・
DifyでのRAGの使い方を検証|経費精算規定のテストで業務への導入可否を判断

自社のマニュアルや独自データをAIに回答させたいけれど、やり方がわからないとお悩みではありませんか?本記事では、非エンジニアでも簡単にRAG環境を構築できるDifyのナレッジベース機能について、具体的な設定手順から回答精度の高め方まで初心者向けにわかりやすく解説します。
🤖 DifyとRAG(検索拡張生成)の基礎知識

DifyとRAGに関する基本的な概念を整理します。自社独自のAIチャットボットを開発する上で、これらの仕組みを正しく理解することは重要です。まずはそれぞれの役割や導入するメリットについて見ていきましょう。
Difyとは?ノーコードでAIアプリを作れるプラットフォーム
DifyはエンジニアでなくてもGUIを中心にAIアプリを構築できる開発プラットフォームです。複雑なコードを書くことなく、様々なLLMを組み合わせて自社専用のアプリケーションを短期間でリリースできるため、多くの企業で導入が進んでいます。
具体的には以下の特徴があります。
- ノーコード開発環境:
ドラッグ&ドロップなどの直感的な操作のみで、自社要件に合わせたチャットボットやエージェントなどのアプリを素早く構築できます。 - 豊富なモデル対応:
OpenAIやAnthropicなど、複数の主要なLLM(大規模言語モデル)を一つのプラットフォーム上でシームレスに切り替えて利用することが可能です。
RAG(検索拡張生成)とは?社内データをAIに読み込ませる仕組み
RAGとは、外部のデータベースから関連する情報を検索し、その内容をAIに渡すことで精度の高い回答を生成させる技術です。LLMが事前に学習していない社内規定や独自のドキュメントに基づいた回答を行えるようになります。
主に以下のステップで処理が実行されます。
- 情報の検索(Retrieval):
ユーザーからの質問を受け取ると、あらかじめ取り込んでおいたデータベース(ナレッジベース)から関連する情報を探し出します。 - プロンプトの拡張(Augmented):
検索して見つけた社内データなどの文脈を、ユーザーの質問と組み合わせてLLMに渡すための新しいプロンプトを作成します。 - 回答の生成(Generation):
拡張された情報を基に、LLMがより正確で根拠に基づいた自然な回答テキストをユーザーに向けて出力します。
既存のChatGPTなどでは解決できない課題とRAGのメリット
通常のChatGPTなどの生成AIでは、学習データに含まれていない社内独自のルールには正しく答えることができず、ハルシネーション(もっともらしい嘘)を引き起こす課題があります。RAGを導入することで、自社データに基づく信頼性の高いAIを運用できるようになります。
具体的なメリットは以下の通りです。
- 専門的な問い合わせへの対応:
社内マニュアルや製品仕様書を読み込ませることで、自社特有の専門的な質問に対しても正確な回答を提示できます。 - 情報の秘匿性とセキュリティ確保:
公開されているLLMに機密情報を直接学習させることなく、クローズドな環境内で安全に社内データを参照させることが可能です。
🔌YoomはRAG構築といった様々な業務フローを自動化できます
Difyを利用することで、非エンジニアでもRAGの構築が可能になります。それでも、業務全体では、問い合わせ対応を完了したときにデータベースでステータスを更新したり、対応漏れの確認をしたり、問い合わせ内容を分析したりと、多くの作業がありますよね。時間に追われる状況で、こうした手作業による定型業務を省けたら、と思ったことがある方は多いのではないでしょうか?
Yoomを利用すれば、AIや業務ツールをノーコードで連携できるため、RAGをはじめ様々な自動化フローを構築することが可能です。これには、以下のようなメリットがあります。
- 様々なデータベースツールを参照先として設定可能
- タスクのステータスを更新するだけで関連する業務ツールの情報も自動更新
- 一度の設定でリマインド通知や定期的な問い合わせ分析・レポート作成を自動化
- ヒューマンエラーを削減しながら1案件にかかる時間を短縮
導入により新規顧客対応や契約書関連の確認業務を50%削減している事例もあります。
[Yoomとは]
直感的な設定だけで柔軟なフローを構築できるため、業務に合わせたカスタマイズもノーコードで行えます。無料プランや以下のようなテンプレートも豊富に用意されており、気軽に試すことができるので、自動化による新しい働き方をぜひ体験してみてください。
■このテンプレートをおすすめする方
- Zendeskを用いたカスタマーサポート業務において、問い合わせ対応の効率化と無人化を推進したい担当者の方
- 製品の仕様やFAQをNotionで管理しており、それらを活用して問い合わせ回答の質を安定させたいチームリーダーの方
- 過去のナレッジを有効活用しつつ、サポートデスクの運用工数を削減し、効率的な組織運営を目指す経営者の方
■このテンプレートを使うメリット
- Zendeskに届いた問い合わせに対し、AIがNotionの情報を基に回答案を作成するため、顧客へのレスポンス時間を短縮できます。
- Notionに蓄積された正確なナレッジを基にAIが回答を生成することで、回答の質を一定に保ち、担当者による知識の差を埋めることが可能です。
■フローボットの流れ
- はじめに、Zendesk、Notion、SlackをYoomと連携します。
- 次に、トリガーで、Zendeskを選択し、「チケットが作成されたら」というアクションを設定します。
- 次に、AIワーカーで、顧客からの問い合わせに対し、Notionのナレッジを基に回答案を作成するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- AIワーカーのマニュアル設定にて、どのようなトーンで回答を作成するか、または特定のキーワードが含まれる場合にどのような処理を行うかなど、指示を詳細にカスタマイズしてください。
- Notionでのナレッジ参照先を、FAQページやマニュアルが格納されている特定のデータベースやページに指定することで、より精度の高い回答案が作成できます。
- Slackでの通知設定では、AIが作成した回答案をまず担当者が確認できるよう、通知先のチャンネルやメッセージ内容を任意に設定してください。
■注意事項
- Zendesk、Notion、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Zendeskは、ミニプラン以上でご利用いただけるアプリとなっております。フリープラン・パーソナルプランの場合は設定しているフローボットのオペレーションやデータコネクトはエラーとなりますので、ご注意ください。
- ミニプラン・チームプラン・サクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリを使用することができます。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
■このテンプレートをおすすめする方
- 膨大な問い合わせデータの集計や分析、週次レポートの作成に課題を感じているカスタマーサポート担当者の方
- Google スプレッドシートとSlackを併用しており、データの要約から通知までを自動化したいと考えているチームリーダーの方
- 顧客の声を迅速にサービス改善へ活かしたいが、分析リソースの不足に悩んでいる経営者の方
■このテンプレートを使うメリット
- AIワーカーが問い合わせデータを一括分析し、頻出課題や顧客の感情を抽出するため、手作業で行っていた分析時間を短縮できます。
- 定期的に分析レポートがSlackへ自動通知されることで、チーム全体での現状把握がスムーズになり、FAQの改善や顧客満足度の向上に繋がります。
■フローボットの流れ
- はじめに、Google スプレッドシート、Notion、SlackをYoomと連携します。
- 次に、特定の時間にスケジュール実行するトリガーを設定します。
- 最後に、蓄積された問い合わせデータを分析し頻出する課題や顧客の感情を可視化して、レポートを作成するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Google スプレッドシートのアクション設定では、分析対象とするデータの範囲や抽出条件を、運用に合わせて任意に調整してください。
- AIワーカーの指示(プロンプト)を調整することで、要約の粒度や抽出したい特定の項目(改善案、ネガティブな意見など)をカスタマイズできます。
- Slackの通知先チャンネルを、用途に合わせてカスタマーサクセス用や開発チーム用など任意で設定してください。
■注意事項
- Google スプレッドシート、Notion、SlackのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- AIワーカー内で20件を超える大容量データの取得やループ処理を行うと、タスクを著しく消費する可能性があるためご注意ください。
📂Difyでナレッジベースを作成する基本手順
実際にDifyを使ってナレッジベースを構築し、AIに社内データを学習させるまでの流れを解説します。ファイルのアップロードからインデックス化まで、大きく4つのステップで完了します。
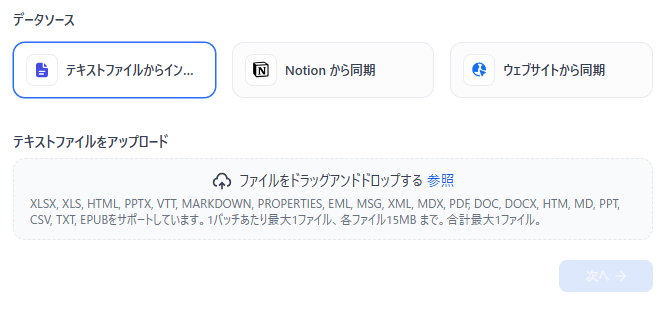
STEP1:データソースの取り込み
ナレッジベース構築の第一歩は、AIに参照させたい元となるデータソースを取り込むことです。Difyでは複数のデータ形式に対応しており、手元のファイルだけでなく外部ツールとの連携も可能です。
具体的には以下の取り込み方法が用意されています。
- ファイルのアップロード:
PDF、Word、TXTなどを含む複数形式のドキュメントを直接アップロードできます(1ファイルあたり最大15MBまで対応)。 - 外部サービスとの直接同期:
Notionのワークスペースと連携してページを取り込んだり、拡張機能を用いてWebサイトの情報をリアルタイムに同期させたりできます。
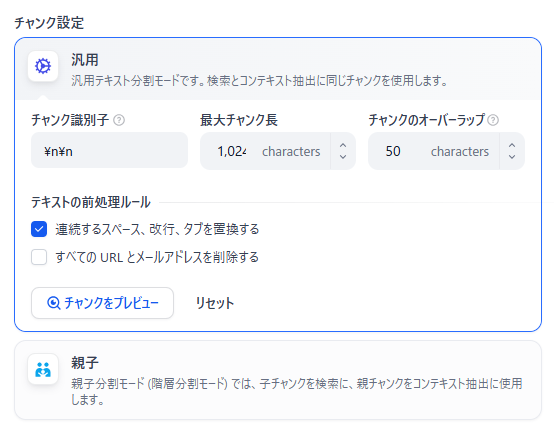
STEP2:テキストのチャンク設定
データソースを取り込んだ後は、AIが情報を検索しやすいように文章を「チャンク」と呼ばれる細かなブロックに分割する設定を行います。適切なサイズに分割することで、検索時のヒット率と回答精度が大きく向上します。
主に以下の設定項目が存在します。
- 分割方法の選択:
システムが適切に区切ってくれる自動設定のほか、区切り文字やサイズを自社の好みに合わせて指定できるカスタム設定を選択できます。 - チャンクサイズとオーバーラップ:
文字数の上限(チャンクサイズ)や、前後の文脈を途切れさせないための重複部分(オーバーラップ)の割合を細かく調整します。
STEP3:インデックス方法と埋め込みモデルの選択
チャンクに分割したテキストを検索できるようにするため、インデックス方法を設定します。方法によって、設定が異なります。
具体的には以下の設定があります。
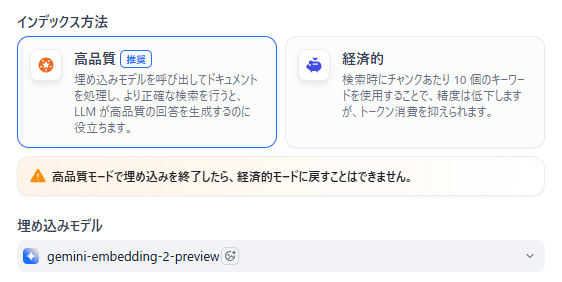
- インデックス方法の指定:
システムの用途や予算に合わせて「高品質」または「経済的」を選択します。高品質モードでは、さらにベクトル検索・全文検索・ハイブリッド検索といった検索方式を利用可能です。 - 埋め込みモデルの割り当て:
高品質モードでは、OpenAIやGoogleなどのプロバイダーが提供する様々なEmbeddingモデルの中から、自社の要件に合ったものを一つ選定して適用します。
STEP4:検索設定の最適化と完了
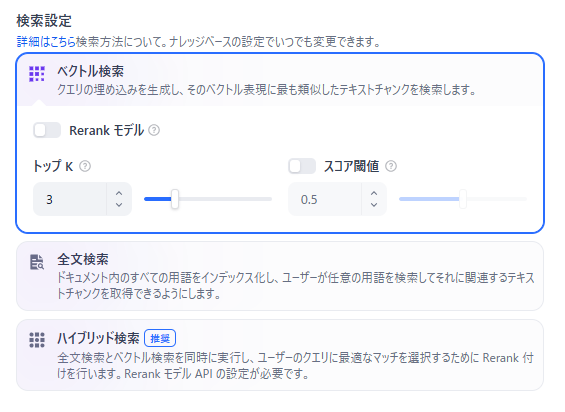
最後に、ユーザーが質問を入力した際に、インデックス化されたデータからどのように回答の候補を引っ張ってくるかという検索アルゴリズムを決定します。設定完了後に保存ボタンを押すことで、ナレッジベースが正式に利用可能になります。
主に以下の検索方式が挙げられます。
- ベクトル検索による意味の抽出:
ユーザーの質問とナレッジベース内のテキストの意味的な近さを計算し、文脈が一致する情報を優先的に取得します。 - 全文検索によるキーワード一致:
質問に含まれる特定の単語がテキスト内に存在するかどうかを判定し、完全一致する情報を素早く見つけ出します。
⚙️ナレッジベースの精度を左右する設定ポイント
ナレッジベースを構築する際、チャンク設定やインデックス方法の選び方によってチャットボットの回答精度が大きく変わります。ここでは、各設定モードの具体的な違いや、モデルの適切な使い分けについて詳しく解説します。
チャンク設定(テキスト分割):「汎用モード」と「親子モード」の違い
チャンク設定ではドキュメントの複雑さに応じてモードを使い分ける必要があります。システムの用途や予算に合わせて最適な方式を選ぶことが、回答精度の向上に直結します。

Difyにおけるチャンクの分割方式は、それぞれに独自の強みを持っています。用途に応じて柔軟に切り替えることで、検索のヒット率を最大化できます。
それぞれのモードにおける具体的な特徴とメリットは以下の通りです。
- 汎用モード(シンプルな検索向け):
テキストを最大1024文字などの固定サイズで均等に分割します。設定がシンプルで処理スピードが速いため、用語集や短いFAQデータなどの検索に適しています。 - 親子モード(文脈を維持する高度な設定):
検索用の小さな子チャンクと、LLMに文脈を渡すための大きな親チャンクを分けて管理します。情報を渡す際に前後の文脈が途切れにくいため、複雑な社内規定の読み込みに最適です。
インデックス方法:「高品質」モード(推奨)と「経済的」モードの違い
インデックス作成時も、利用する検索アルゴリズムやコストに応じたモード選択が回答の正確性に影響を与えます。Difyでは、コストを抑える方法と精度を追求する方法の2種類が提供されています。

システムを本格的に運用していくためには、それぞれの特性を正しく把握しておく必要があります。特にランニングコストと精度のトレードオフを理解することが大切です。
これらのモードに関する詳細な特徴と注意点は以下の通りです。
- 高品質モード(推奨される方式):
Embeddingモデルを利用してテキストをベクトル化し、意味的な類似性を活用した検索を実行します。なお、公式仕様では高品質で作成した知識ベースを後から経済的モードへ切り替えることはできません。 - 経済的モード(コストを抑えた方式):
逆インデックスを用いたキーワードベースの検索を行います。外部Embeddingモデルを使わないため、追加の埋め込みコストを抑えやすいのが特徴です。
代表的な埋め込みモデルの特徴と使い分け
埋め込みモデル(Embeddingモデル)は、テキストをAIが理解できる数値データに変換する重要な役割を担っており、プロバイダーごとに性能が異なります。言語の対応状況やトークン単価などを基準に、最適なものを選択することが重要です。
主に以下の代表的なモデルが挙げられます。
- OpenAIのテキスト埋め込みモデル:
「text-embedding-3-small」などは、多言語への対応力とコストパフォーマンスのバランスに優れており、迷った際の標準的な選択肢としておすすめです。 - GoogleのGemini埋め込みモデル:
「gemini-embedding-2-preview」などは、特に複雑な文脈や長文のテキストを正確にベクトル化したい場面で高いパフォーマンスを発揮します。 - Cohereなどその他の特化型モデル:
特定の言語領域や専門用語に強みを持つモデルも存在し、多言語が混在するグローバルな社内規定などを読み込ませる際に独自の強みを発揮します。
🔍回答精度を高める検索設定とRerankモデル
ナレッジベースの検索設定は、ユーザーの質問に対してどれだけ正確な参考資料を引き出せるかを決定する最終的な調整部分です。ここでは、ベクトル検索と全文検索の違いや、Rerank(再ランク付け)モデルを用いた精度の底上げについて解説します。
ベクトル検索と全文検索の違い
検索設定においては、AIが情報を探すアプローチとしてベクトル検索と全文検索という2つの異なる技術が存在します。ユーザーが入力する質問の性質に合わせて、どちらの検索方法をベースにするかを理解することが大切です。

それぞれの検索方法には得意な領域があり、用途によって使い分けることが推奨されます。ユーザーがどのような形で質問を投げかけてくるかを想定して設定することがおすすめです。
両者の特徴的な違いは以下の通りです。
- ベクトル検索による意味検索:
ユーザーの質問の「意味や意図」を数値化してナレッジベースと照合します。例えば「パソコンが動かない」という質問に対し、「PCのフリーズ」という異なる単語のドキュメントを引き当てることが可能です。 - 全文検索による完全一致検索:
ユーザーの質問に含まれる「特定のキーワード」がドキュメント内に存在するかどうかを直接探し出します。型番や専門的な製品名など、一言一句正確に一致する情報を探す際に威力を発揮します。
ハイブリッド検索とRerankモデルを組み合わせて精度向上を図る方法
検索ヒット率を最大化するためのベストプラクティスは、ベクトル検索と全文検索を融合させた「ハイブリッド検索」を利用し、さらに「Rerankモデル」で結果を最適化することです。この組み合わせにより、単一の検索手法のみを使う場合よりも、検索結果の関連性や回答精度の向上が期待できます。
具体的には以下の仕組みが働きます。
- ハイブリッド検索による広範な情報収集:
ベクトル検索の意味理解(重み0.7等)と全文検索のキーワード一致(重み0.3等)を組み合わせることで、漏れなく関連ドキュメントを収集します。 - Rerankモデルによる再評価と並び替え:
集めた複数のドキュメント候補に対し、Rerankモデルがユーザーの質問との関連性を改めて精査・スコアリングし、最も適切な順番に並び替えてからLLMに渡します。
📱作成したナレッジベースをアプリに組み込む方法

完成したナレッジベースは、Dify上のチャットボットやワークフローなどのアプリケーションに紐付けることで初めて機能します。ここでは、作成したナレッジベースを実際のアプリに組み込んで利用する具体的な手順を解説します。
チャットボット・エージェントでの利用手順
標準的なチャットボットやエージェントアプリでは、設定画面からコンテキストとしてナレッジベースを追加し、必要に応じて検索設定を調整することで連携できます。特別なプログラミングは不要で、数回のクリックのみで社内データ対応のチャットボットが完成します。
具体的には以下の手順で設定を行います。
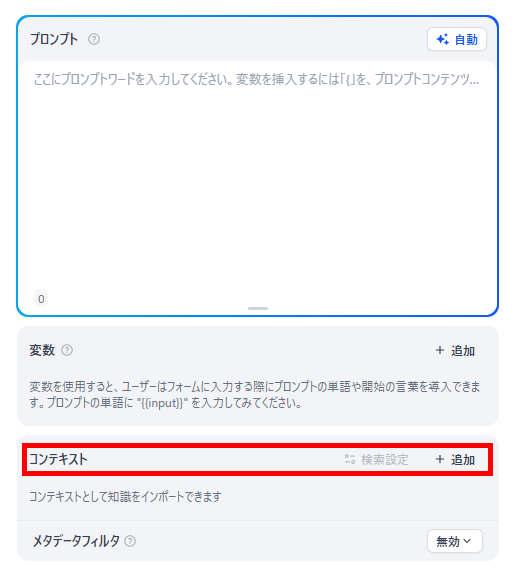
- コンテキスト設定からの追加:
アプリの構築画面(プロンプトエディタなど)を開き、「コンテキスト」セクションにある追加ボタンをクリックして、作成済みのナレッジベースを選択します。 - 検索パラメータの最終調整:
連携後、アプリ側の設定画面から「一度の検索で取得するチャンクの最大数」や「最低スコアの閾値」などの取得パラメータをアプリの用途に合わせて微調整します。
チャットフローでの利用手順
より複雑な条件分岐やステップを伴うチャットフローを構築する場合は、専用のノードをフロー上に配置してナレッジベースを呼び出します。これにより、特定の質問が来たときだけ社内データを検索するといった柔軟な設計が可能になります。
主に以下のノード設定が挙げられます。
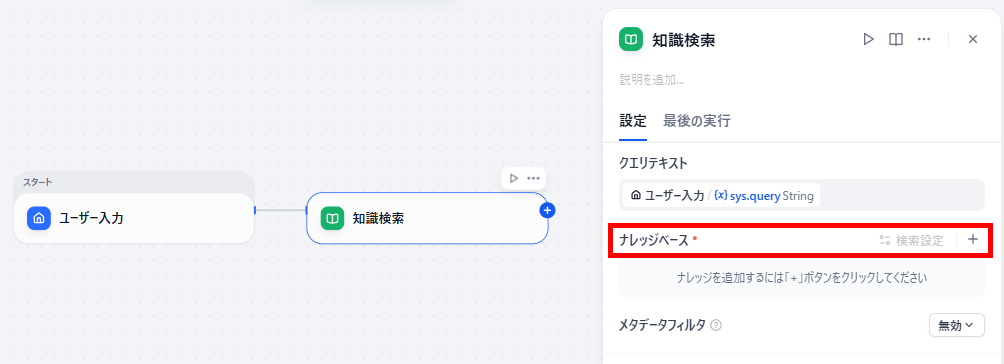
- 知識検索ノードの配置:
フローの編集キャンバス上で「知識検索」の専用ノードを追加し、参照させたいナレッジベースを指定します。 - 変数と出力のルーティング:
ユーザーの入力内容を変数としてノードに渡し、取得した検索結果を次のLLMノード(回答生成)に接続して、最終的な出力へと繋ぎ合わせます。
🧪【検証】チャンク設定の違いによる回答の網羅性を比較
ここでは、実際にDify上でナレッジベースを構築し、チャンク設定の違いがAIの回答にどのような影響を与えるのかを検証します。今回は「汎用モード」と「親子モード」の2パターンで、経費精算規定に関する質問の網羅性を比較しました。
検証条件
検証は、以下の条件で行いました。
- アカウント:無料プラン
- 環境:クラウド版
- AIモデル:Gemini 2.5-Flash
ナレッジベースの登録
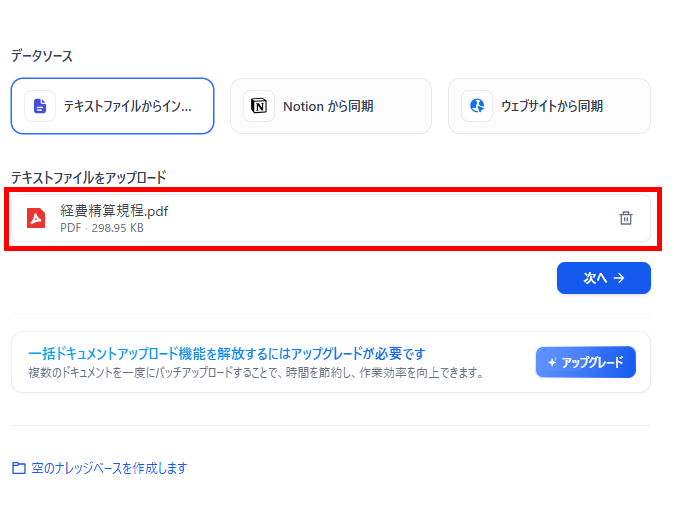
検証では、架空の経費精算規程をナレッジベースに登録しました。登録したファイルと登録時の条件、そして手順は、以下の通りです。
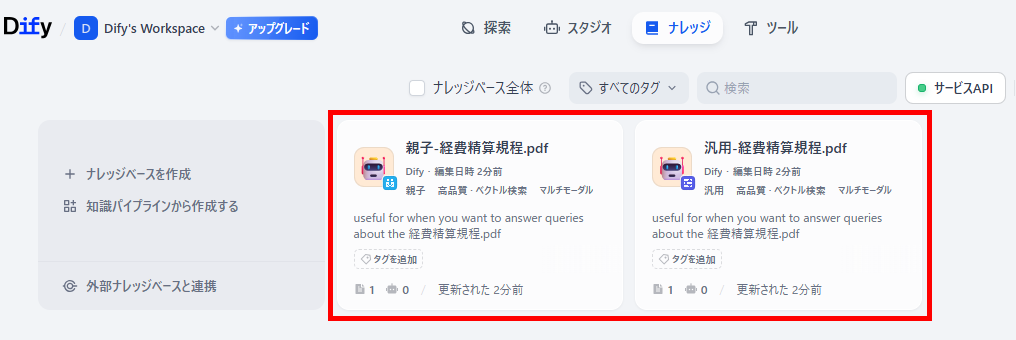
🔷登録ファイル

🔷登録条件
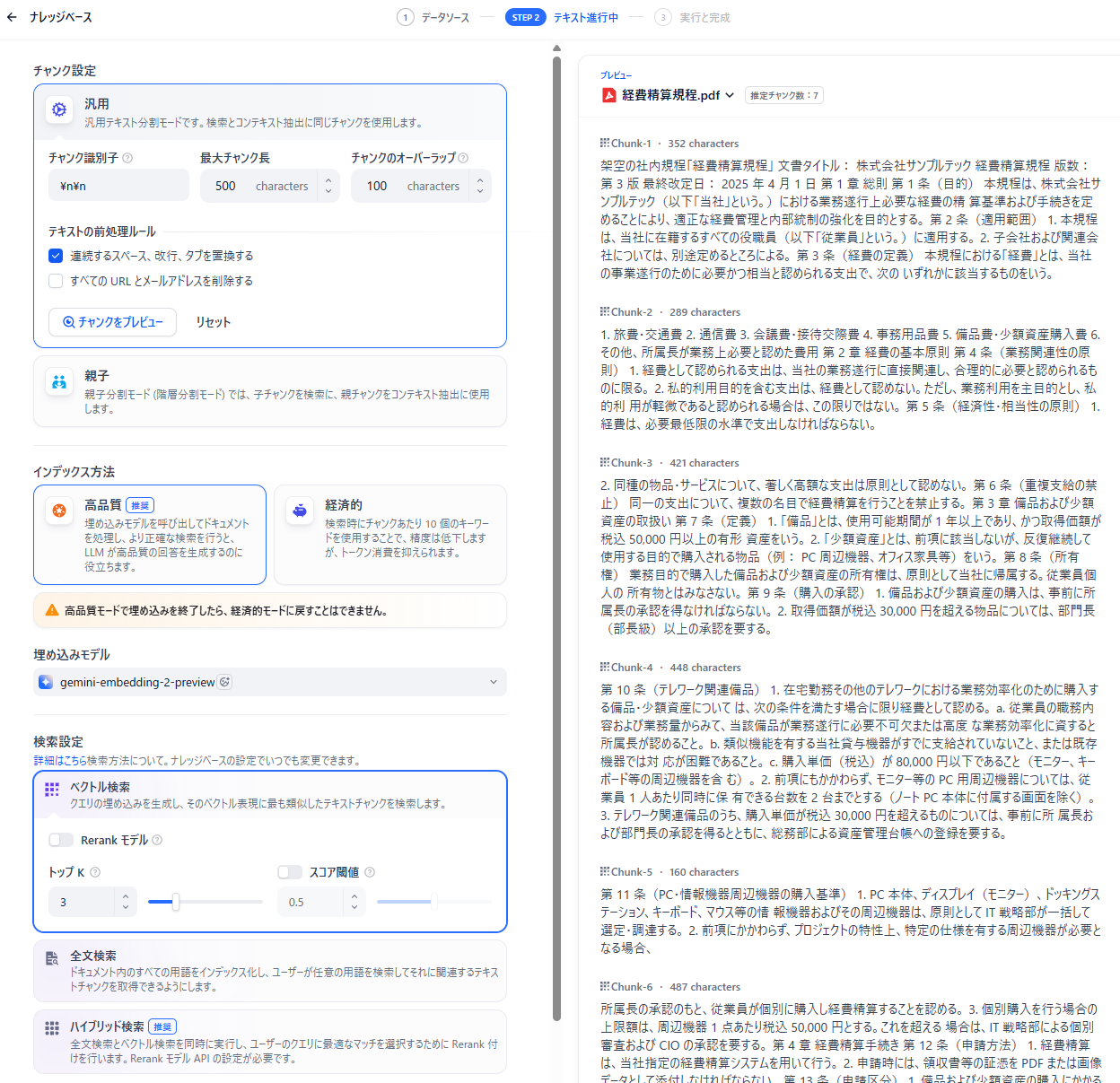
- チャンク設定(汎用):最大チャンク長 - 500 / チャンクのオーバーラップ - 100
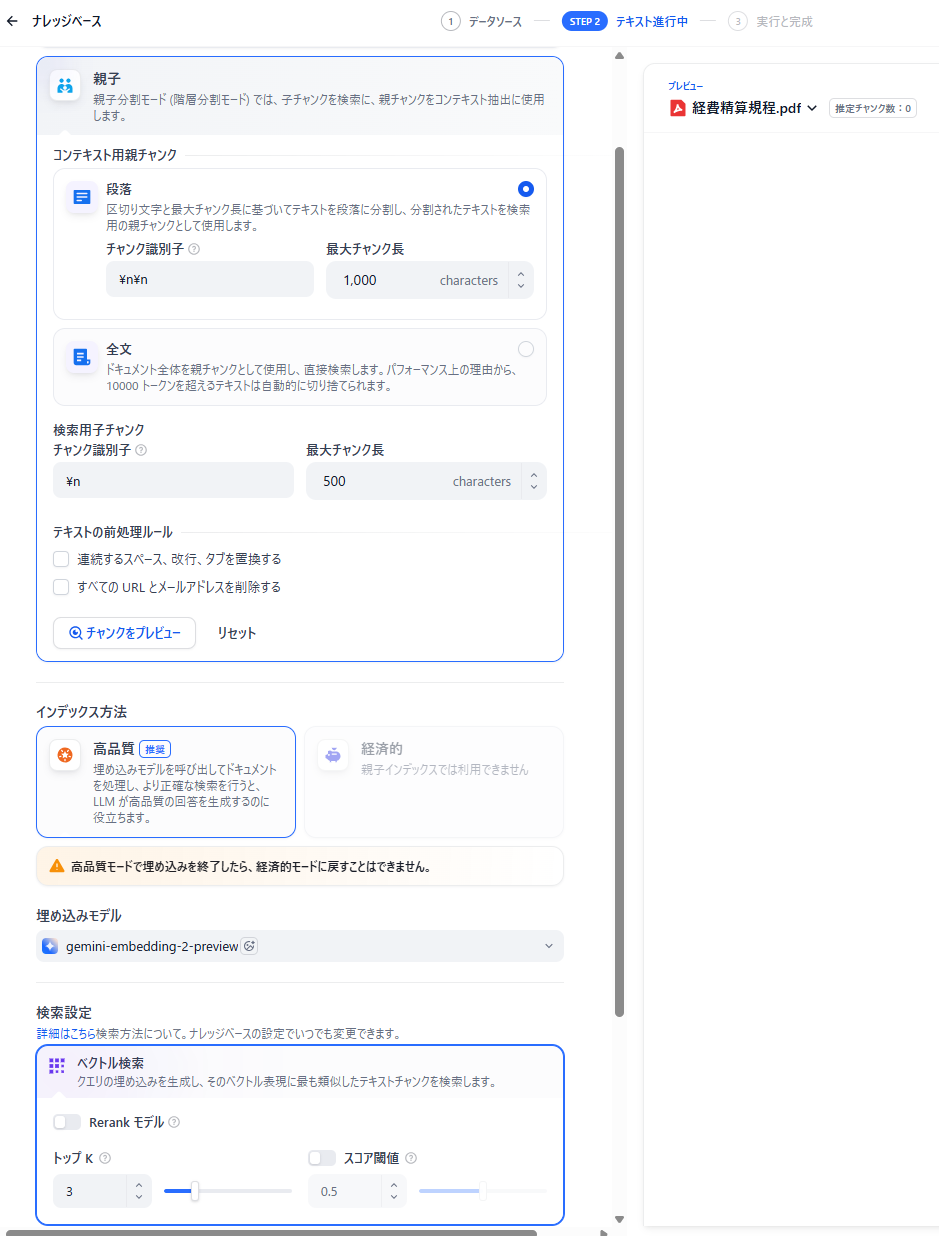
- チャンク設定(親子):親の最大チャンク長 - 1000 / 子の最大チャンク長 - 500
- インデックス方法:高品質
- 埋め込みモデル:gemini-embedding-2-preview
- 検索設定:ベクトル検索(トップK:3)
🔷手順
- ナレッジベースの作成:「ナレッジ」メニューを開き「ナレッジベースを作成」をクリックします。
- アップロード方法を選択:今回は、「テキストファイルからインポート」を利用します。
- ファイルをアップロード:ファイルをアップロードし、「次へ」をクリックします。
- ナレッジベースの設定と保存:チャンク設定、インデックス方法、埋め込みモデル、そして検索設定を行い保存します。
【汎用モード】
【親子モード】
※親子モードでは、より複雑な処理が必要なため、処理はできても、以下のようにプレビューが表示されないことがあります。 - ナレッジベースの作成完了:作成が完了すると、一覧に表示されます。
アプリの作成と出力比較
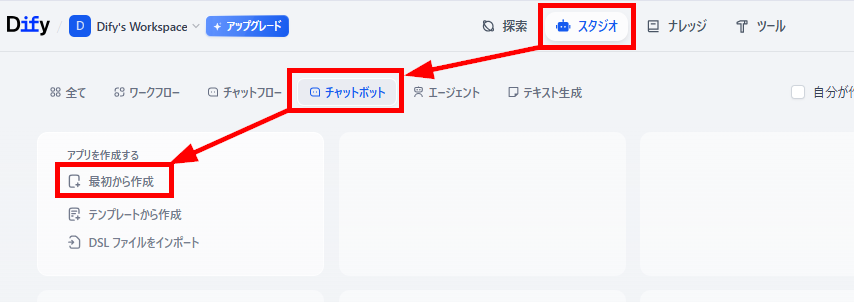
上記で作成したナレッジベースをもとに回答を生成するチャットボットを作成します。- アプリの作成:「スタジオ」メニューで「チャットボット」を選択し、「最初から作成」をクリックします。
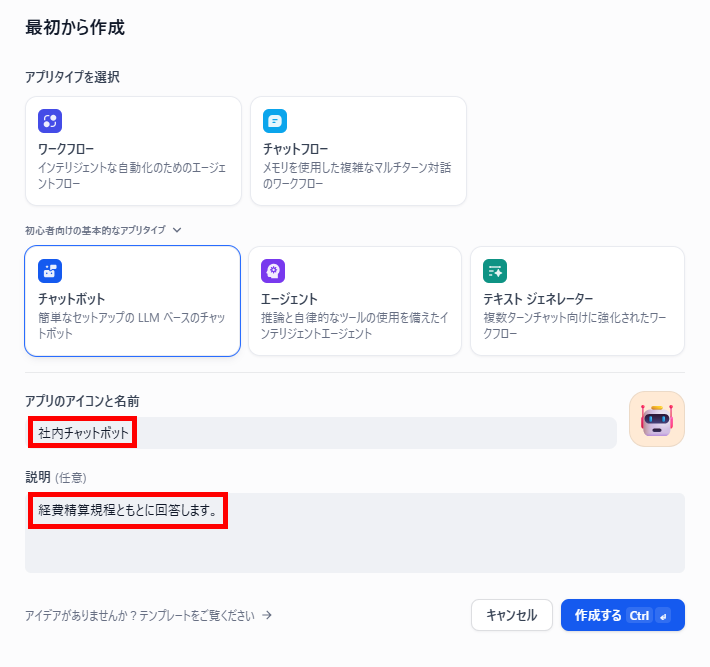
- アプリの概要設定:「名前」「説明」を入力したら「作成する」をクリックします。
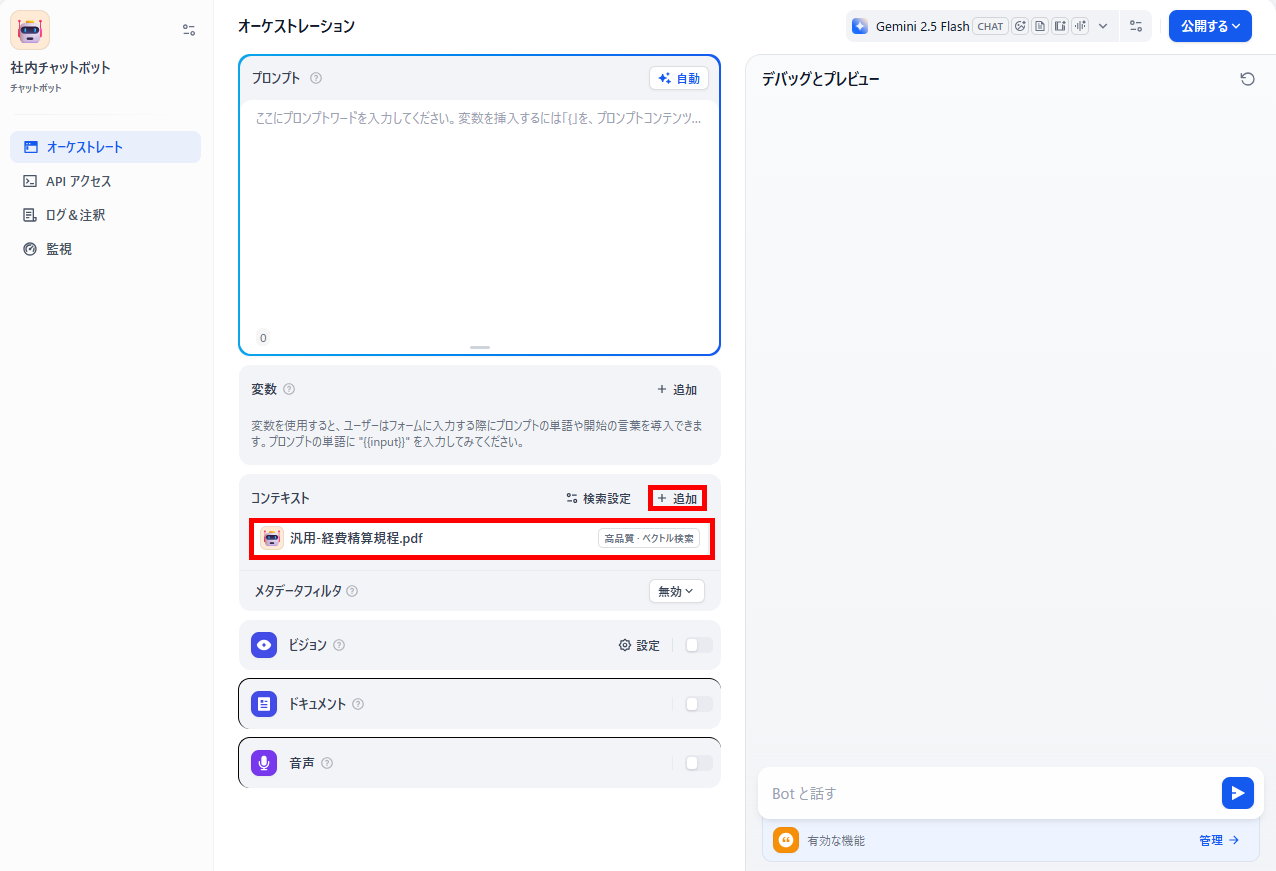
- コンテキストの追加:コンテキスト欄の「+」マークをクリックし、先ほど登録したナレッジベースを選択して追加します。
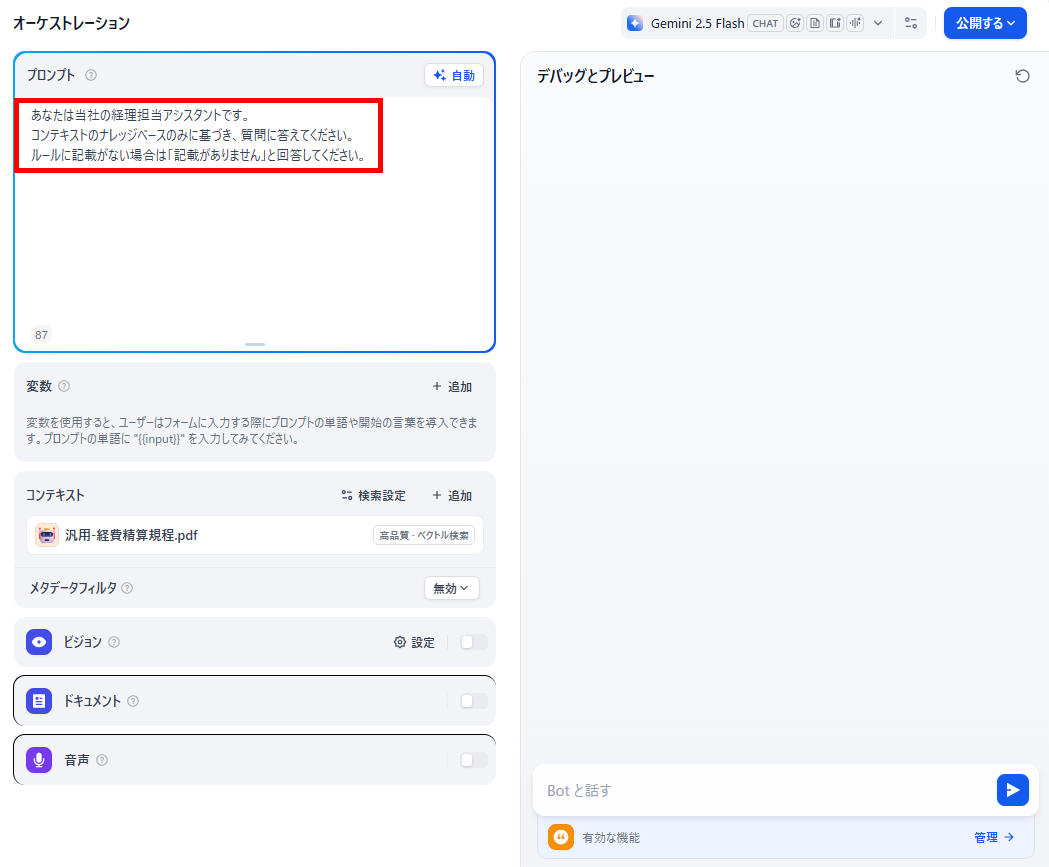
- プロンプトの設定:プロンプト欄に任意の指示を設定します。今回は、以下の指示をプロンプト欄に入力しました。
【プロンプト】
あなたは当社の経理担当アシスタントです。
コンテキストのナレッジベースのみに基づき、質問に答えてください。
ルールに記載がない場合は「記載がありません」と回答してください。 - 動作確認:デバッグとプレビュー画面で、テスト用の質問を送信し、出力を確認します。
【質問】
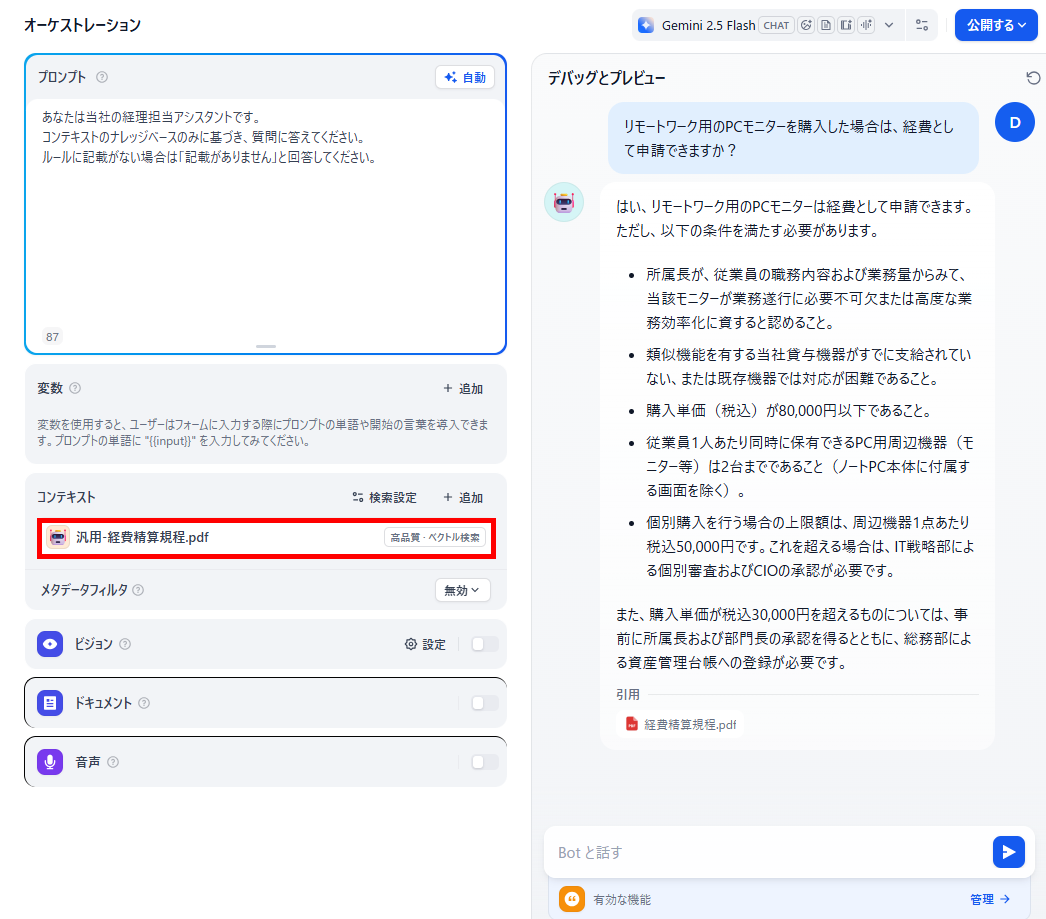
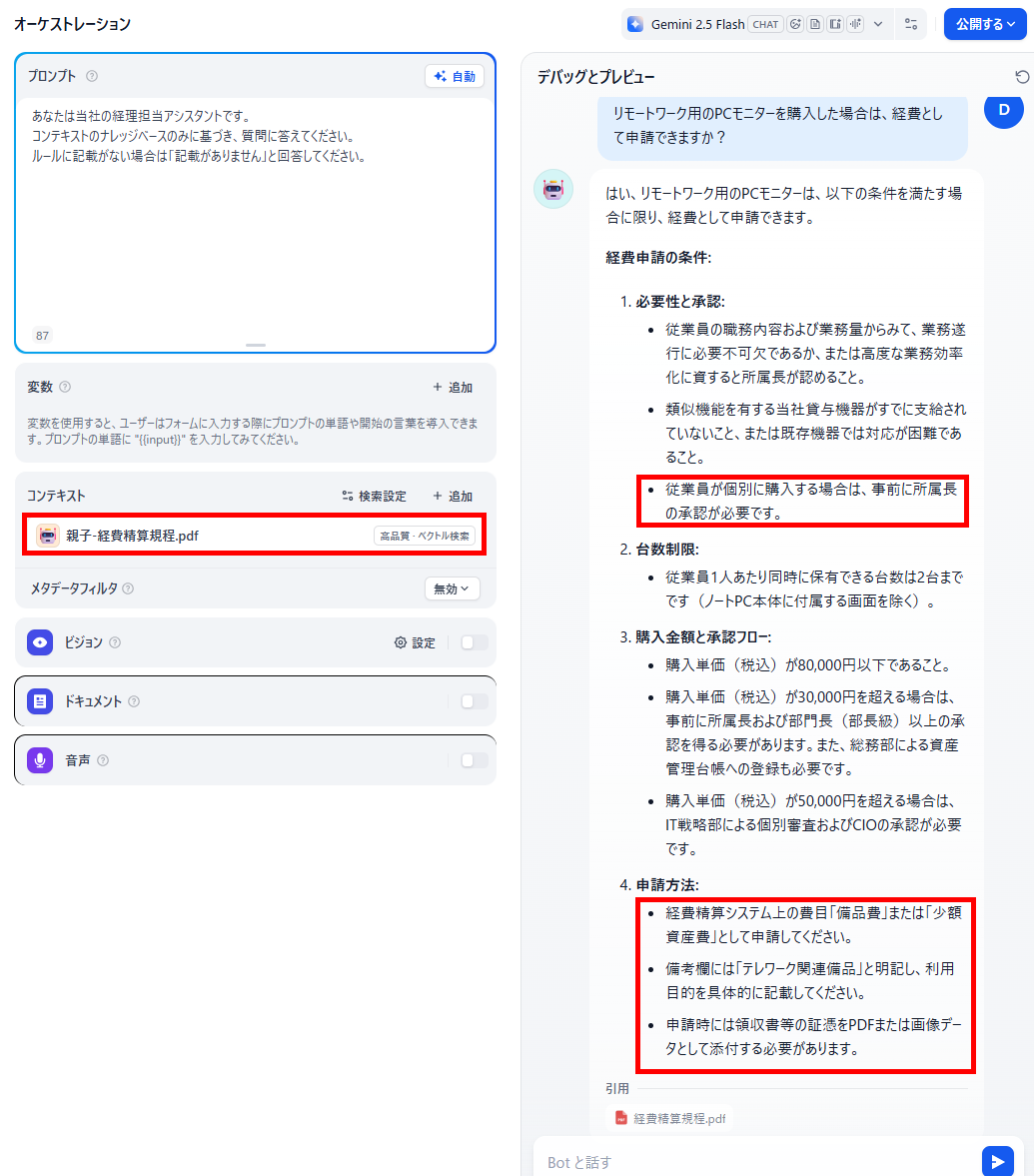
リモートワーク用のPCモニターを購入した場合は、経費として申請できますか?
【汎用モードの結果】
【親子モードの結果】
検証結果
汎用モードと親子モードでアプリを構築してみて、以下のことがわかりました。- 汎用モードも親子モードもナレッジベースを設定する手間に大差はない
- アプリ構築時のコンテキスト登録手順においても、両モード間で違いはない
- 親子モードを使用すると、承認条件や申請方法などより詳細な回答が得られた
🔷親子モードの活用でより詳細で実用的な回答が生成されます
今回の検証では、複雑な社内規定を読み込ませた場合、親子モードのほうがより詳細な回答を引き出せる結果になりました。具体的には、以下のようなポジティブな結果が確認されています。- 承認条件が汎用モードよりも1つ多く出力されました。
- 回答内に申請方法の具体的な手順まで記載されていました。
このように、マニュアル内の複数の章にまたがるような複雑な質問が想定される場合は、文脈を維持しやすい親子モードを選択することをおすすめします。設定手順は汎用モードと大きく変わらないため、用途によっては回答の質の向上が期待できます。
🔷親子モードは複雑な処理によりプレビューが表示されない場合がある
親子モードは回答精度が向上する反面、設定時の画面表示において一部注意が必要な点がわかりました。親チャンクと子チャンクを分けて管理するという特性上、汎用モードに比べて内部の処理が複雑になります。そのため、処理自体は正常に完了していても、設定画面上でプレビューが正しく表示されないことがあります。
今回の検証では、プレビューに十分な表示が出ない状態でも、アプリ側のテストで回答を確認できました。プレビューが表示されず不安に感じる場合は、アプリ構築後のテスト画面で実際に質問を入力し、適切に回答が生成されるかを直接確認することをおすすめします。
📝まとめ
Difyを利用したRAG環境の構築は、非エンジニアでも直感的に設定できる一方で、チャンク分割や検索アルゴリズムの選択が回答精度を大きく左右します。特に社内規定などの複雑なドキュメントを扱う際は、文脈を維持できる「親子モード」や、検索の精度を高める「ハイブリッド検索+Rerankモデル」の組み合わせを活用することが成功の鍵となります。自社のデータ特性に合わせてこれらの設定を最適化し、信頼性の高いAIアシスタントの開発を進めてみてください。
🔌Yoomでできること
Difyを活用することで、問い合わせ対応の効率化を図れますが、自動化できるのは一部の業務に限られるのではないでしょうか?Yoomは750種類以上のサービスに対応しており、さまざまなAIや業務ツールをはじめ、Difyで作成したアプリを組み込んだ業務フローも作成できるため、より多くの自動化を実現できます。これにより、以下のような効果が期待できます。
- これまでと同じ時間でより多くの作業を完了する
- 時間に追われることなく業務に集中する
導入により、月200件の転記業務を自動化して心理的な負担を削減している企業もあります。Yoomには、自動化フローを構築するためのテンプレートが豊富にあり、直感的な操作で簡単に設定できるので、ぜひ試してみてください。
■このテンプレートをおすすめする方
- 会社設立直後で事務スタッフの雇用や教育にリソースを割く余裕がなく、問い合わせ対応やリスト管理を効率化したい創業者の方
- Googleフォームで受け付けた問い合わせ内容から、会社名や氏名、連絡先などをGoogle スプレッドシートの見込み顧客リストへ手作業で転記している方
- 問い合わせの確認や一次返信文面の作成に時間がかかっており、AIエージェントを活用して対応スピードを向上させたい方
■このテンプレートを使うメリット
- Googleフォームの回答から必要な情報を抽出してGoogle スプレッドシートへ自動で記録するため、転記作業の負担をなくし、入力ミスや漏れなどのリスクを低減できます。
- AIが問い合わせ内容を解析して最適な返信案を自動作成するため、ゼロから文章を考える時間を短縮し、一貫性のある顧客対応が可能になります。
■フローボットの流れ
- はじめに、Googleフォーム、Google スプレッドシート、ChatworkをYoomと連携します
- 次に、トリガーで、Googleフォームの「回答が送信されたら」というアクションを設定します
- 次に、オペレーションで、Google スプレッドシートの「行を追加する」アクションを設定し、受信した回答を記録します
- 最後に、AIワーカーで、問い合わせの解析と返信案の作成、およびシートへの記録を行うためのマニュアルを作成し、Googleフォーム、Google スプレッドシート、Chatworkの各アクションを使用ツールとして設定します
■このワークフローのカスタムポイント
- Google スプレッドシートの設定では、あらかじめ回答を蓄積するためのヘッダー(項目名)を作成したシートを用意し、該当する列にフォームの各項目や解析結果などを紐づけてください。
- AIワーカーのマニュアル設定では、自社の商品知識や返信時のトーン&マナーなどを指示として盛り込むことで、より精度の高い返信案が作成されるよう調整してください。
- Chatworkの通知では、特定のルームを宛先に指定し、メッセージに担当者へのメンションやGoogle スプレッドシートへのリンクを含めるなどの工夫が可能です。
■注意事項
- Googleフォーム、Google スプレッドシート、ChatworkのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Googleフォームをトリガーとして使用した際の回答内容を取得する方法は「Googleフォームトリガーで、回答内容を取得する方法」を参照ください。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- Googleフォームを活用した問い合わせ対応で、手動での振り分け業務を効率化したい方
- AIを活用した仕組みで、問い合わせの振り分け精度を高めたいと考えている方
- Zendeskを利用しており、問い合わせからのチケット作成を自動化したいカスタマーサポート担当の方
- Googleフォームへの回答を起点に、AIによる内容解析からZendeskへのチケット作成までが自動化され、手作業での問い合わせ振り分けに費やしていた時間を短縮できます。
- 担当者の割り当てミスやチケットの起票漏れといったヒューマンエラーを防止し、顧客対応の品質向上に繋がります。
- はじめに、GoogleフォームとZendeskをYoomと連携します。
- 次に、トリガーでGoogleフォームを選択し、「フォームに回答が送信されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、フォームの回答内容をもとに、問い合わせの解析、担当者の割り当て、Zendeskでのチケット作成を行うためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Googleフォームのトリガー設定では、連携の対象としたい任意のフォームを指定してください。
- AIワーカーの設定では、問い合わせ内容を振り分ける際のルールや、チケットを作成する際の指示内容など、自社の運用に合わせてマニュアル(指示)を任意で設定してください。
- Googleフォーム、ZendeskのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- Googleフォームをトリガーとして使用する際、回答内容の取得方法をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Zendeskはチームプラン・サクセスプランでのみご利用いただけるアプリとなっております。フリープラン・ミニプランの場合は設定しているフローボットのオペレーションやデータコネクトはエラーとなりますので、ご注意ください。
- チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリを使用することができます。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
【出典】
Dify Docs/Knowledge - Dify Docs/GitHub - langgenius/dify: Production-ready platform for agentic workflow development.
プログラミング知識なしで手軽に構築できます。