点をまとめてデータベースに入力するのは時間と手間のかかる作業ではないでしょうか。このワークフローを活用すれば、フォームに回答が送信されると、その内容をGeminiが自動で要約し、Notionのデータベースに新しい項目として追加できます。これにより、情報整理の手間を省き、迅速な情報共有と管理を実現します。
■このテンプレートをおすすめする方
- フォームからの問い合わせやアンケート結果の確認・転記作業に時間を要している方
- Geminiを用いて、大量のテキスト情報を効率的に要約し、業務に活用したい方
- Notionを情報集約のハブとして利用しており、手入力の手間をなくしたい方
■このテンプレートを使うメリット
- フォーム回答の確認から要約、Notionへの入力までが自動化され、手作業に費やしていた時間を短縮し、より重要な業務に集中できます。
- 手作業による情報の転記ミスや要約の抜け漏れを防ぐことができ、Notionに蓄積される情報の正確性を担保します。
■フローボットの流れ
- はじめに、GeminiとNotionをYoomと連携します。
- 次に、トリガーでフォームトリガー機能を選択し、「フォームが送信されたら」というアクションを設定し、ワークフローの起動条件を定めます。
- 次に、オペレーションでGeminiの「コンテンツを生成」アクションを設定し、フォームで受け取った回答内容を要約するよう指示します。
- 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、Geminiが生成した要約を指定のデータベースに追加します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガー機能では、テキストボックスやチェックボックスなどの質問項目を自由に設定し、用途に合わせた入力フォームを作成できます。
- Geminiのコンテンツ生成アクションでは、フォームから受け取った情報を基に要約や分析を行うためのプロンプトを自由にカスタマイズできます。
- Notionへのレコード追加アクションでは、どのデータベースに追加するかを指定し、各プロパティにフォームの回答やGeminiの生成結果などを割り当てることができます。
■注意事項
- GeminiとNotionそれぞれとYoomを連携してください。
営業担当者が商談の録画データをフォームに送信するだけで、Yoomがそれを検知してGeminiに送り、生成された内容が自動的にデータベースに保存される。
そのような新しい働き方を、Yoomは今すぐ実現します。
【出典】
Google Gemini/Google AI for Developers/Vertex AI Platform | Google Cloud
プログラミング知識なしで手軽に構築できます。







