・
RAG構築のポイント整理|チャンク・検索・プロンプトを変えて精度を比較

RAG(検索拡張生成)は、社内文書や独自データを活用してAIの回答精度を飛躍的に向上させる技術として、多くの企業で導入が進められています。
本記事では、RAG構築の基礎知識から最新のトレンド、具体的な構築ステップについて詳しく解説。
さらに、ノーコードツールのDifyを用いた実践的な検証結果も交えながら、RAGシステムの構築に必要なノウハウを余すところなくお届けします!
💬RAG(検索拡張生成)とは?

RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)が回答を生成する際に、外部のデータベースから関連する情報を検索し、その情報を元に回答を作成する技術です。
RAGを導入することで、自社の社内規程や製品マニュアル、営業資料などの独自データをAIに参照させることが可能となり、正確で明確な根拠に基づいた回答を安定して得ることができます。
主な活用シーンは以下の通りです。

ビジネスの現場において、非常に実用性の高いAIソリューションを実現するための重要な基盤技術として位置づけられています。
💻Yoomは社内データの自動収集を自動化できます
RAGを構築する際、AIに読み込ませるためのデータ収集や更新作業が大きな壁となることが少なくありません。
Yoomを活用すれば、ストレージサービスや社内データベースなどに散在するドキュメントを自動で収集し、RAGシステムが参照しやすい形式に整理するフローを簡単に構築できるんです!
[Yoomとは]
定期的なデータ連携を自動化しておくことで、常に鮮度の高い情報をAIに提供することが可能になり、RAGの回答精度を維持・向上させる運用が劇的に楽になるでしょう。
日常業務をサポートする自動化フローボット
■概要日々のマーケティングリサーチ業務において、情報収集やNotionへのデータ入力に手間を感じている方もいらっしゃるのではないでしょうか。また、AIを活用した効率化に関心があっても、具体的な方法が分からずお困りかもしれません。このワークフローは、Notionに新しいレコードが追加されると、その情報を基にAIが自動でマーケティングリサーチを実行し、結果をNotionに追記するもので、これらの課題解決に貢献します。
■このテンプレートをおすすめする方- Notionを活用した情報集約と、AIによるリサーチ業務の効率化を目指すマーケティング担当者
- 手作業でのリサーチやデータ入力に時間を費やしており、コア業務に集中したいと考えている方
- AIの具体的な業務活用例を探しており、ノーコードでの自動化に関心のあるビジネスパーソン
■このテンプレートを使うメリット- Notionへのレコード追加を起点に、AIによるリサーチからNotionへの結果追記までを自動化し、作業時間を短縮できます。
- AIが一貫したリサーチを行うため、手作業による情報収集のばらつきや、入力時のヒューマンエラーを減らし、業務の質を安定させることができます。
■フローボットの流れ- はじめに、NotionをYoomと連携します。
- 次に、トリガーでNotionを選択し、「特定のデータソースのページが作成・更新されたら」というアクションを設定します。
- 次に、オペレーションで分岐機能を設定し、特定の条件に基づいて後続の処理を分岐させます。
- 続けて、オペレーションでNotionの「レコードを取得する(ID検索)」アクションを設定し、トリガーとなったページの情報を取得します。
- 次に、オペレーションでAI機能の「テキストを生成する」アクションを設定し、取得した情報などを基にマーケティングリサーチを行います。
- 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、AIが生成したリサーチ結果をNotionのデータソースに追記します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Notionのトリガー設定およびオペレーション設定では、対象としたいデータソースをそれぞれ任意で指定してください。
- AI機能の「テキストを生成する」アクションでは、マーケティングリサーチの目的に合わせてプロンプトを自由にカスタムでき、定型文や前段階のNotionで取得した情報を変数として組み込むことが可能です。
- 最終的にNotionへレコードを追加する際、データソースの各プロパティ(項目)に対して、AIが生成したどの情報を割り当てるか、または固定値を設定するかなど、柔軟にカスタマイズできます。
■注意事項- NotionとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 分岐はパーソナルプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- パーソナルプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。詳しくは、料金プランのページをご参照ください。
■概要
フォーム経由で受け取るPDFや画像形式の社内資料の確認に、手間を感じていませんか。
特に、ファイルを開いて内容を把握し、要約してチームに共有する作業は時間がかかるものです。
このワークフローを活用すれば、フォームに資料が添付・送信されると、OCR機能が内容を自動で読み取り、AIが要約した上でSlackに通知します。
これにより、資料の内容確認と情報共有にかかる手間を削減し、業務を効率化できます。
■このテンプレートをおすすめする方
- フォームで受け取るPDFや画像資料の内容確認に手間を感じている総務・管理部門の方
- OCRやAIを活用して、社内での情報共有プロセスを効率化したいと考えている方
- 手作業による資料の要約やSlackへの転記作業を自動化したいと考えている方
■このテンプレートを使うメリット
- フォーム送信からOCRでの読み取り、AI要約、Slack通知までを自動化し、手作業での確認や転記に費やしていた時間を短縮します。
- 手作業による転記ミスや要約の抜け漏れを防ぎ、重要な情報を見落とすといったヒューマンエラーのリスクを軽減できます。
■フローボットの流れ
- はじめに、SlackをYoomと連携します。
- 次に、トリガーでフォームトリガー機能を選択し、「フォームが送信されたら」というアクションを設定します。
- 次に、オペレーションでOCR機能の「任意の画像やPDFを読み取る」アクションを設定し、フォームで受け取ったファイルを指定します。
- 次に、AI機能の「要約する」アクションを設定し、OCR機能で読み取ったテキストデータを要約します。
- 最後に、オペレーションでSlackの「チャンネルにメッセージを送る」アクションを設定し、AIが生成した要約を任意のチャンネルに通知します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガーで設定するフォームの質問項目やファイル添付欄は、業務に合わせて任意でカスタマイズしてください。
- OCR機能で画像を読み取るアクションでは、資料の中からテキストを抽出したい範囲を任意で設定することが可能です。
- AI機能で要約するアクションでは、要約対象のテキストとして、前のステップのOCR機能で取得したテキストデータを選択してください。
- Slackに通知するメッセージ本文には、前のステップのAI機能で生成された要約結果を選択しましょう。
■注意事項
- SlackとYoomを連携してください。
- OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。
フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 - チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。
無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。
■このテンプレートをおすすめする方
- Notionを活用した情報集約と、AIによるリサーチ業務の効率化を目指すマーケティング担当者
- 手作業でのリサーチやデータ入力に時間を費やしており、コア業務に集中したいと考えている方
- AIの具体的な業務活用例を探しており、ノーコードでの自動化に関心のあるビジネスパーソン
■このテンプレートを使うメリット
- Notionへのレコード追加を起点に、AIによるリサーチからNotionへの結果追記までを自動化し、作業時間を短縮できます。
- AIが一貫したリサーチを行うため、手作業による情報収集のばらつきや、入力時のヒューマンエラーを減らし、業務の質を安定させることができます。
■フローボットの流れ
- はじめに、NotionをYoomと連携します。
- 次に、トリガーでNotionを選択し、「特定のデータソースのページが作成・更新されたら」というアクションを設定します。
- 次に、オペレーションで分岐機能を設定し、特定の条件に基づいて後続の処理を分岐させます。
- 続けて、オペレーションでNotionの「レコードを取得する(ID検索)」アクションを設定し、トリガーとなったページの情報を取得します。
- 次に、オペレーションでAI機能の「テキストを生成する」アクションを設定し、取得した情報などを基にマーケティングリサーチを行います。
- 最後に、オペレーションでNotionの「レコードを追加する」アクションを設定し、AIが生成したリサーチ結果をNotionのデータソースに追記します。
■このワークフローのカスタムポイント
- Notionのトリガー設定およびオペレーション設定では、対象としたいデータソースをそれぞれ任意で指定してください。
- AI機能の「テキストを生成する」アクションでは、マーケティングリサーチの目的に合わせてプロンプトを自由にカスタムでき、定型文や前段階のNotionで取得した情報を変数として組み込むことが可能です。
- 最終的にNotionへレコードを追加する際、データソースの各プロパティ(項目)に対して、AIが生成したどの情報を割り当てるか、または固定値を設定するかなど、柔軟にカスタマイズできます。
■注意事項
- NotionとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- 分岐はパーソナルプラン以上のプランでご利用いただける機能(オペレーション)となっております。フリープランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。
- パーソナルプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。無料トライアル中には制限対象のアプリや機能(オペレーション)を使用することができます。詳しくは、料金プランのページをご参照ください。
■概要
フォーム経由で受け取るPDFや画像形式の社内資料の確認に、手間を感じていませんか。
特に、ファイルを開いて内容を把握し、要約してチームに共有する作業は時間がかかるものです。
このワークフローを活用すれば、フォームに資料が添付・送信されると、OCR機能が内容を自動で読み取り、AIが要約した上でSlackに通知します。
これにより、資料の内容確認と情報共有にかかる手間を削減し、業務を効率化できます。
■このテンプレートをおすすめする方
- フォームで受け取るPDFや画像資料の内容確認に手間を感じている総務・管理部門の方
- OCRやAIを活用して、社内での情報共有プロセスを効率化したいと考えている方
- 手作業による資料の要約やSlackへの転記作業を自動化したいと考えている方
■このテンプレートを使うメリット
- フォーム送信からOCRでの読み取り、AI要約、Slack通知までを自動化し、手作業での確認や転記に費やしていた時間を短縮します。
- 手作業による転記ミスや要約の抜け漏れを防ぎ、重要な情報を見落とすといったヒューマンエラーのリスクを軽減できます。
■フローボットの流れ
- はじめに、SlackをYoomと連携します。
- 次に、トリガーでフォームトリガー機能を選択し、「フォームが送信されたら」というアクションを設定します。
- 次に、オペレーションでOCR機能の「任意の画像やPDFを読み取る」アクションを設定し、フォームで受け取ったファイルを指定します。
- 次に、AI機能の「要約する」アクションを設定し、OCR機能で読み取ったテキストデータを要約します。
- 最後に、オペレーションでSlackの「チャンネルにメッセージを送る」アクションを設定し、AIが生成した要約を任意のチャンネルに通知します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント
- フォームトリガーで設定するフォームの質問項目やファイル添付欄は、業務に合わせて任意でカスタマイズしてください。
- OCR機能で画像を読み取るアクションでは、資料の中からテキストを抽出したい範囲を任意で設定することが可能です。
- AI機能で要約するアクションでは、要約対象のテキストとして、前のステップのOCR機能で取得したテキストデータを選択してください。
- Slackに通知するメッセージ本文には、前のステップのAI機能で生成された要約結果を選択しましょう。
■注意事項
- SlackとYoomを連携してください。
- OCRまたは音声を文字起こしするAIオペレーションはチームプラン・サクセスプランでのみご利用いただける機能となっております。
フリープラン・ミニプランの場合は設定しているフローボットのオペレーションはエラーとなりますので、ご注意ください。 - チームプランやサクセスプランなどの有料プランは、2週間の無料トライアルを行うことが可能です。
無料トライアル中には制限対象のアプリやAI機能(オペレーション)を使用することができます。
AIワーカーを活用した自動化フローボット
■概要Telegramを通じた顧客や関係者からの問い合わせに対し、過去のメール履歴を探して回答を作成する作業に手間を感じていませんか?一件ずつ情報を探す作業は時間がかかるだけでなく、対応品質のばらつきを生む原因にもなり得ます。 このワークフローを活用すれば、Telegramにメッセージが届くと、AIがRAG技術を用いて関連するメール履歴を自動で検索・参照し、最適な回答案を生成します。これにより、問い合わせ対応の迅速化と品質向上を実現できます。■このテンプレートをおすすめする方- Telegramでの問い合わせ対応で、過去のメール履歴の検索に時間を要している方
- RAGの仕組みを活用し、Telegramでの顧客対応を効率化したいと考えている方
- AIを用いて問い合わせ対応の品質を標準化し、属人化を解消したいチームリーダーの方
■このテンプレートを使うメリット- Telegramへの問い合わせに対し、関連するメール履歴の検索と回答案作成が自動化されるため、手作業での対応時間を短縮することができます
- RAGを用いて過去のやり取りを基に回答を生成することで、担当者による対応品質のばらつきを防ぎ、業務の標準化に繋がります
■フローボットの流れ- はじめに、GmailとTelegramをYoomと連携します
- 次に、トリガーでTelegramを選択し、「ボットがメッセージを受け取ったら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、Gmailから取得したメール履歴を分析してRAGに基づいた回答を生成して返信するためのマニュアル(指示)を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- AIワーカーのオペレーションでは、回答生成に利用するAIモデルを任意で選択することが可能です
- AIワーカーへの指示(プロンプト)も任意で設定できます。回答のトーンや文字数、参照すべき情報の優先順位などを業務に合わせて調整してください
■注意事項- Telegram、GmailのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
■概要社内からの問い合わせに対し、毎回ドキュメントを探したり、同じ質問に答えたりする業務に時間を取られていませんか?こうした繰り返し発生する社内情報の検索と回答は、担当者の負担になりがちです。 このワークフローを活用すれば、Microsoft Teamsに投稿された質問をトリガーとして、まるでAIエージェントのように社内情報を自動で検索し、回答を生成することが可能です。■このテンプレートをおすすめする方- 社内ヘルプデスクで、繰り返される質問への対応を効率化したいと考えているご担当者の方
- Microsoft Teamsを活用し、AIワーカーによる自動的な社内情報検索の仕組みを構築したい方
- 属人化しがちなナレッジを共有し、問い合わせ対応業務を自動化したいと考えている方
■このテンプレートを使うメリット- Microsoft Teams上の質問に対し、AI agentが社内情報を検索して自動回答するため、担当者の対応工数を削減し、コア業務に集中できます。
- これまで担当者個人が対応していた問い合わせ業務を自動化することで、業務の属人化を防ぎ、ナレッジのスムーズな共有を促進します。
■フローボットの流れ- はじめに、社内情報の格納先であるGoogleドキュメントと、質問を受け付けるMicrosoft TeamsをYoomと連携します。
- 次に、トリガーでMicrosoft Teamsを選択し、「チャネルにメッセージが送信されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、Googleドキュメント内の情報を参照して質問に回答するためのマニュアル(指示)を作成します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Microsoft Teamsのトリガー設定では、どのチームのどのチャネルに投稿されたメッセージをきっかけにフローを起動するか、任意のチームIDおよびチャネルIDを設定してください。
- AIワーカーの設定では、回答を生成するAIモデルを任意で選択し、どのような役割で、どの情報を参照して回答を生成するのか、といった具体的な指示を設定してください。
■注意事項- Microsoft Teams、GoogleドキュメントのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- Telegramでの問い合わせ対応で、過去のメール履歴の検索に時間を要している方
- RAGの仕組みを活用し、Telegramでの顧客対応を効率化したいと考えている方
- AIを用いて問い合わせ対応の品質を標準化し、属人化を解消したいチームリーダーの方
- Telegramへの問い合わせに対し、関連するメール履歴の検索と回答案作成が自動化されるため、手作業での対応時間を短縮することができます
- RAGを用いて過去のやり取りを基に回答を生成することで、担当者による対応品質のばらつきを防ぎ、業務の標準化に繋がります
- はじめに、GmailとTelegramをYoomと連携します
- 次に、トリガーでTelegramを選択し、「ボットがメッセージを受け取ったら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを選択し、Gmailから取得したメール履歴を分析してRAGに基づいた回答を生成して返信するためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- AIワーカーのオペレーションでは、回答生成に利用するAIモデルを任意で選択することが可能です
- AIワーカーへの指示(プロンプト)も任意で設定できます。回答のトーンや文字数、参照すべき情報の優先順位などを業務に合わせて調整してください
- Telegram、GmailのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- 社内ヘルプデスクで、繰り返される質問への対応を効率化したいと考えているご担当者の方
- Microsoft Teamsを活用し、AIワーカーによる自動的な社内情報検索の仕組みを構築したい方
- 属人化しがちなナレッジを共有し、問い合わせ対応業務を自動化したいと考えている方
- Microsoft Teams上の質問に対し、AI agentが社内情報を検索して自動回答するため、担当者の対応工数を削減し、コア業務に集中できます。
- これまで担当者個人が対応していた問い合わせ業務を自動化することで、業務の属人化を防ぎ、ナレッジのスムーズな共有を促進します。
- はじめに、社内情報の格納先であるGoogleドキュメントと、質問を受け付けるMicrosoft TeamsをYoomと連携します。
- 次に、トリガーでMicrosoft Teamsを選択し、「チャネルにメッセージが送信されたら」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、Googleドキュメント内の情報を参照して質問に回答するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- Microsoft Teamsのトリガー設定では、どのチームのどのチャネルに投稿されたメッセージをきっかけにフローを起動するか、任意のチームIDおよびチャネルIDを設定してください。
- AIワーカーの設定では、回答を生成するAIモデルを任意で選択し、どのような役割で、どの情報を参照して回答を生成するのか、といった具体的な指示を設定してください。
- Microsoft Teams、GoogleドキュメントのそれぞれとYoomを連携してください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- Microsoft365(旧Office365)には、家庭向けプランと一般法人向けプラン(Microsoft365 Business)があり、一般法人向けプランに加入していない場合には認証に失敗する可能性があります。
- AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
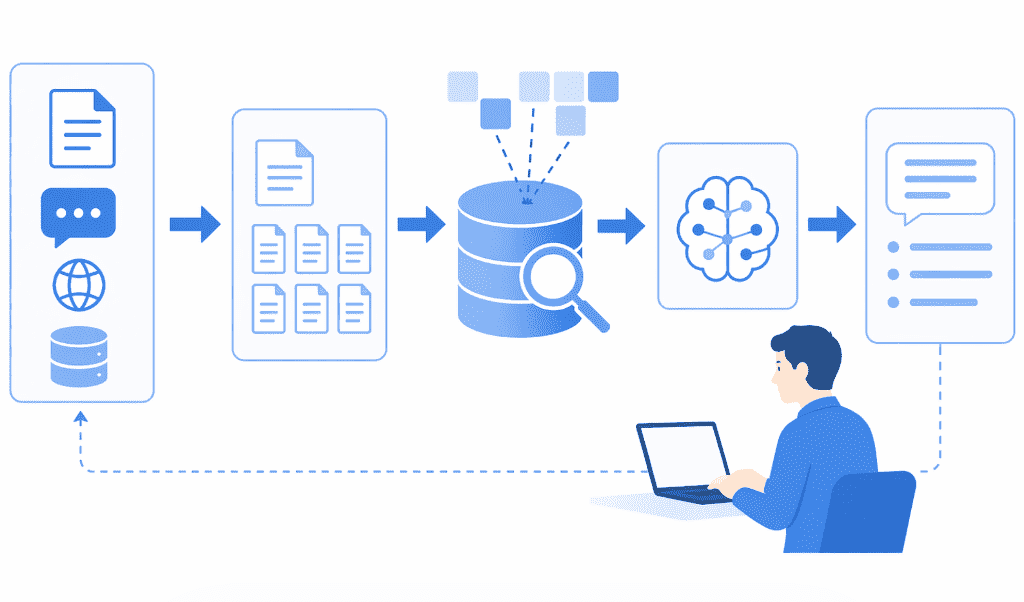
🚶➡️RAGシステムの具体的な構築ステップ

RAGシステムを構築するには、主に4つのステップを踏む必要があります。
- データ準備とチャンキング
PDFや社内ドキュメントのテキストを抽出し、AIが処理しやすい適切なサイズ(チャンク)に分割する作業を行う。 - エンベディング(ベクトル化)
分割したテキストデータを、意味的な近さを計算できるように数値の羅列(ベクトル)に変換。 - ベクトルデータベースへの保存と検索
ベクトル化されたデータを専用のデータベースに格納し、ユーザーからの質問が入力された際に、類似度の高い情報を瞬時に検索して抽出する仕組みを構築。 - LLMによる生成
検索して得られた関連情報とユーザーの質問を組み合わせてプロンプトを構成し、LLMに渡すことで、外部データを根拠とした自然で正確な回答を生成。
これらの一連のパイプラインを適切に設計することが、RAG構築成功の鍵を握るのです。
👐RAG構築を実現するツールを選ぶ際のポイント
ユーザーの質問の意図を汲み取って最終的な回答を生成するLLMの選定は非常に重要。
近年では、GPT系やClaude系といった高性能な商用モデルに加え、長文のコンテキスト処理や推論能力に特化したオープンソースモデルも増えており、目的に応じた使い分けが進んでいます。
オーケストレーションツールの重要性
複数のコンポーネントを接続し、スムーズなデータ連携や処理フローを実現するためのオーケストレーションツールが必要です。
LangChainやLlamaIndexなどのフレームワークに加え、Difyなどのノーコードツールが選択肢として注目を集めており、専門的なプログラミング知識がなくても、直感的にRAGのパイプラインを設計できます。
ベクトルデータベースの導入
膨大なデータをベクトル化して高速に検索・管理するために、ベクトルデータベースの導入が必要です。
PineconeやWeaviateなど、フルマネージドでインフラ管理が不要なサービスが人気を集め、手軽に検証を始められるChromaやエンタープライズ向けのAzure AI Searchなど、選択肢も多岐にわたります。
エンベディングモデルとリランキング技術
テキストデータをAIが処理しやすい形式に変換するためのエンベディングモデルも重要。
多言語対応した高精度なモデルの利用が一般的となり、グローバル対応を支える基盤が整っています。
また、検索精度をさらに向上させるための「リランキング」という技術によって検索結果を再評価して並べ替えることで、より正確で有用な情報を提供することができます。
ツールを適材適所で活用することで、開発効率を大幅に引き上げ、自社の業務に最適化されたシステムをスムーズに構築することが可能になるのです!
📝Difyを用いてRAGを構築してみた!
RAGの有用性を確認するため、ノーコードでAIアプリケーションを構築できるDifyを活用。
数十件の社内規程PDF(就業規則、テレワーク勤務規程、情報セキュリティ規程、休暇・休職規程など)を用いた実践的な検証を行いました。
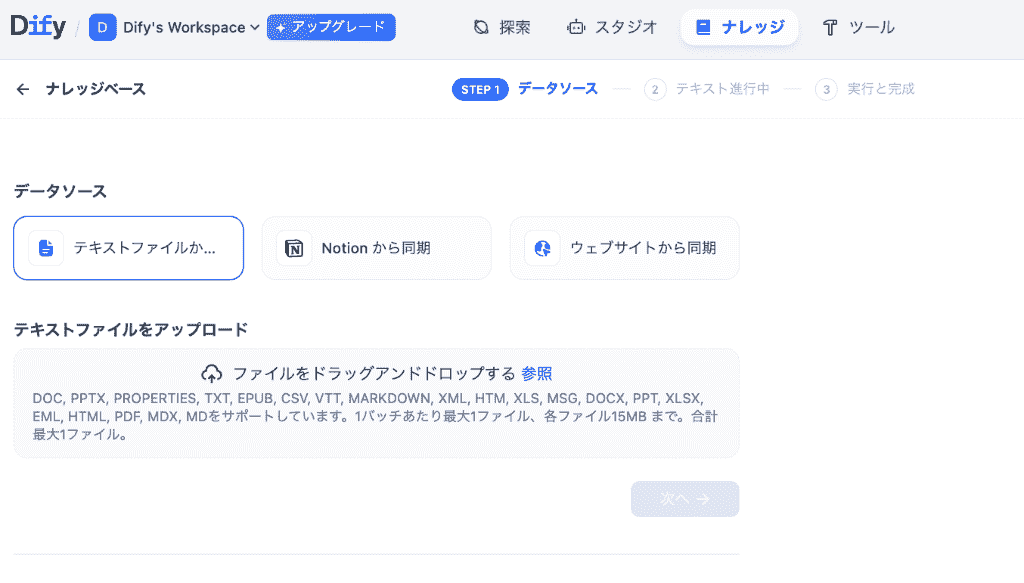
ナレッジの登録はごく簡単で、「ナレッジ」タブを押下し、「ナレッジベースを作成」→「データソースを同期」します。
難しい操作を行う必要はないですが、最初のうちはテキストファイルを同期させる登録方法が初心者にとって優しい手法です。
チャンクサイズによる検索精度の違いの検証
まずは、文書を分割する際のチャンクサイズを変更し、回答の正確性にどう影響するかを調査しました。
社内規定のナレッジを登録し、以下のようなチャットフローを構築します。
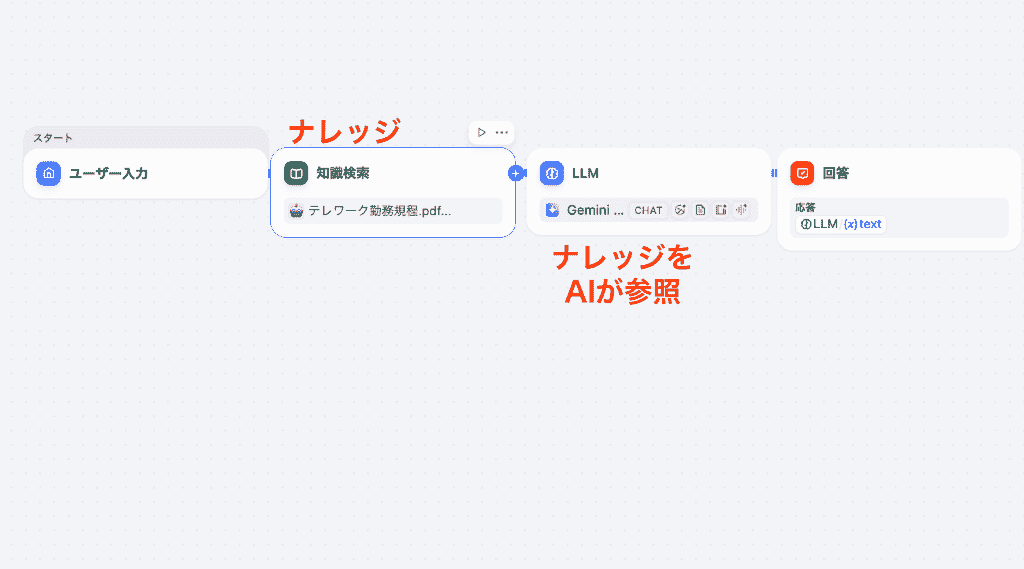
- チャンク:ドキュメントを小さなセグメントに分割したもの
- オーバーラップ:分割時に隣接するチャンク間でテキストの一部を重複させる設定のこと
アプリを公開して、同じ質問を投稿。
テレワーク中に深夜22時以降まで勤務した場合の取り扱いを教えてください。
得られた結果が以下のようになります。
小チャンク設定
チャンクサイズ:200、オーバーラップ:50

中チャンク設定
チャンクサイズ:500、オーバーラップ:100

大チャンク設定
チャンクサイズ:2000、オーバーラップ:200

今回の検証環境として、大きすぎるチャンク(2000文字以上)では、関係ない規則マニュアルを読み込んでしまっており、不要な情報が混ざったため回答がぼやける傾向が見られました。
一方、小さすぎるチャンク(200文字)では、意味を正しく捉えられておらず、回答内容が冗長になっているケースが発生。
結果として、500〜800文字程度に分割し、適度なオーバーラップ(重複部分)を持たせることが、今回の社内規程データにおいては最も安定した検索精度を出せることが確認できました。
ただし、利用するモデルや文書の性質によって、最適値が変わる点には注意が必要です。
検索手法の比較(ベクトル検索 vs ハイブリッド検索)
単純な意味的類似度に基づくベクトル検索と、キーワードの一致も考慮するハイブリッド検索の精度を比較検証しました。
- 検索機能の違いについて
ベクトル検索:ナレッジベース内のテキストと比較して近い回答を選択する
ハイブリッド検索:全文検索とベクトル検索を同時に実行し、最もマッチする結果を選択する
システムプロンプトは共通とし、アプリを公開。
以下のプロンプトを投稿します。
通報者の保護に関するルールをまとめて教えてください。
ベクトル検索
検索の詳細設定を行わずに抽出した結果です。
社内規程のように「第○条」や専門用語が頻出するドキュメントでは、意味の近さだけを頼るベクトル検索では目的の箇所を見落とすことが少なくありません。

ハイブリッド検索
キーワードマッチングの優先度合いを0.1に設定し、同じプロンプトを投稿した結果です。
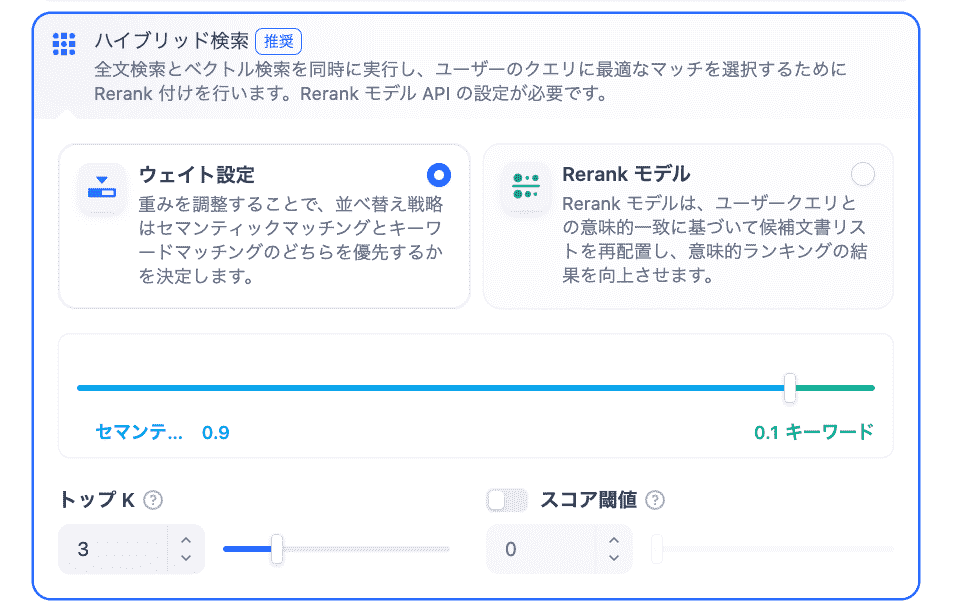
ハイブリッド検索を有効にすることで、キーワードの厳密な一致と文脈的な意味の両面からデータを取得可能に。
出力結果を見比べると、回答の網羅性と正確性が向上した印象を受けます。

意味の近さを重視するならベクトル検索。
条番号・固有用語・定型語句が多い文書ではハイブリッド検索と、状況に応じて使い分けるといいかもしれませんね。
プロンプトによる出力フォーマットの制御検証
検索してきた社内規程の情報を、ユーザーにとって分かりやすく提示するためのプロンプトの工夫について検証しました。
出力形式を固定したり、制約を設けることで情報抽出の精度がどれだけ変化するかを確認します。
最低限の条件のみを設定したプロンプト
シンプルな構成のシステムプロンプトです。
あなたは株式会社サンプルテックの人事・総務・コンプライアンス担当として、社内規程に基づいて社員の質問に回答するアシスタントです。
・回答の根拠は、社内規程(就業規則、テレワーク勤務規程、情報セキュリティ規程、休暇・休職規程、コンプライアンス通報規程など)に基づいてください。
・わからない場合は、「規程上は明記がありません」「追加で担当者への確認が必要です」などと正直に伝えてください。
・社員にとって分かりやすい自然な日本語で回答してください。
ナレッジベースの中から対象の情報を取り出してきていますね。
不明点を勝手に補完したりすることなく、必要な情報のみを出力している印象です。

出力形式を定めたプロンプト
出力フォーマットや制約を固定したプロンプトです。
先述のプロンプト「・」の部分を置き換えた形で設定しています。
〜〜
【出力フォーマット指示】
必ず次のフォーマットで回答してください。
1. 最初に「結論」を1〜3行で簡潔に述べる。
2. 次に「根拠となる規程」を、以下の形式で箇条書きで示す。 ・規程名 第○条 第△項:内容を1〜2行で要約 ・規程名 第○条:内容を1〜2行で要約
3. 最後に「注意点・補足」を箇条書きで整理する(なければ「特になし」と記載)。
【出力フォーマット例】
〜(省略)〜
【制約】
・社内規程外の一般論だけで回答しないでください。
・規程に明記されていない内容を勝手に作成しないでください。
必ずこのフォーマットに従って回答してください。
同じく対象情報を抽出していますが、「どの規定部分から抜き出した情報か」がはっきりとわかるようになっています。
参照元が記載されていることで、念の為の確認作業もスムーズに行えるでしょう。

詳細を設定したシステムプロンプトによって、回答のフォーマットが綺麗に統一され、余計な情報をインプットする必要がなくなりました。
複雑な条件を設定しようと頑張ってもいいですが、シンプルな構成であっても出力形式や条件をしっかりと指定すれば、実務での使い勝手が大きく向上するでしょう。
🏁まとめ
RAGは、AIに自社特有の知識を与え、業務効率を飛躍的に向上させる可能性を秘めた強力な技術です。
しかし、ただ単にAIとデータベースをつなげば完璧な回答が得られるわけではありません。精度の高いシステムを作り上げるには、どのような業務の課題を解決したいのかという目的を明確にし、それに適したLLMやデータベースを選定することが非常に重要です。
情報が古かったり、表記揺れが多かったりするドキュメントでは、いくら優秀なAIでも正しい答えを導き出すことはできません。
RAGの導入を検討する際は、まずは社内のドキュメントを整理し、最新の情報をスムーズにシステムへ連携できるようなデータ管理の仕組みづくりから着手することをおすすめします。
✅Yoomでできること
しかし、RAGをビジネスで本格的に運用するようになると、常に最新の社内データをベクトルデータベースに反映させる仕組みが必要不可欠になります。
Yoomは、自社のナレッジ管理と最先端のAI活用をシームレスに繋ぐプラットフォームとして大きく貢献します。
手作業によるデータの更新漏れを防ぎ、AIが常に最新の情報を参照できる高品質な環境を維持できるようになるのです!
プログラミング不要で自動化フローを構築できるので、気になるテンプレートを見つけて日々の業務に活かしてみてはいかがでしょうか?
■概要Notionに新しい業務データを追加するたび、AIを活用してマニュアル案を作成し、それをGoogle スプレッドシートに転記する作業は、時間と手間がかかるのではないでしょうか。また、手作業による情報の転記は、入力ミスや抜け漏れといったヒューマンエラーの原因にもなり得ます。このワークフローを活用すれば、Notionへのデータ追加をトリガーとして、AIによるマニュアル案の自動生成からGoogle スプレッドシートへのスムーズな追加までを一気通貫で自動化し、これらの課題解決に貢献します。
■このテンプレートをおすすめする方- NotionとGoogle スプレッドシート間で、手作業での情報連携やマニュアル作成に課題を感じている方
- AIを活用して、業務マニュアルのドラフト作成を効率化したいと考えている業務改善担当者の方
- マニュアル作成にかかる時間を短縮し、本来のコア業務に集中したいと考えている方
■このテンプレートを使うメリット- Notionへのデータ追加からAIによるマニュアル案作成、Google スプレッドシートへの記録までが自動化され、これまで手作業に費やしていた時間を短縮することができます。
- 手作業によるマニュアル作成時の記載漏れや、Google スプレッドシートへの転記ミスといったヒューマンエラーの発生リスクを軽減することに繋がります。
■フローボットの流れ- はじめに、NotionとGoogle スプレッドシートをYoomと連携します。
- 次に、トリガーでNotionを選択し、「ページが作成されたら(Webhook)」アクションを設定します。これにより、Notionの指定したデータベースに新しいページが作成されるとフローが起動するようになります。
- 続いて、オペレーションでNotionの「レコードを取得する(ID検索)」アクションを設定し、トリガーで検知した作成されたページの詳細情報を取得します。
- 次に、オペレーションでAI機能の「テキストを生成する」アクションを設定します。ここで、前のステップで取得したNotionの情報を活用し、AIがマニュアル案を生成するように設定します。
- 最後に、オペレーションでGoogle スプレッドシートの「レコードを追加する」アクションを設定し、AIによって生成されたマニュアル案を指定のスプレッドシートの新しい行に自動で追加します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- AI機能の「テキストを生成する」オペレーションでは、マニュアル案を生成するための指示(プロンプト)を任意の内容にカスタムすることが可能です。例えば、特定のフォーマットに基づいたマニュアルを生成させたり、Notionから取得した情報を変数としてプロンプト内に組み込み、より具体的な内容のマニュアル案を作成させたりすることができます。
- Google スプレッドシートの「レコードを追加する」オペレーションでは、出力先となるスプレッドシートのファイルやシートを任意に指定できます。さらに、スプレッドシートのどの列に、AIが生成したテキストのどの部分やNotionから取得した情報を割り当てるか、あるいは固定値を設定するかなど、出力するデータを柔軟にカスタマイズすることが可能です。
■注意事項- Notion、Google スプレッドシートのそれぞれとYoomを連携してください。
■概要Slack上でのやり取りには重要な情報が含まれることも多いですが、情報が流れやすくナレッジとして蓄積しにくいと感じることはないでしょうか。このワークフローは、Slackの特定チャンネルへの投稿をきっかけに、AIエージェント(AIワーカー)が内容を自動で要約・ナレッジ化し、Notionのデータベースへ登録する作業を自動化します。手作業による転記の手間や情報共有の漏れを防ぎ、効率的なナレッジベース管理を実現します。■このテンプレートをおすすめする方- Slack上の議論や決定事項を、手作業でNotionのナレッジベースに転記している方
- AIエージェントを活用して、社内に散在する情報のナレッジベース管理を自動化したいと考えている方
- チーム内の情報共有を円滑にし、ナレッジの属人化を解消したいチームリーダーやマネージャーの方
■このテンプレートを使うメリット- Slackへの投稿後、AIによる要約からNotionへの登録までが自動で実行されるため、ナレッジ化にかかる作業時間を削減できます。
- 手作業による転記ミスや、重要な情報の登録漏れといったヒューマンエラーを防ぎ、ナレッジベースの品質と網羅性を高めます。
■フローボットの流れ- はじめに、NotionとSlackをYoomと連携します。
- 次に、トリガーでSlackを選択し、「メッセージがチャンネルに投稿されたら(Webhook)」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、Slackの投稿内容をナレッジとして整形しNotionに記録するためのマニュアル(指示)を作成します。
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- AIワーカーの設定で、利用したいAIモデルを任意で選択してください。
- AIワーカーへの指示(プロンプト)をカスタマイズし、要約の形式やタイトル付けのルールなどを任意で設定してください。
- Notionの記録先ページも任意で指定してください。
■注意事項- Slack、NotionのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
■概要チーム内に情報が散在し、必要な情報を探すのに時間がかかるといった課題はありませんか。このワークフローを活用すれば、Google Driveに新しいファイルを追加するだけで、AIが自動でドキュメントの内容を解析・分類し、Googleドキュメントを利用して常に最新の情報を反映したスマートナレッジベースを構築することが可能です。手作業による情報整理や通知の手間をなくし、効率的なナレッジマネジメントを実現します。■このテンプレートをおすすめする方- 社内のドキュメント管理が煩雑で、スマートナレッジベースの構築に関心がある方
- チーム内の情報共有を活性化させ、業務効率を改善したいプロジェクトマネージャーの方
- AIを活用して、手作業での情報整理や分類業務、処理後の通知を自動化したいと考えている方
■このテンプレートを使うメリット- Google Driveへのファイル追加だけでAIが内容を解析するため、情報整理の手間を省き、本来注力すべき業務に時間を活用できます
- 情報の分類や蓄積、通知が自動化されるため、作業の属人化を防ぎ、誰でも常に最新のナレッジへアクセスできる環境を整備できます
■フローボットの流れ- はじめに、Discord、Google Drive、GoogleドキュメントをYoomと連携します
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを設定し、アップロードされたドキュメントの解析やナレッジの分類、記録、通知を行うためのマニュアル(指示)を作成します
※「トリガー」:フロー起動のきっかけとなるアクション、「オペレーション」:トリガー起動後、フロー内で処理を行うアクション
■このワークフローのカスタムポイント- Google Driveのトリガー設定では、スマートナレッジベースの構築対象としたいファイルが格納されるフォルダのIDを任意で設定してください
- Googleドキュメントのオペレーションでは、解析結果を追記したいナレッジベース本体のドキュメントIDを任意で設定してください
- AIワーカーの設定では、用途に応じて任意のAIモデルを選択し、ドキュメントの解析や分類方法に関する指示を任意で設定してください
■注意事項- Google Drive、Discord、GoogleドキュメントのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
■このテンプレートをおすすめする方
- NotionとGoogle スプレッドシート間で、手作業での情報連携やマニュアル作成に課題を感じている方
- AIを活用して、業務マニュアルのドラフト作成を効率化したいと考えている業務改善担当者の方
- マニュアル作成にかかる時間を短縮し、本来のコア業務に集中したいと考えている方
■このテンプレートを使うメリット
- Notionへのデータ追加からAIによるマニュアル案作成、Google スプレッドシートへの記録までが自動化され、これまで手作業に費やしていた時間を短縮することができます。
- 手作業によるマニュアル作成時の記載漏れや、Google スプレッドシートへの転記ミスといったヒューマンエラーの発生リスクを軽減することに繋がります。
■フローボットの流れ
- はじめに、NotionとGoogle スプレッドシートをYoomと連携します。
- 次に、トリガーでNotionを選択し、「ページが作成されたら(Webhook)」アクションを設定します。これにより、Notionの指定したデータベースに新しいページが作成されるとフローが起動するようになります。
- 続いて、オペレーションでNotionの「レコードを取得する(ID検索)」アクションを設定し、トリガーで検知した作成されたページの詳細情報を取得します。
- 次に、オペレーションでAI機能の「テキストを生成する」アクションを設定します。ここで、前のステップで取得したNotionの情報を活用し、AIがマニュアル案を生成するように設定します。
- 最後に、オペレーションでGoogle スプレッドシートの「レコードを追加する」アクションを設定し、AIによって生成されたマニュアル案を指定のスプレッドシートの新しい行に自動で追加します。
■このワークフローのカスタムポイント
- AI機能の「テキストを生成する」オペレーションでは、マニュアル案を生成するための指示(プロンプト)を任意の内容にカスタムすることが可能です。例えば、特定のフォーマットに基づいたマニュアルを生成させたり、Notionから取得した情報を変数としてプロンプト内に組み込み、より具体的な内容のマニュアル案を作成させたりすることができます。
- Google スプレッドシートの「レコードを追加する」オペレーションでは、出力先となるスプレッドシートのファイルやシートを任意に指定できます。さらに、スプレッドシートのどの列に、AIが生成したテキストのどの部分やNotionから取得した情報を割り当てるか、あるいは固定値を設定するかなど、出力するデータを柔軟にカスタマイズすることが可能です。
■注意事項
- Notion、Google スプレッドシートのそれぞれとYoomを連携してください。
- Slack上の議論や決定事項を、手作業でNotionのナレッジベースに転記している方
- AIエージェントを活用して、社内に散在する情報のナレッジベース管理を自動化したいと考えている方
- チーム内の情報共有を円滑にし、ナレッジの属人化を解消したいチームリーダーやマネージャーの方
- Slackへの投稿後、AIによる要約からNotionへの登録までが自動で実行されるため、ナレッジ化にかかる作業時間を削減できます。
- 手作業による転記ミスや、重要な情報の登録漏れといったヒューマンエラーを防ぎ、ナレッジベースの品質と網羅性を高めます。
- はじめに、NotionとSlackをYoomと連携します。
- 次に、トリガーでSlackを選択し、「メッセージがチャンネルに投稿されたら(Webhook)」というアクションを設定します。
- 最後に、オペレーションでAIワーカーを選択し、Slackの投稿内容をナレッジとして整形しNotionに記録するためのマニュアル(指示)を作成します。
■このワークフローのカスタムポイント
- AIワーカーの設定で、利用したいAIモデルを任意で選択してください。
- AIワーカーへの指示(プロンプト)をカスタマイズし、要約の形式やタイトル付けのルールなどを任意で設定してください。
- Notionの記録先ページも任意で指定してください。
- Slack、NotionのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- 社内のドキュメント管理が煩雑で、スマートナレッジベースの構築に関心がある方
- チーム内の情報共有を活性化させ、業務効率を改善したいプロジェクトマネージャーの方
- AIを活用して、手作業での情報整理や分類業務、処理後の通知を自動化したいと考えている方
- Google Driveへのファイル追加だけでAIが内容を解析するため、情報整理の手間を省き、本来注力すべき業務に時間を活用できます
- 情報の分類や蓄積、通知が自動化されるため、作業の属人化を防ぎ、誰でも常に最新のナレッジへアクセスできる環境を整備できます
- はじめに、Discord、Google Drive、GoogleドキュメントをYoomと連携します
- 次に、トリガーでGoogle Driveを選択し、「特定のフォルダ内に新しくファイル・フォルダが作成されたら」というアクションを設定します
- 最後に、オペレーションでAIワーカーを設定し、アップロードされたドキュメントの解析やナレッジの分類、記録、通知を行うためのマニュアル(指示)を作成します
■このワークフローのカスタムポイント
- Google Driveのトリガー設定では、スマートナレッジベースの構築対象としたいファイルが格納されるフォルダのIDを任意で設定してください
- Googleドキュメントのオペレーションでは、解析結果を追記したいナレッジベース本体のドキュメントIDを任意で設定してください
- AIワーカーの設定では、用途に応じて任意のAIモデルを選択し、ドキュメントの解析や分類方法に関する指示を任意で設定してください
- Google Drive、Discord、GoogleドキュメントのそれぞれとYoomを連携してください。AIワーカー内で使用するツール(アプリ)についてもマイアプリ連携が必要です。
- AIワーカーの基本設定は「【AIワーカー】基本的な設定方法」をご参照ください。
- AIワーカーの同時実行数・作成可能なAIワーカー数・利用可能なAIモデルはご契約中のプランによって異なります。
- AIワーカー内でご利用いただけるアプリやオペレーション等はフローボットの利用制限と同様です。
- AIワーカーは、テスト実行でも本番実行と同様にタスクを消費しますのでご注意ください。詳細は「【AIワーカー】タスク実行数の計算方法」ご参照ください。
- AIワーカーはマニュアルを詳細に設定することで適切な処理を実行しやすくなります。詳細は「【AIワーカー】マニュアルの作成方法」をご参照ください。
- トリガーは5分、10分、15分、30分、60分の間隔で起動間隔を選択できます。
- プランによって最短の起動間隔が異なりますので、ご注意ください。
- ダウンロード可能なファイル容量は最大300MBまでです。アプリの仕様によっては300MB未満になる可能性があるので、ご注意ください。
- トリガー、各オペレーションでの取り扱い可能なファイル容量の詳細は「ファイルの容量制限について」をご参照ください。
出典:
プログラミング知識なしで手軽に構築できます。